Development and Design of OAuth
The Chinese name of OAuth is the Open Authorization Protocol. This name is carefully tested by everyone. It is an authorization protocol. ** Any website that implements this protocol can grant corresponding users to certain applications registered here under the conditions of user consent. Permission ** for certain resources on this website, and this permission is generally represented by token.
Examples of practical applications
When you go to leetcode to log in, the following page will pop up
Here we have two options, one is to register an account directly, and the other is to choose a third-party login, such as QQ login, which uses OAuth in the third-party login.
For this second method, a few points should be emphasized here:
- ** The number of your accounts has not decreased at all, you still have both leetcode and qq accounts **, but qq provides the OAuth protocol, you authorize leetcode to obtain your information in qq, leetcode uses this information To create your account in leetcode, your account in leetcode will not be stored in qq at all, which is a bit similar to the real life you need to take your ID card when you register an account in the relevant institution, this institution uses your ID card Go to the Public Security Bureau system to find your information, and then use this information to create your account in this institution. You give these institutions an ID card is similar to a process of authorizing it to go to the Public Security Bureau to manipulate your information.
- The OAuth protocol is just an authorization protocol, and the above process is called ** third-party authorized login. The login action is not specified in the OAuth protocol, that is to say, OAuth alone cannot complete the set of authorized login actions **, and OAuth is not only It is used for third-party login. Although we talk about OAuth most of the time with third-party authorized login, we need to break this limiting thinking.
The development process of landing methods
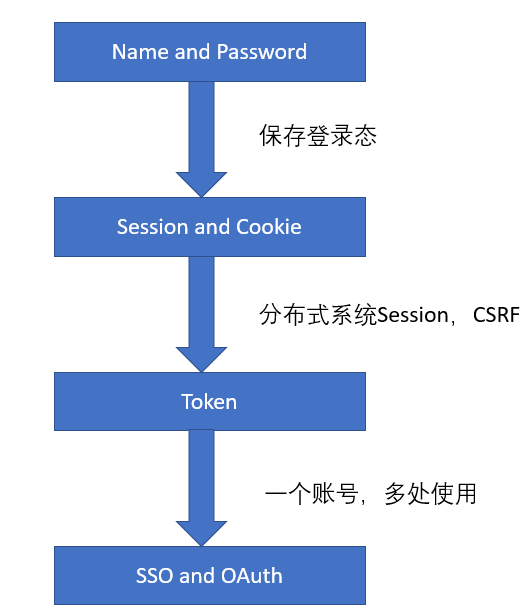
Username Password
At the beginning of our server-side rendering and static pages, we only authenticate through username and password, which is the basis of all authentication, and most of the future authentication methods are still based on this method.
This method is very useful at the beginning, the website first gives you a landing page, you log in successfully to return another page from the server, you get this page to show that you have been logged in, and your identity information has been returned before writing the page, but you can not see.
But the biggest problem with doing this is that once you close the page, the next time you open it, you have to log in again, which will have a poor User Experience. So we started to think of a way to save the user’s login status? So there is a second way, Session and Cookie.
Session和Cookie
In this way, after the user successfully logs in for the first time, the user’s information will be saved in the session and stored in the server, and then a sessionId flag will be generated to mark the session and returned to the front end through the set-cookie header. In this way, due to the implementation decision of the browser, every same-origin request initiated will automatically bring the cookie under the source, which also brings the sessionId, so that each time the server only needs to check the cookie sessionId, verify its validity to find user information.
But this has a problem, the browser is very unreliable, basically the browser knows it is likely to know the whole world, here is recommended to take a closer look at the same origin policy, this thing is not as strict as imagined, recently I It has a few more cognitions:
- The same-origin policy generally only restricts requests such as XMLHttpRequest, such as Ajax. For requests made directly by the address bar, there is no restriction, and whether the request for Retargeting this request is restricted is still being explored.
- Cross-domain write operations such as Form Submission, Retargeting, etc. are generally unrestricted
- Cross-origin resource embedding is generally unlimited.
- Cross-domain read operations are generally not allowed, but can be broken by the previous one, such as using the script tag to load scripts across domains
- Scripts from different domains cannot operate on dom.
Through the above cognition, we can find a more critical thing, the same origin policy of the browser is not limited to the direct request initiated by the src, and as long as the cookie under the same domain name as the link you requested will be automatically brought.
Here is a classic example, that is, if you go to the bank website to log in, the sessionid is stored in the cookie, before the cookie expires, you open an attacker’s website, there is an img tag, its src attribute is bank.com/tran/1000, that is, the meaning of the transfer of 1000 yuan, because it is src, so the browser will automatically initiate this request, although there is certainly no picture return, but the request has been issued, and will automatically bring the bank’s cookie that has not expired, because the browser sees that the address you requested is the bank, it will automatically help you bring it.
The above example is a relatively simple CSRF attack.
The main purpose of the above example is to show that ** cookies are not secure, even with the same origin policy **.
And with the development of distributed systems, if you store identities in this way, you have to maintain a copy of the identity on each server and ensure its consistency.
Based on the above two reasons, we are thinking again, is there any way to throw the identity information back to the front end, so that every time the front end comes with the identity information, I can verify whether I granted it to him, and make this method safer? So, we came up with a Token. These are also two characteristics of a token, one is stored on the front end, and the other is generated by the server, which is generally not stored in cookies.
Token
Just now we said that Token is the proof of our identity generated by the server and stored on the front end, so how can we ensure its security? An older practice is if your page is server-side rendering, insert your token in each place where you need to submit a request before returning, so that this token can not be stored in a cookie, and cross-domain scripts cannot operate dom and cannot obtain your token.
But in this way, it seems to be back to the beginning. As soon as the page is closed, the token is gone, and the consumption is relatively large.
Another way is to put this token in the http header, which is the x-csrf header.
There are also many ways to use tokens, which are not the focus of this time, so I will not explain them in detail.
SSO
When all the problems of our identity authentication have been better solved, there is a new problem, that is, with the increase of applications, we need to remember more and more accounts, we need a way to help us remember All accounts or only one account, the second way is SSO, which has a variety of implementation foundations, one of which is today’s topic OAuth.
Let’s define a few keywords before discussing this topic.
User: User
User Agent: User agent, such as a browser
Consumer: Information consumer, such as Leetcode
Service Provider: There are two types, namely Identity Provider (IDP), such as QQ, and Resource Provider (Resource Provider), but the two are generally the same.
Therefore:
- The emergence of SSO is not to solve some security or process problems on login, it is to help us remember some accounts, OAuth is just the basis of its implementation.
- OAuth is only responsible for the user authorizing the consumer to manipulate some resources belonging to the user in the SP, but in SSO it is used to create an account in the consumer after the SP obtains user information, so that the next time as long as the user passes the authentication in the SP, it is equal to The consumer passed the authentication.
- The user’s identity and permissions in the consumer have nothing to do with OAuth, it is a matter between the two, it has nothing to do with OAuth, and it has nothing to do with SSO. The authentication between them will return to the first three methods. SP does not care about or store the user’s identity or permissions in the consumer.
- OAuth alone cannot complete the entire process of authorized login.
Take a practical look at the request for OAuth during the SSO process
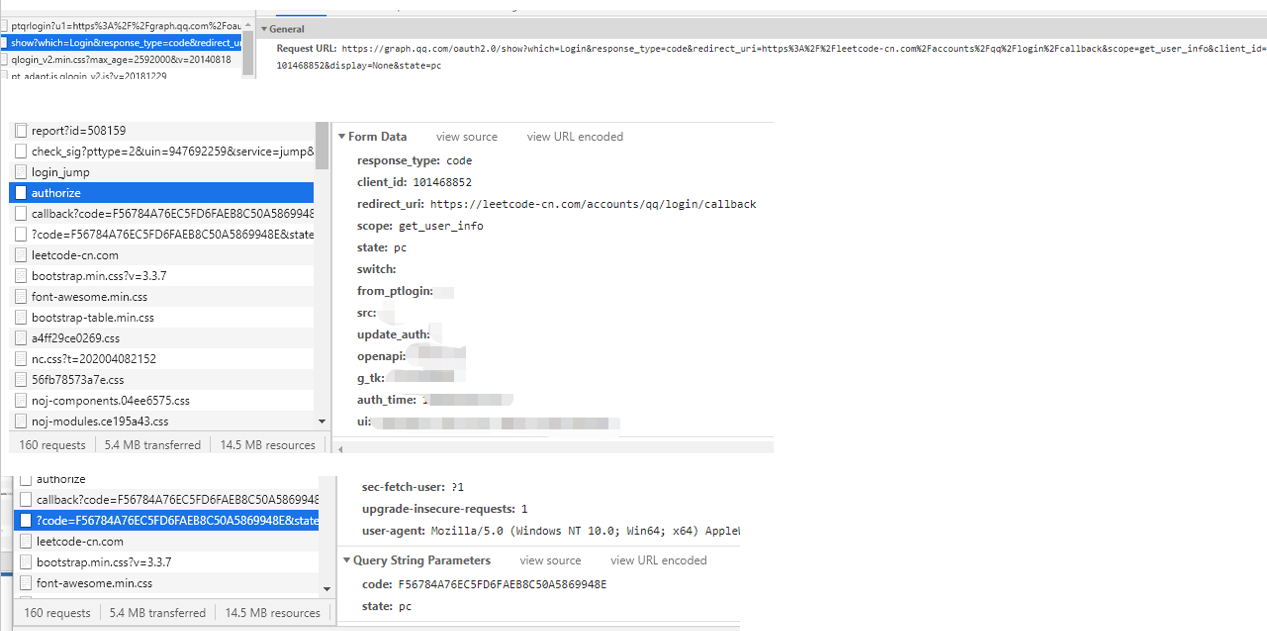
This picture is the request I took to log in to the front end of leetcode with qq, which is roughly divided into the following steps:
- Go to the qq authentication server to pull the authorization page. The parameters include some parameters generated by the leetcode server for the next authorization request. Only with these parameters can it pass the verification of the qq authentication server and return the authorization page. At the same time, the authorization page needs to use these parameters for the next request
- After selecting authorization, a second request will be sent, which includes some parameters defined in the OAuth protocol and parameters required by qq itself.
- After the second request reaches qq, it is verified and returns a 302. Location is the redirect_uri in the second request parameter, and then splice the code and state generated by qq in the parameter.
- After the browser receives the 302 return, it takes out the location again to send the request, so this location is generally its own background.
- After receiving the request in the background, take out the code to QQ to exchange for the token.
** OAuth protocol has done these things, so now do we have an account in leetcode? No **, then leetcode will create a leetcode account after taking the token to qq to exchange for identity information
Describe some details of the OAuth2.0 design in authorization code mode

The A request here is the first request just now, B is the second authorization request, C is the return of B, the status code is 302, and the location is redirect_uri? code = XXX & state = XXX. After the browser receives it, re-request the location of C. The request goes to the leetcode background. After the background gets the code, it goes to qq to exchange the token with some parameters.
You may have a lot of questions here:
What do these parameters represent?
redirect_uri: The domain name filled in by the consumer when the SP applies for a third-party authorized login service is generally the domain name of its own server.
client_id: The unique id of the consumer generated by SP after the consumer applies for third-party authorization to log in to the service.
client_secret: After the consumer applies for a third-party authorized login service in SP, the only certificate of the consumer generated by SP can prove that you are a consumer only if the id and secret are given at the same time.
Scope: The permission you want to apply for is generally specified by SP.
State: A random string, generated by the consumer itself
Code: The code returned by SP to the browser after user authorization, and the consumer can exchange this code for token.
access_token: the ultimate goal.
Why send a redirect_uri to the IDP in the first place?
The first time is to set the Location in the return 302 of the IDP, you can not verify whether it is set by the consumer. The second time is to verify whether the redirect_uri is set by you in the IDP at the beginning, and whether it is the same as the first time over. This step must be verified, because this step is the most critical, and this step will return the token.
Why go around such a big circle, why do you need to change the code one more step access_token?
In the end, I still can’t trust the browser comrade, let him be a tool man, let it help my background to apply for an authorization code from a third party, and then give this authorization code to my background, and then my background uses this code to go to a third party Apply for a token, and don’t tell the browser what the token is when you’re done, you stay, that is to say, the browser comrade has never seen the token from beginning to end.
What’s the use of secrets?
The reason is that IDP does not believe anyone, so it believes the secret it gives itself. Because redirect_uri is a domain name, it still depends on the IP Address in the end. If the domain name is correct, but the domain name is pointed to by the attacker’s own IP, the attacker will receive the token. How to modify this DNS pointing involves DNS pollution, because DNS will be cached layer by layer, but there is time. If you keep broadcasting to tell the router or host that I am leetcode and I am leetcode, after a long time, you will be in this area. Network is considered leetcode. But if there is a secret, even if you bring the code to the IDP, without the secret I gave you, the IDP will not give the token. So client_id show who you are, only if you give client_secret, the IDP will believe what you say and give you the token, so this secret is very important, our background will not believe the browser comrade, so our browser comrade has never touched the secret from beginning to end.
What is the use of the State?
Similar to the defense CSRF, to ensure the consistency of the requesting device, but unlike the CSRF, which forges the victim’s request, but allows the victim to log in to his account. If the victim saves a Bitcoin account in it, wouldn’t it be beautiful? The specific implementation is that after the attacker logs in, he applies normally, but after returning to the IDP 302, he stops the request, prevents the browser from sending a request to his background, and then links the request with code to the victim. After the victim clicks in You can get the access_token successfully log in. If you don’t pay attention to whether this account is your own, you will upload sensitive information, which is very happy. If there is a state, different devices in the background generate a random string to the front end. Even if the attacker sends the request to the victim, he does not know the state in the victim’s device. When the background sees your state, it will directly throw away the request. Of course, it is absolutely necessary to say that the attacker stole your state from a certain request of the huge Internet. This is a fixed-point blasting. To deal with you, most of this person has already been mixed around you.
Why did it return two tokens in the end?
Because one represents who you are, one represents what you can do, and the things you can do can be changed by the administrator at any time, but who you are is fixed, and generally access_token expiration time is relatively short. If I use it, it will expire. It can’t let the user log in again, isn’t it back to the starting point?
Other modes in OAuth2.0
Simplified mode
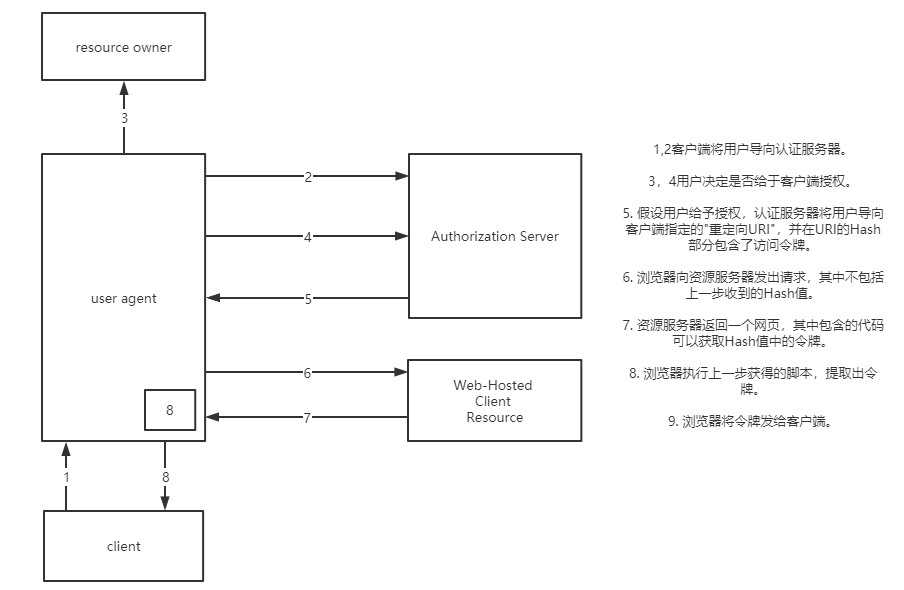
This method is different from the authorization code mode. It is suitable for situations where there is no server side, such as mobile applications. The front end gets the token directly from the SP, but it should be noted that this token is not spelled like the code in the authorization code mode. After “?”, but after “#”, it can effectively reduce the risk of leaks.
Password mode
In Resource Owner Password Credentials Grant, users provide their username and password to the client. The client uses this information to request authorization from the “service provider”.
In this mode, the user must give their password to the client, but the client must not store the password. This is usually used in situations where the user has a high level of trust in the client, such as when the client is part of the operating system, or produced by a well-known company. The authentication server can only consider using this mode if other authorization modes cannot be implemented.
Client mode
Client mode (Client Credentials Grant) means that the Client authenticates to the “service provider” in its own name, not in the name of the user. Strictly speaking, Client mode does not belong to the problem to be solved by the OAuth framework. In this mode, the user registers directly with the Client, and the Client requires the “service provider” to provide services in his own name, but there is no authorization problem.
OAuth1.0
A brief introduction to 1.0 and why it developed into 2.0
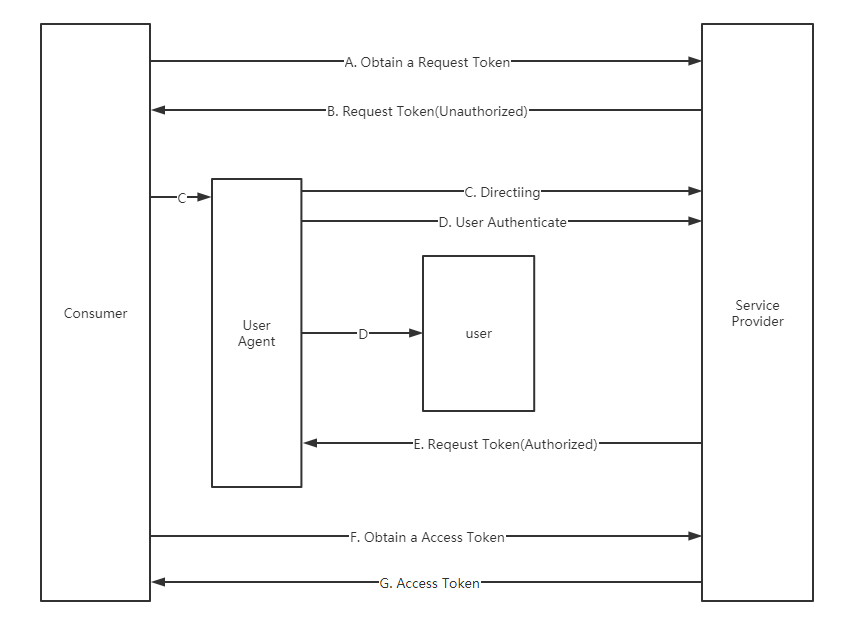
The biggest difference is more AB two steps, that is, 1.0 will first go to SP to apply for an uncertified state of the request_token (can be compared to 2.0 code), the next purpose is to change the request_token into a certified state, and then you can take this request_token to change access_token.
Adding this step will cause problems, such as会话固定
There is for mobile phones or Client applications, Retargeting this step is not achieved, can only throw a connection to allow users to open their own browser paste into the next step. This will give the attacker a great opportunity.
It can be seen from this that version 1.0 has great security problems, and the experience is relatively poor for non-web applications, so 2.0 was launched.
For example, the simplified mode of 2.0 is to adapt to Client applications, and those who are interested can learn about it themselves.
1.0a
In order to fix the security issues in 1.0, 1.0a was proposed, and he mainly made the following changes:
When a Consumer applies for a Request Token, it must pass the ** oauth ** _callback, while when a Consumer applies for an Access Token, it does not need to pass the ** oauth ** _callback. By passing the time of the pre ** oauth ** _callback, let the ** oauth ** _callback participate in the signature, so as to prevent the attacker from impersonating the ** oauth ** _callback.
After the Service Provider obtains the authorization of the User, when Retargeting the User to the Consumer, it returns ** oauth ** _verifier, which will be used in the process of the Consumer applying for an Access Token. Attackers cannot guess its value.
Reference materials:
https://sunra.top/2019/11/16/OAuth%20and%20OIDC/ :OAuth,OIDC简介
https://sunra.top/posts/74ee5df7/: Routing Protocol
https://sunra.top/posts/dfdf7442/: ARP Principle and Defense
https://www.jianshu.com/p/0db71eb445c8: Examples of OAuth Authentication Processes
https://www.chrisyue.com/security-issue-about-oauth-2-0-you-should-know.html: Security Considerations in OAuth2.0
https://www.cnblogs.com/linianhui/p/openid-connect-core.html: OIDC doc
https://www.zhihu.com/question/19851243: Difference between OAuth1.0 and 2.0
https://docs.azure.cn/zh-cn/active-directory/azuread-dev/v1-protocols-openid-connect-code :OIDC + AAD
https://www.sciencedirect.com/science/article/pii/S2215098617316750: Security Issues in Cloud as a Service
https://developer.mozilla.org/zh-CN/docs/Web/Security/Same-origin_policy: Same Origin Strategy