Operating System Learning Notes (5) Fundamentals of File Management System
Read with two questions
- What is a file? What is a file system?
- What functions does the file system need to complete?
Pay attention to distinguish the logical structure and physical structure of the file, do not confuse the two.
Document concept
Definition of document
File is an important concept in the operating system. A file is a collection of information stored on a computer based on a computer hard disk. The file can be a text document, a picture, a program, etc.
When the system is running, the computer schedules and allocates resources based on the process; while in the input and output of the user, the file is the basic unit
The input of most applications is achieved through files, and their output is also saved in files for long-term storage of information and future access. When users use files for input and output of applications, they also hope to access files, modify files, save files, etc., to achieve maintenance and management of files. This requires the system to provide a file management system. The file system in the operating system is used to achieve these management requirements of users.
To clearly understand the concept of a document, it is necessary to understand what exactly a document consists of:
First of all, there is a piece of storage space, more precisely, the data in the storage space.
- Secondly, since the operating system has to manage thousands of data, it must be divided into these data for classification and indexing, so the file must contain classification and indexing information.
- Finally, different users have different access rights to the data, so the file must contain some information about access rights.
Users create files through the file system, provide input and output of the application, and manage resources. First, understand the structure of the file, and we define it by bottom-up approach:
- Data items. Data items are the lowest level of data organization in a file system and can be divided into two types:
- Basic data item. A value used to describe a certain attribute of an object, such as name, date, or document number, is the smallest logical data unit that can be named in the data, that is, atomic data.
- Combination of data items. Consists of multiple basic data items.
- Record. A record is a collection of related data items used to describe the properties of an object in a certain aspect, such as a candidate’s registration record, including a candidate’s name, date of birth, school code, ID number and other fields.
- File. A file is a collection of related information defined by the creator, which can be logically divided into structured files and unstructured files
Properties of the file
Files have certain attributes, which vary from system to system, but usually include the following attributes:
- ** Name **. The file name is unique and saved in an easy-to-read form.
- Identifier. A unique label, usually a number, that identifies a file within a file system, an internal name that is unreadable to humans.
- ** Type **. Used by different types of file systems.
- ** Location **. Refers to the device and the pointer to the file on the device.
- ** Size **. The current size of the file (expressed in bytes, words, or blocks), which can also include the maximum allowed for the file.
- ** Protection **. Access control information that protects files.
- ** Time **, date and user ID. Information about file creation, last modification and last access, used to protect and track file usage.
All file information is saved in the directory structure, and the directory structure is saved on external storage.
File information is only brought into memory on request. Typically, directory entries include the file name and its unique identifier, which locates information about other attributes.
Basic operation of file
Files belong to abstract data types. In order to properly define files, operations related to them need to be considered. The operating system provides system calls that perform operations such as creating, writing, reading, relocating, deleting, and truncating files.
- Create a file. There are two necessary steps to create a file: one is to find space for the file in the file system, and the other is to create an entry for the new file in the directory, which records the file name, location in the file system, and possibly other information.
- Write to a file. To write to a file, execute a system call specifying the file name and the contents to be written to the file. For a given file name, the system searches the directory for the file location. The system must maintain a pointer to the write location for the file (is it saved for every process that writes to the file?) so that whenever a write operation occurs, the write pointer is updated.
- Read the file. In order to read the file, execute a system call specifying the file name and the memory location of the file block to be read into. It is also necessary to search the directory to find the relevant directory entry, and the system maintains a pointer to the read location. Whenever a read operation occurs, update the read pointer. A process usually only reads or writes to one file, so the current operation location can be used as a pointer to the current file location of each process, that is, the read and write pointers can be the same for the same process.
- File relocation (file addressing). Search the directory according to a certain condition, set the current file location to a given value, and do not read or write files.
- Delete files. First find the directory entry of the file to be deleted from the directory, make it an empty entry, and then reclaim the storage space occupied by the file.
- Truncate the file. Allow all attributes of the file to remain unchanged, and delete the content of the file, that is, set its length to 0.
These six basic operations can be combined to perform other file operations, such as copying a file, creating a new file, then reading from the old file and writing to the new file.
The following can be combined here目录结构的所需要操作Understand the operation of the file system as a whole
Opening and closing of files
Because many file operations involve searching for the relevant directory entry for a given file, many systems require that the attributes of the specified file (including the physical location of the file on external memory) be copied from external memory to external memory using the system call open on the first use of the file. In the entry of an open file table in memory, the entry number (also called index) of the table is returned to the user.
The operating system maintains a table of information about all open files (open-file table).
When a user needs to operate a file, the index can be found directly from the Open File table, saving the search process.
Most operating systems require files to be explicitly opened before use
The operation open searches the directory based on the file name and copies the directory entry to the Open Files table.
If the open request is allowed, the process can open the file, and open usually returns a pointer to an entry in the open file table.
I/O operations are performed by using the pointer instead of the file name.
The open instruction searches for the directory through the file name. After finding the corresponding directory entry, it returns the index to the process and stores it in the open file table. After opening, the operating system no longer uses the file name to operate.
The entire system table contains process-related information, such as file location on disk, access date, and size.
The first time a file is opened by a process, the system open table will increase an entry, when another process performs open, is to increase an entry in its own process open table, and then point to the corresponding entry of the system open table, At the same time, the counter in the corresponding entry of the system open table is incremented by one to indicate how many processes have opened the file.
Each close operation will deduct the counter by one. When the counter is 0, it means that the file is no longer in use. The system will recover the memory resources allocated to the file. If the file has been modified, the file will be written back to external memory (this step is a bit similar to missing page replacement. If the modification bit is 1, the page content needs to be written back to the hard disk), and the corresponding entry in the system open table is deleted, and finally the file control block (File Control Block, FCB) is released.
What are the similarities and differences between FCB, directory entry, and system open table entry?
Each open file has the following associated information:
- ** File pointer. ** The system tracks the last read and write location as a pointer to the current file location. This pointer is unique to a process that opens the file, that is, it is process-level, so it must be stored separately from the properties of the disk file itself.
- ** File open count **. When a file is closed, the operating system must reuse its open file table entry, otherwise the space in the table will gradually shrink. And because multiple processes may open the same file, the system must wait for the last process to close the file before deleting the open file entry. It is achieved through the counter. When the count is 0, close the file and delete the entry. This is file-level.
- ** File disk location **. Most file operations require the system to modify file data. This information is stored in memory.
This thing should be in the system open table, but another question, if it is a continuous file storage, in the process of writing, the file size exceeded, what will happen?
Is it to reapply for disk space, then copy it and modify the location? Or do you not allow writing more than the file size.
- ** Access permissions **. Each process needs an access mode (create/read-only/read-write/add, etc.). This information is process-level, so it should be stored in the process open table.
Logical structure of the file (internal logical structure of the file)
The logical structure of the file is the organization of the file as seen from the user’s point of view.
The physical structure of the file is the storage organization form of the file stored in the external memory from the perspective of implementation.
The logical structure of the file has nothing to do with the nature of the storage medium, but the physical structure of the file has a great relationship with the characteristics of the storage medium.
This is like a linked list in a data structure, which can be either sequential or chained storage
Unable to paste block outside Docs
Unstructured file
The simplest form of file organization organizes and accumulates data in order between cities. It is an ordered collection of related information items in bytes. Because there is no structure, all access can only be in the form of exhaustive search, so this form is not suitable for most files, but is more suitable for files with few basic information unit operations
Structured file
According to the organization of records, it can be divided into:
Sequential files (organized in order)
The records in the file are arranged sequentially one after the other. The records are usually of fixed length and can be stored sequentially or in the form of a linked list. When accessing, it is necessary to search the file sequentially.
The sequential file has the following two structures:
- The first is a string structure, the order between records has nothing to do with the order of keywords, usually the method is determined by the time, that is, sorted according to the order of the stored time.
- The second is the sequential structure, which means that all records in the file are arranged in keyword order.
When performing batch operations on records, that is, each time a large number of records are to be read, the efficiency of sequential files is the highest among all logical files; only sequential files can be stored on magnetic tape.
The advantage of sequential files is batch operation, whether it is sequential storage or chain storage. It is more difficult to add, delete, check and modify a single record, which is what index files are good at.
Index file (organized by index)
For a fixed-length record file, to find the i-th record, you can directly calculate the address of the i-th record relative to the first record according to the following formula: Ai = i * L;
Fixed-length record files need to be stored in order to be calculated in this way, but it should be noted that sequential storage does not mean sequential files. The definition of sequential files is to organize records in order, and the definition of index files is to organize by index. It is the difference between the two.
However, for variable length record file, to find the i-th record, we must sequentially find the first data i-1, so as to obtain the length L of the corresponding data, and then continuously add to obtain the first address of the i-th record.
Variable-length record files can only be searched in order, and the system overhead is large, so an index table can be established to speed up the retrieval speed. The index table itself is a sequential file of fixed-length records.
Index sequential files (organize indexes in order)
Indexed sequential files are a combination of sequential and indexed organizational forms.
Indexed sequential file file all records into several groups, to establish an index table for the sequential file, to establish an index entry for the first record in each group in the index table, which contains the record keyword and points to the record pointer.
The records in the main file are arranged in groups, and the keywords in the same group can be out of order, but the keywords between groups must be ordered.
Direct file or hash file (without any sequential characteristics)
The key value of a given record or the key value converted by the hash function directly determines the physical location of the record. This mapping structure is different from sequential files or index files, and has no sequential characteristics.
The hash file is the same as the hash table in the data structure, which will also generate hash conflicts and need to be processed.
Here is a summary comparison of these structured files.
First, understand the first point, sequential storage or chain storage, fixed-length records or variable-length records, and it has nothing to do with which category of structured files it belongs to.
Sequential file means that the records in the file are in order. When searching, it is searched in order.
Index file refers to the file having an index, which can be implicit due to sequential storage (similar to array index) or a separate index table. When searching, it is searched by index.
The index sequential file is, and the index is sequential. Find the index in order first, and then use the index to find it.
The hash file directly calculates the physical location of the record through the hash function, and there is no order in it.
Directory structure (external logical structure of files)
Associated with file management systems and file collections is the file directory, which contains information about files, such as attributes, locations, and ownership, which is mainly managed by the operating system.
Basic requirements for directory management:
- From the user’s point of view, the directory needs to provide a mapping between the file name and file required by the user, so the directory management needs to implement “name access”.
The efficiency of directory access directly affects the performance of the system, so it is necessary to improve the retrieval speed of the directory.
In a shared system, directories also need to provide information for controlling access to files. - It is also a reasonable and inevitable requirement for users to allow duplicate names in files. Directory management is solved and realized through tree structure.
File control blocks and index nodes
** File Control Block (FCB) **
The file control block is a data structure used to store various information required to control the file to achieve “name access”. The ordered collection of FCBs is called a file directory, and an FCB is a file directory entry.
In order to create a new file, the system will allocate an FCB and store it in the file directory entry, which becomes the directory entry.
FCB mainly contains the following information:
- Basic information: such as file name, physical location of the file, logical structure of the file, physical structure of the file, etc.
- Access control information: such as file access permissions.
- Usage information: such as file creation time, modification time, etc.
Index node
In the process of retrieving directory files, only the file name, only when a directory entry is found (find the file name matches the file name in the directory entry), it is necessary to read out the physical address of the file from the directory entry.
That is to say, when retrieving the directory, other descriptive information in the file will not be used, and there is no need to call it into memory.
Therefore, some systems, such as UNIX, use the method of separating file names and file description information. The file description information separately forms a data structure called an index node, which is called an i node (should be the abbreviation of index node). Only the file name and the pointer to the i node are saved in the directory entry.
If an FCB is 64B in size and a disk block is 1KB in size, then 16 FCBs can be stored in each disk block (note that FCBs must be stored continuously). In UNIX, a directory entry only occupies 16B, the file name is 14B, and 2B is the pointer to the i node.
The index node stored on the disk is called the disk index node, and the content of the node includes:
- File Master Identifier: That is, the identifier of the individual or group that owns the file.
- File type: including ordinary files, directory files or special files.
- File access permissions: Access permissions for various users to files.
- File physical address: Each index node contains 13 address items, namely iaddr (0)~ iaddr (12), which can directly or indirectly give the number of the disk block where the data file is located.
- File length. In bytes.
- File link count, all pointers to the file name count in the file system.
- File access time. The time when this document was last accessed by the process, the time when it was last modified, and the time when the index node was modified.
When the file is opened, the disk inode is copied to the inode in memory for use, and the following content is added to the inode in memory:
- Index Node Number: Used to identify memory index nodes.
- Status: Indicates whether the i node is locked or modified.
- Access count: Whenever a process wants to access this i node, the count is increased by 1, and the end of the access is decreased by 1.
Logical device number: The logical device number of the file system to which the file belongs. - Link Pointer: Set the pointer to the free linked list and hash queue respectively.
Directory structure
Before understanding the needs of a file system, let’s first consider the operations that need to be performed at the directory level.
- Search. When users use a file, they need to search the directory to find the corresponding directory entry of the file.
- Create a file. When creating a new file, you need to add a directory entry to the directory.
- Delete files. When deleting a file, you need to delete the corresponding directory entry in the directory.
- Display directory. Users can request to display the contents of the directory, such as displaying all files and attributes in the user directory.
- Modify the directory. Some file attributes are saved in the directory, so changing these attributes requires changing the corresponding directory entry.
When operating, consider the following directory structures:
Single-level directory structure
Only one directory table is established in the entire system, and each file occupies one directory entry, as shown in the figure:
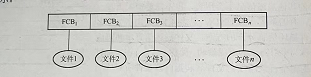
When accessing a file, first find the corresponding FCB in the directory structure according to the file name, and perform the corresponding operation after the legitimacy check. When creating a new file, you must first retrieve all directory entries to ensure that there are no “duplicate names”, and then add an item to the directory to save all the information of the FCB in this item. When deleting a file, first find the FCB, reclaim the file space, and then clean up the directory entry.
The single-level directory structure realizes “access by name”, but there are disadvantages such as slow search speed, file duplicate names are not allowed, and it is not convenient for file sharing, and it is obviously not applicable to multi-user operating systems.
Two-level directory structure
The file directory is divided into two levels: Master File Directory (MFD) and User File Directory (UFD).
The main file directory entry records the user name and the location of the corresponding user file directory.
The user file directory entry records the FCB information of the user file.
When a user wants to access a file, only the UFD corresponding to the user is searched.
This not only solves the problem of duplicate names of different user files, but also ensures the security of files to a certain extent.

Multi-level directory structure (tree directory structure)
This is the most familiar directory structure, with absolute paths, relative paths, working directory (current directory), and all directory names and file names separated by “/”.
The book says that when searching for a file in the tree directory, you need to access the intermediate nodes step by step according to the path name, which increases the number of disk visits and affects the query speed, but the personal feeling is still faster than the above two.
Acyclic directory structure
The tree structure facilitates file classification, but is not conducive to file sharing.
To this end, some directed edges pointing to the same node are added on the basis of the tree directory structure, making the entire directory a Directed Acyclic Graph.
Here you can look back at the data structure and algorithm, how to determine whether a graph is a directed acyclic graph, an undirected acyclic graph.
The algorithms of the two are not exactly the same. For example, the union search algorithm can be used to identify whether an undirected graph has a ring, but it cannot identify whether a directed graph has a ring.
Undirected acyclic graphs facilitate file sharing, but system management is more complicated.
File sharing
File sharing allows multiple users (processes) to share the same file, and the system only keeps one copy of the file.
There are two commonly used file sharing methods in modern times.
Sharing method based on index nodes (hard link)
In the structure of the tree directory, when there are two or more users to share a subdirectory or file, the shared file or subdirectory must be linked to the directory of two or more users to be easy to find.
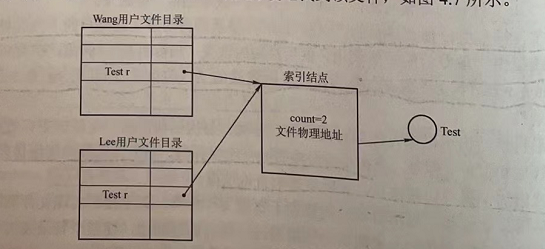
There is a question here. The index node directly points to the file. Can the directory be shared in this way?
The essence of this question is, can an inode point to a directory? Further speaking, can FCB point to a directory?
In this sharing method, information such as the physical address of the file and other file attributes is no longer placed in the directory entry, but in the index node. Only the file name and pointer to the corresponding index node are set in the file directory.
There should also be a counter in the index node to indicate the number of user directory entries linked to this index node (i.e. file).
When a user deletes a file, it cannot be deleted directly, but it is necessary to look at the counter. If the counter is 0, the system is responsible for deleting the file.
File sharing using symbol chains (soft links)
In order to enable user B to share a file F of user A, a new file of type LINK can be created by the system, also named F, and then save this file F to the directory of user B to realize the directory of user B and the file F. Connect.
The new file only contains the pathname of the original file F. Such a linking method is called a symbolic link.
The pathname in the new file is only regarded as a symbol chain. When user B wants to access the linked file F and is about to read a new file of the LINK class, the operating system reads the file according to the pathname of the new file, so as to realize the user B’s relationship with the new file. Sharing of file F.
Only the owner of the file has a pointer to its inode, and other users sharing the file only have the path name of the file, so there is no problem of deleting a shared file and leaving a dangling pointer (this problem is a hard link problem).
When the owner of the file deletes a shared file, when other users access the file through the symbol chain, access failure will occur. At this time, the symbol chain will be deleted, and it will not have any impact at this time.
However, there is still a problem with using this method. After a file is shared through a symbolic link, the owner of the file deletes it, and other users who share the file before using the symbol chain to access the file, someone has created a file with the same name under the same path. If the file is still valid, but the point is no longer the original file.
The disadvantage of the soft chain method is that it is necessary to search the directory one by one according to the file path name until the index node of the file is found. Each access may have to read the disk multiple times, which increases the cost of accessing files and increases the frequency of starting the disk.
The advantage is that network sharing only needs to provide the network address and file path of the machine where the file is located.
Common issues
Both of these linking methods have a common problem, that is, each shared file has several file names.
That is to say, every time a link is added, a file name is added. Essentially, each user uses their own pathname to access the shared file, so when we try to traverse the entire file system, we will find the shared file multiple times.
Both links are static sharing methods, and there are additional sharing requirements in the file system, that is, two processes operate on a file at the same time, which is called dynamic sharing.
In other words, this way of static sharing only solves how different users access the same file, but it still cannot be accessed at the same time, and access at the same time belongs to dynamic sharing.
File protection
Access type
The protection of files is to control the access rights of files. The access types are mainly divided into:
- Read. Read from file.
Write. Write to the file. - Execute. Load files from the hard disk into memory.
- Add. Add new information to the end of the file.
- Delete. Delete files to free up space.
- List List. List file names and attributes.
In addition, file renaming, copying, editing, etc. can be controlled. These high-level functions can be combined by the above low-level, so protection only needs to be done at the low level.
There is a question here, why distinguish between write operations and add operations?
Access control
ACL
The most common way to solve access control is to control according to user identity. The most common way to achieve identity-based access is to add an Access-Control List (ACL) for each file and directory, which specifies each User name and allowed access rights.
The advantage of this method is that complex access methods can be used, while the disadvantage is that the length is unpredictable and may lead to complex space management.
The streamlined access list adopts owner, group, and other three types of user types.
- Owner. The user who created the file.
- Group. A group of users with similar access who need to share files
- Other. All other users in the system
This only needs to be which domain to list the access permissions of these three types of users in the access table.
When the file owner creates a file, he explains the user name and the group name where he is created. The system also lists the name of the file owner when creating a file, and the group name he belongs to is listed in the FCB of the file.
When a user accesses a file, the file is accessed according to the permissions owned by the owner. If the user and the owner are in the same user group, they will be accessed according to the same group permissions, otherwise they can only be accessed according to other user permissions. UNIX adopts this.
This permission control method has been expanded, and it is actually very similar to RBAC, Role-Based Access Control (Role-Based Access Control).
Password
The user provides a password when creating a file, and the system attaches the corresponding password to the FCB established by it, and at the same time, this password is told to other users who are allowed to share the file. The user must provide the corresponding password when requesting access to the file.
This time and space overhead is not large, but the password is directly stored in the FCB, that is, directly in the system, not safe.
Password
This is to encrypt the file, convert the original plaintext into incomprehensible ciphertext storage through a string of passwords, and require the user to provide a password for decoding each time it is opened.
There is no space consumption in this method, and the password does not need to be stored, but it needs to be encoded and decoded every time it is used.
Both passwords and passwords prevent user files from being accessed or stolen by others, and do not control the type of access to files.
A common method of file protection in modern operating systems is to use ACLs together with user, group, and other member access control schemes.
For multi-level directories, not only need to protect a single file, but also need to protect the directory, and the directory and the file not only operate differently, but also the directory entry does not have FCB, so the directory protection mechanism and the file protection mechanism are not the same.
Answer the first two questions
What is a file? What is a file system?
A file is a collection of information stored on a computer using a computer hard disk as a carrier. It comes in various forms, including text documents, pictures, programs, etc. The software organization responsible for managing and storing file information in an operating system is called a file management system, or a file system for short. A file system consists of three parts:
- Software related to file management
- Managed files
- Data structures required to implement file management
What functions does the file system need to complete?
For users, the most important function of the file system is to realize the basic operation of the file, allowing users to access and find files by name, organize them into a suitable structure, and should have basic file sharing and file protection functions.
For the operating system itself, the file system needs to manage the exchange of information with the disk, complete the exchange of logical and physical structures of the file, organize the storage of files on the disk, and take a good file storage order and disk scheduling method to improve the entire system performance.