Javascript执行机制(七)如何快速查找对象上的属性
上一篇博客我们讲了V8的整体执行的流程,这次我就继续总结下,V8是如何实现对象上属性的快速查找的。
注意,这部分内容不是作用域链,也不是原型链。作用域链是用来找到对象的,如obj,原型链是如果obj上没有属性a,去它的原型上找,而本文的主题,是如何快速在obj上找到a。
快属性和慢属性
JavaScript 中的对象是由一组组属性和值的集合,从 JavaScript 语言的角度来看,JavaScript 对象像一个字典,字符串作为键名,任意对象可以作为键值,可以通过键名读写键值。
然而在 V8 实现对象存储时,并没有完全采用字典的存储方式,这主要是出于性能的考量。因为字典是非线性的数据结构,查询效率会低于线性的数据结构,V8 为了提升存储和查找效率,采用了一套复杂的存储策略。
常规属性和排序属性
1 |
|
在上面这段代码中,我们利用构造函数 Foo 创建了一个 bar 对象,在构造函数中,我们给 bar 对象设置了很多属性,包括了数字属性和字符串属性,然后我们枚举出来了 bar 对象中所有的属性,并将其一一打印出来,下面就是执行这段代码所打印出来的结果:
1 |
|
观察这段打印出来的数据,我们发现打印出来的属性顺序并不是我们设置的顺序,我们设置属性的时候是乱序设置的,比如开始先设置 100,然后又设置了 1,但是输出的内容却非常规律,总的来说体现在以下两点:
设置的数字属性被最先打印出来了,并且是按照数字大小的顺序打印的;
设置的字符串属性依然是按照之前的设置顺序打印的,比如我们是按照 B、A、C 的顺序设置的,打印出来依然是这个顺序。
之所以出现这样的结果,是因为在 ECMAScript 规范中定义了数字属性应该按照索引值大小升序排列,字符串属性根据创建时的顺序升序排列。在这里我们把对象中的数字属性称为排序属性,在 V8 中被称为 elements,字符串属性就被称为常规属性,在 V8 中被称为 properties。
在 V8 内部,为了有效地提升存储和访问这两种属性的性能,分别使用了两个线性数据结构来分别保存排序属性和常规属性,具体结构如下图所示:

通过上图我们可以发现,bar 对象包含了两个隐藏属性:elements 属性和 properties 属性,elements 属性指向了 elements 对象,在 elements 对象中,会按照顺序存放排序属性,properties 属性则指向了 properties 对象,在 properties 对象中,会按照创建时的顺序保存了常规属性。
分解成这两种线性数据结构之后,如果执行索引操作,那么 V8 会先从 elements 属性中按照顺序读取所有的元素,然后再在 properties 属性中读取所有的元素,这样就完成一次索引操作。
快慢属性
将不同的属性分别保存到 elements 属性和 properties 属性中,无疑简化了程序的复杂度,但是在查找元素时,却多了一步操作,比如执行 bar.B这个语句来查找 B 的属性值,那么在 V8 会先查找出 properties 属性所指向的对象 properties,然后再在 properties 对象中查找 B 属性,这种方式在查找过程中增加了一步操作,因此会影响到元素的查找效率。
基于这个原因,V8 采取了一个权衡的策略以加快查找属性的效率,这个策略是将部分常规属性直接存储到对象本身,我们把这称为对象内属性 (in-object properties)。对象在内存中的展现形式你可以参看下图:

采用对象内属性之后,常规属性就被保存到 bar 对象本身了,这样当再次使用bar.B来查找 B 的属性值时,V8 就可以直接从 bar 对象本身去获取该值就可以了,这种方式减少查找属性值的步骤,增加了查找效率。
不过对象内属性的数量是固定的,默认是 10 个,如果添加的属性超出了对象分配的空间,则它们将被保存在常规属性存储中。虽然属性存储多了一层间接层,但可以自由地扩容。
通常,我们将保存在线性数据结构中的属性称之为“快属性”,因为线性数据结构中只需要通过索引即可以访问到属性,虽然访问线性结构的速度快,但是如果从线性结构中添加或者删除大量的属性时,则执行效率会非常低,这主要因为会产生大量时间和内存开销。
因此,如果一个对象的属性过多时,V8 就会采取另外一种存储策略,那就是“慢属性”策略,但慢属性的对象内部会有独立的非线性数据结构 (词典) 作为属性存储容器。所有的属性元信息不再是线性存储的,而是直接保存在属性字典中。

举例说明
1 |
|
我们可以在浏览器控制台运行这段代码,然后利用Memory的快照功能看看这三个对象中的属性。
首先是第一个,可以看到所有的排序属性都在elements中,而常规属性都直接在对象上,没有在properties上

然后是第二个,对象上有了properties属性,内部有10个根据键排序的常规属性。

最后就是第三个,我们可以看到,此时的properties中的属性已经是乱序的了,是个map

隐藏类
在上一部分讲快慢属性的时候,chrome的快照中,还有一个属性,叫做map,也叫作隐藏类,那这个map是做什么的呢?
我们知道 JavaScript 是一门动态语言,其执行效率要低于静态语言,V8 为了提升 JavaScript 的执行速度,借鉴了很多静态语言的特性,比如实现了 JIT 机制,为了提升对象的属性访问速度而引入了隐藏类,为了加速运算而引入了内联缓存。今天我们来重点分析下 V8 中的隐藏类,看看它是怎么提升访问对象属性值速度的。
为什么静态语言的效率更高?
由于隐藏类借鉴了部分静态语言的特性,因此要解释清楚这个问题,我们就先来分析下为什么静态语言比动态语言的执行效率更高。
我们通过下面两段代码,来对比一下动态语言和静态语言在运行时的一些特征,一段是动态语言的 JavaScript,另外一段静态语言的 C++ 的源码,具体源码你可以参看下图:

那么在运行时,这两段代码的执行过程有什么区别呢?
我们知道,JavaScript 在运行时,对象的属性是可以被修改的,所以当 V8 使用了一个对象时,比如使用了 start.x 的时候,它并不知道该对象中是否有 x,也不知道 x 相对于对象的偏移量是多少,也可以说 V8 并不知道该对象的具体的形状。
那么,当在 JavaScript 中要查询对象 start 中的 x 属性时,V8 会按照具体的规则一步一步来查询,这个过程非常的慢且耗时
这种动态查询对象属性的方式和 C++ 这种静态语言不同,C++ 在声明一个对象之前需要定义该对象的结构,我们也可以称为形状,比如 Point 结构体就是一种形状,我们可以使用这个形状来定义具体的对象。C++ 代码在执行之前需要先被编译,编译的时候,每个对象的形状都是固定的,也就是说,在代码的执行过程中,Point 的形状是无法被改变的。那么在 C++ 中访问一个对象的属性时,自然就知道该属性相对于该对象地址的偏移值了,比如在 C++ 中使用 start.x 的时候,编译器会直接将 x 相对于 start 的地址写进汇编指令中,那么当使用了对象 start 中的 x 属性时,CPU 就可以直接去内存地址中取出该内容即可,没有任何中间的查找环节。因为静态语言中,可以直接通过偏移量查询来查询对象的属性值,这也就是静态语言的执行效率高的一个原因。
什么是隐藏类 (Hidden Class)?
既然静态语言的查询效率这么高,那么是否能将这种静态的特性引入到 V8 中呢?
答案是可行的。目前所采用的一个思路就是将 JavaScript 中的对象静态化,也就是 V8 在运行 JavaScript 的过程中,会假设 JavaScript 中的对象是静态的,具体地讲,V8 对每个对象做如下两点假设:
对象创建好了之后就不会添加新的属性;
对象创建好了之后也不会删除属性。
符合这两个假设之后,V8 就可以对 JavaScript 中的对象做深度优化了,那么怎么优化呢?
具体地讲,V8 会为每个对象创建一个隐藏类,对象的隐藏类中记录了该对象一些基础的布局信息,包括以下两点:
对象中所包含的所有的属性;
每个属性相对于对象的偏移量。
有了隐藏类之后,那么当 V8 访问某个对象中的某个属性时,就会先去隐藏类中查找该属性相对于它的对象的偏移量,有了偏移量和属性类型,V8 就可以直接去内存中取出对于的属性值,而不需要经历一系列的查找过程,那么这就大大提升了 V8 查找对象的效率。
1 | let point = {x:100,y:200} |
隐藏类描述了对象的属性布局,它主要包括了属性名称和每个属性所对应的偏移量,比如 point 对象的隐藏类就包括了 x 和 y 属性,x 的偏移量是 4,y 的偏移量是 8。
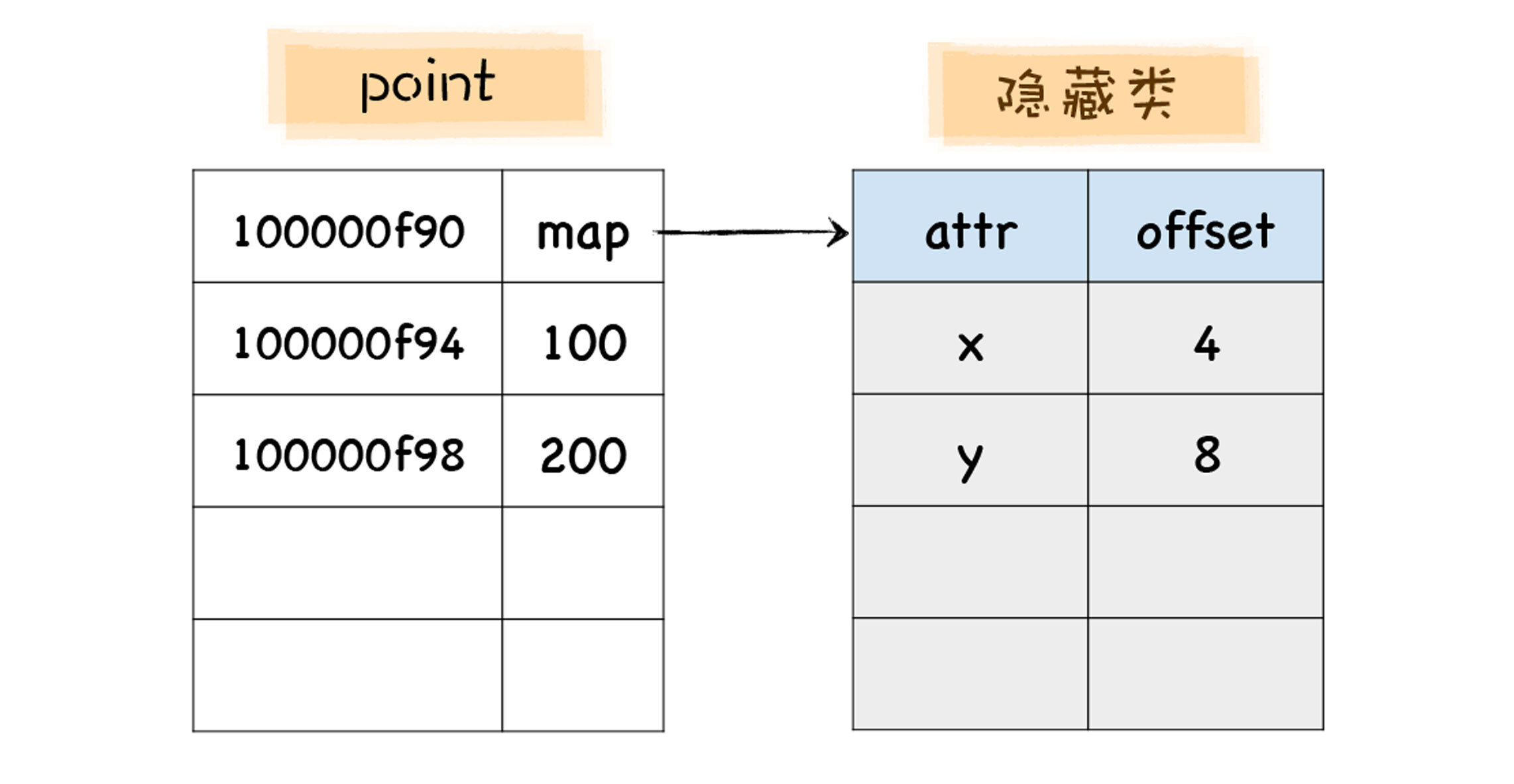
有了 map 之后,当你再次使用 point.x 访问 x 属性时,V8 会查询 point 的 map 中 x 属性相对 point 对象的偏移量,然后将 point 对象的起始位置加上偏移量,就得到了 x 属性的值在内存中的位置,有了这个位置也就拿到了 x 的值,这样我们就省去了一个比较复杂的查找过程。
多个对象共用一个隐藏类现在我们知道了在 V8 中,每个对象都有一个 map 属性,该属性值指向该对象的隐藏类。
不过如果两个对象的形状是相同的,V8 就会为其复用同一个隐藏类,这样有两个好处:
减少隐藏类的创建次数,也间接加速了代码的执行速度;
减少了隐藏类的存储空间。
那么,什么情况下两个对象的形状是相同的,要满足以下两点:
相同的属性名称;
相等的属性个数。
重新构建隐藏类
关于隐藏类,还有一个问题你需要注意一下。在这节课开头我们提到了,V8 为了实现隐藏类,需要两个假设条件:
对象创建好了之后就不会添加新的属性;
对象创建好了之后也不会删除属性。
但是,JavaScript 依然是动态语言,在执行过程中,对象的形状是可以被改变的,如果某个对象的形状改变了,隐藏类也会随着改变,这意味着 V8 要为新改变的对象重新构建新的隐藏类,这对于 V8 的执行效率来说,是一笔大的开销。通俗地理解,给一个对象添加新的属性,删除新的属性,或者改变某个属性的数据类型都会改变这个对象的形状,那么势必也就会触发 V8 为改变形状后的对象重建新的隐藏类。
最佳实践
好了,现在我们知道了 V8 会为每个对象分配一个隐藏类,在执行过程中:
如果对象的形状没有发生改变,那么该对象就会一直使用该隐藏类;
如果对象的形状发生了改变,那么 V8 会重建一个新的隐藏类给该对象。
我们当然希望对象中的隐藏类不要随便被改变,因为这样会触发 V8 重构该对象的隐藏类,直接影响到了程序的执行性能。那么在实际工作中,我们应该尽量注意以下几点:
使用字面量初始化对象时,要保证属性的顺序是一致的
尽量使用字面量一次性初始化完整对象属性
尽量避免使用 delete 方法
内联缓存
首先看一段代码
1 |
|
通常 V8 获取 o.x 的流程是这样的:查找对象 o 的隐藏类,再通过隐藏类查找 x 属性偏移量,然后根据偏移量获取属性值,在这段代码中 loadX 函数会被反复执行,那么获取 o.x 流程也需要反复被执行。我们有没有办法再度简化这个查找过程,最好能一步到位查找到 x 的属性值呢?答案是,有的。
其实这是一个关于内联缓存的思考题。我们可以看到,函数 loadX 在一个 for 循环里面被重复执行了很多次,因此 V8 会想尽一切办法来压缩这个查找过程,以提升对象的查找效率。这个加速函数执行的策略就是内联缓存 (Inline Cache),简称为 IC。
什么是内联缓存
要回答这个问题,我们需要知道 IC 的工作原理。其实 IC 的原理很简单,直观地理解,就是在 V8 执行函数的过程中,会观察函数中一些调用点 (CallSite) 上的关键的中间数据,然后将这些数据缓存起来,当下次再次执行该函数的时候,V8 就可以直接利用这些中间数据,节省了再次获取这些数据的过程,因此 V8 利用 IC,可以有效提升一些重复代码的执行效率。
IC 会为每个函数维护一个反馈向量 (FeedBack Vector),反馈向量记录了函数在执行过程中的一些关键的中间数据。关于函数和反馈向量的关系你可以参看下图:

反馈向量其实就是一个表结构,它由很多项组成的,每一项称为一个插槽 (Slot),V8 会依次将执行 loadX 函数的中间数据写入到反馈向量的插槽中。比如下面这段函数:
1 | function loadX(o) { |
当 V8 执行这段函数的时候,它会判断 o.y = 4 和 return o.x 这两段是调用点 (CallSite),因为它们使用了对象和属性,那么 V8 会在 loadX 函数的反馈向量中为每个调用点分配一个插槽。每个插槽中包括了插槽的索引 (slot index)、插槽的类型 (type)、插槽的状态 (state)、隐藏类 (map) 的地址、还有属性的偏移量,比如上面这个函数中的两个调用点都使用了对象 o,那么反馈向量两个插槽中的 map 属性也都是指向同一个隐藏类的,因此这两个插槽的 map 地址是一样的。
多态和超态
好了,通过缓存执行过程中的基础信息,就能够提升下次执行函数时的效率,但是这有一个前提,那就是多次执行时,对象的形状是固定的,如果对象的形状不是固定的,那 V8 会怎么处理呢?我们调整一下上面这段 loadX 函数的代码,调整后的代码如下所示:
1 |
|
第一次执行时 loadX 时,V8 会将 o 的隐藏类记录在反馈向量中,并记录属性 x 的偏移量。那么当再次调用 loadX 函数时,V8 会取出反馈向量中记录的隐藏类,并和新的 o1 的隐藏类进行比较,发现不是一个隐藏类,那么此时 V8 就无法使用反馈向量中记录的偏移量信息了。面对这种情况,V8 会选择将新的隐藏类也记录在反馈向量中,同时记录属性值的偏移量,这时,反馈向量中的第一个槽里就包含了两个隐藏类和偏移量。
现在我们知道了,一个反馈向量的一个插槽中可以包含多个隐藏类的信息,那么:
如果一个插槽中只包含 1 个隐藏类,那么我们称这种状态为单态 (monomorphic);
如果一个插槽中包含了 2~4 个隐藏类,那我们称这种状态为多态 (polymorphic);
如果一个插槽中超过 4 个隐藏类,那我们称这种状态为超态 (magamorphic)。
总的来说,我们只需要记住一条就足够了,那就是单态的性能优于多态和超态,所以我们需要稍微避免多态和超态的情况。