机器智能的本质——分类与组合
计算机虽然最初是用于科学计算的,但是很快他处理的对象就涵盖了世界上的所有东西,有具体的,比如人,动物和物品,也有抽象的,比如加法,函数等。对于这些东西,无论是抽象的还是具体的,大部分操作其实不是计算,而是分类,组织,查找和重组。因此很多应用科学将实际问题变成了信息处理的分类,组织,查找和重组,而计算机的算法再把这些信息处理问题变为计算问题。显然,这里有两个桥梁,我们这次就围绕这两个桥梁展开。
这是选择分类问题
我们先从计算机下棋说起,无论是下象棋还是下围棋,从本质上讲都是一个N选1的问题,对于下围棋来说,每走完一步,我们接下来都有N种选择,每个选择都是树中下一级节点。接下来再走一步,还有N种选择。将所有可能性放到一个图中,就会形成一个N叉树。
由于对弈双方是轮流进行选择的,因此在这个N叉树种,一方有奇数层选择权,而一方有偶数层的选择权,选择权不断交替,这种树被称为博弈树。将下棋这件事变成上述的N叉树,就是一开始说的建立起了实际问题和信息处理之间的桥梁,至于N选1的时候应该怎么选,那就是算法的问题了。
将实际的问题对应到一个数据结构,然后在数据结构的基础上实现算法,当然也可以为了提高算法性能,适当调整数据结构的细节。选择数据结构的时候最好能够选择一个能更好表达其逻辑的机构,不仅有利于设计算法,也有利于提高算法性能,比如这个下棋问题,如果选择栈作为数据结构,不仅难理解,算法性能也不会高
计算机下棋是一个定义及其明确,边界非常清楚的N选1问题。在人工智能领域还有很多N选1问题的边界就没那么清楚了,他们更准确地讲师模式分类问题,比如语音识别,手写体和印刷体文字识别,以及医学影像或人脸识别等,甚至计算机自动翻译人类的语言也属于这一类问题。
下面我们就以汉字的识别来说明这一类智能问题与分类问题之间的对应关系。为了让读者有形象的认识,我们省去笔画的影响,只关注字的形状,需要指出的是,实际的手写字识别中,笔画是很重要的.
如图所示,是一些很相似的手写字

所谓的手写字识别,就是把上述的不同写法归类,在实际的应用中,各种各样的写法不是很容易识别。利用计算机识别这些字,其实就是根绝各个字之间的差异,将他们分类到不同的类别中。那些能够帮助分类的差异,可以被认为是一个很多维度中的变量。
为了更加直观地说明这一点,我们就把上面例子中的“田”“由”“甲”“申”相似的字进一步简化,变为二维空间中的一些点,在这两个维度中,一个表示中间一竖向上出头的长度,另一个表示中间一竖方向,那么这四个字再而二维空间中的位置表示就如图所示:
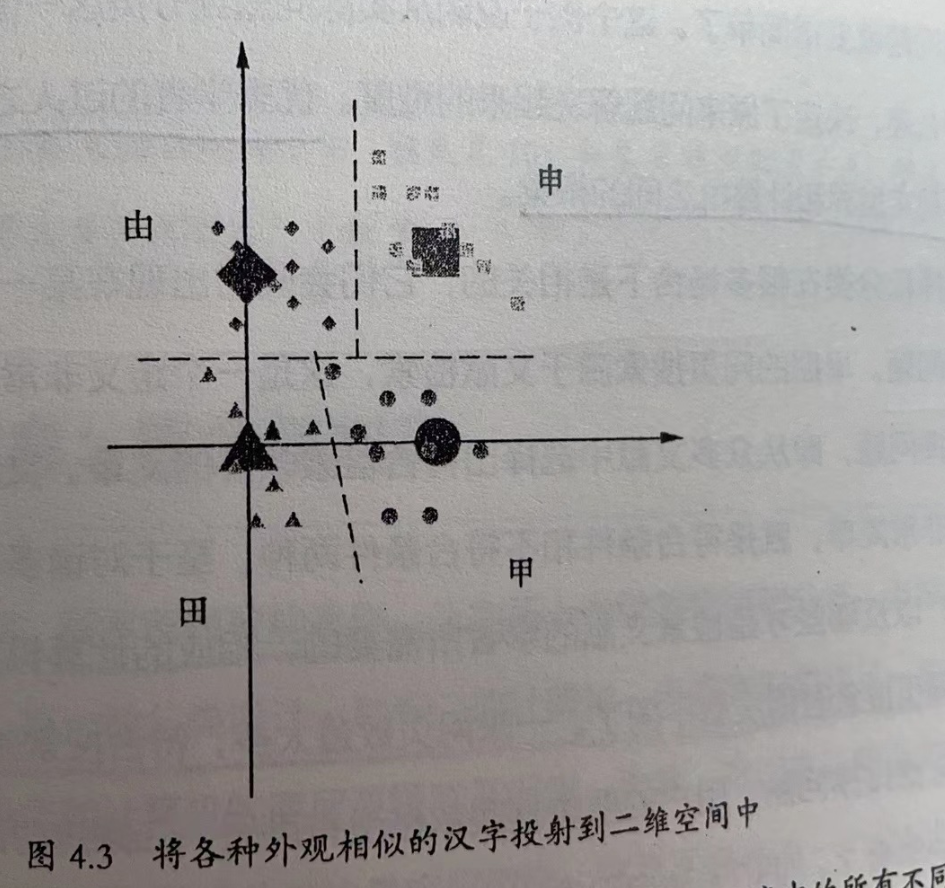
所谓模式识别,就是在多维空间中划出不同区域,在某个区域中所有不同写法,都被认定为某个字。
当然,要分的类别越多,准确分类的难度就越大,总的来说,语音识别比文字识别难,而人脸识别比语音识别难。
对于难度更高的人脸识别,其实我们通常在应用中重新定义问题,把一个上万类的分类问题变为一个两类的分类问题————“是证件上这个人,还是其他人”
组织信息:集合与判定
前面说过,很多所谓的智能操作,本质上讲就是选择和分类。当然我们不可能为每一种选择,每一种每类设计一种专门的计算机,于是我们需要另一个桥梁把他们中间最基本的操作和计算机的底层逻辑联系起来。为此,我们从集合说起。
集合是对世界上的万物进行分类的最底层逻辑,它甚至很难有一个明确的定义,在计算机领域,经常要用到集合的三个基本性质。
首先,给定一个事物,能够判断它是否属于某个集合,不允许有既属于某个集合,又不属于该集合的情况发生
其次,如果两个集合相同,则集合中的所有元素相同。
最后,集合中不能有重复元素,但是没有次序
二叉决策树
由于对于某一个事物是否属于某个集合的判定结果是二值的,这就和我们前面提到的二分法或者二进制有着天然的联系了。无论是在计算机还是在信息论中,二分法都有着非常重要的地位。建立在“是”和“非”这种二值逻辑基础上的开关电路可以实现计算机的任何计算。当然,只要能说出集合的特性,比如“大于零的整数”,我们就可以很容易使用一课二叉树,将所有元素判定到这个集合中,或者集合外。这样一来,对于是非的判断就等价于一种二选一的分类了,我们可以用一个二叉树来表示这种分类的逻辑。
二叉树是一种非常有效的信息组织方式,其有效性至少有如下三个:
- 操作简单。给定一个判断条件,任何元素来了以后就可以放在左边或者右边,查找的时候,可以根据判定条件,要么去左边找,要么去右边找
- 能够非常高效地表达大量的事物
- 二叉决策树和它的任意子树具有相同的形式,只要实现任意一个局部操作,即可扩展到所有情况。
二分这个概念,以及和它对应的二叉树,对于计算机科学的重要性,犹如质量和长度对于物理。
哈希表
我们前面也讲了,不是每个集合的特征都是明确的,甚至并非每个集合都有特征,当一个集合特征不明显的时候,就无法用决策树进行判定了。但是如果一个集合内的所有元素都可以枚举出来,我们其实是很清楚这个集合包括了哪些元素的,这些元素之外的集合都不属于相应的集合。
而哈希表则是构建这一类集合的有效存储方式。
对于枚举的方式划定集合边界,很多人可能会提出一个疑问,类似哈希表这样的存储结构是否要占用太多的内存空间。这确实是一个值得思考的问题,我们以屏蔽某些网站为例子。
我们有三种方法解决这个问题:
- 直接存储整个哈希表,不论它需要占据多少空间,随着计算机性能的不断提升,这种以机器成本换取开发成本的方式在非商业领域很常见。
- 布隆过滤器,感兴趣的可以看我的另一篇博客:布隆过滤器
- 二分决策和哈希表结合。先用简单的规则分类,对于规则无法涵盖的情况再放到一个预先设定的好的集合中专门处理,这种方法带来的效率提升是很明显的,因为例外的情况是少数。
对比二叉决策树和哈希表两种情况,他们除了结构不同,其实在对待所要处理的对象的思路也不同。前者需要的是对所关注集合提炼出一个概念,比如整数,后者则是划分一个集合的边界。
人们在处理信息的时候,从本质上讲思维方式属于前者,人们会通过样本提炼出概念,然后把概念应用到所有地方,判定元素和集合的关系。而计算机,或者说人工智能,思维方式是后者,通过机器学习划分一条边界,说明哪些情况在边界内,哪些在边界外,但是它们没法提炼概念
B+树,B*树,数据库的组织方式
在计算机中,为了方便数据的查找和定位,任何事物通常都会被描述成一对由键和值构成的二元组,在一个系统的内部,键是唯一的,不能重复的,键一旦确定,值就确定了。任何事物的键都很小,能比较,而描述它们的值可能很大
这里键的设定和比较可以考虑和之前讲编码的博客相结合
树的结构有很多超出人想象的神奇之处,比如二分的直接结果就是一层层将世界上的事物分门别类,每一类可以看成一类集合,在层层分类之后,同一个集合内部的各个元素之间,不同集合之间的关系就一目了然了。
但是对于很多问题,如果真的能够直接采用N叉树,会比进行多次二分更有效,比如读音和单词的对应,直接采用26叉树更好,逻辑也更加清晰。因此在一定的场合,我们直接采用N叉树。当然不受限制的N叉树使用起来非常麻烦,一旦某个节点分叉太多,效率甚至可能退化为线性复杂度,所以我们提出了B树
关于B树的定义可以直接看这篇博客:https://zhuanlan.zhihu.com/p/146252512
在计算机中,使用比较多的是B树的变种,B+树,其改进的点在于:
- 所有非叶子节点只保留键,它们的作用是确定子节点中关键值的区间,所有内容都必须保留在叶子节点中
- 用一个指针将叶子节点从头到尾串起来
B+树的优点有两个,一个是结构干净,另一个则是通过叶节点指针,将所有数值排序整理还,便于一次访问大量数据,这里有点像跳表的思路。
这里我们可以思考如何用一个B+树存储整个英文字典
如果使用二叉树,我们可以使用5次二分为26个字母建立起一棵二叉树,然后通过五次查找找到第一个字母,再类似的往下一个个字母找,这个方法的一个问题是,像E,S,T这种字母出现频率很高,而J,X,Z等出现频率低,这个二叉树很不平衡,找起来效率低
而使用26叉树,每个二叉树要预留26个子节点位置,这样层数会少,但是大部分位置会浪费,此时我们就可以使用B+树了
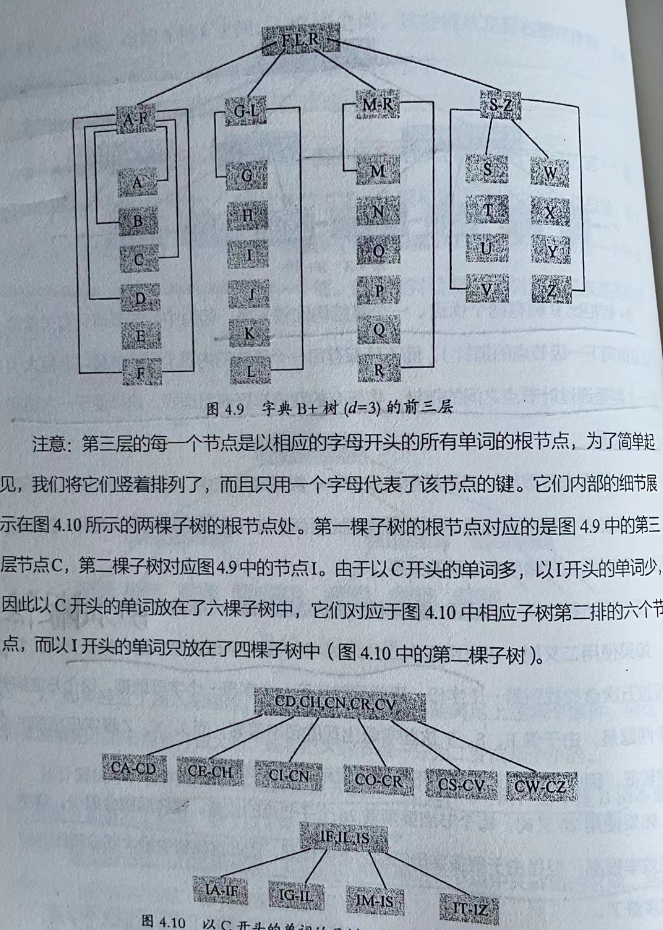
B* 树就是在B+树的基础上在非叶子节点之间增加了指向兄弟节点的指针,此外,B* 树对合并小节点以及分割大节点的机制做了调整
这里别忘了,能够用树处理的是集合有定义的情况,当集合没有定义,只能枚举的时候,还是要使用哈希表