10 times programmer work method
The recent chatgpt fire has made many people think that many jobs, including programmers, will be replaced. Other positions I do not know much about, but for the programmer career, I think but in fact this shows that the perception of programmers in dealing with the problem is that programmers deal with a particular independent problem on, or a separate very specific problem on, of course, this and programmer interview questions, after all, programmer interview questions is actually this, interview questions, to say the least, is to do the paper, do the paper how you may have the back of the Internet robot than, and those badly measured seem to be empty words, in an interview, people really do not necessarily perform than the back is all the interview experience post robot superior.
But in fact this is already forgetting what programmers exist for. The technology that programmers master is called information technology, and its purpose is to collect and process information quickly, so why is this technology important? Understanding this issue, in fact, can also understand what AI actually brings to us.
Preface
In fact, it is now considered the fourth industrial revolution.
- The first was the age of steam, when mankind mastered great physical power, and machinery gave mankind the power to transform the physical world more powerfully
- The second is the electrical age, which is a continuation of the first, allowing people to transform the world more quickly, while accelerating the efficiency of people’s material cooperation
- The third is the information age, which is the age that most of us experience. Many people may not understand why information is important, after all, this thing is vague, and the Internet looks like an explosion of information, simply worthless. But in fact, for society, information is the most valuable thing, because, ** money is actually information, and even the entire human society exists on the basis of information, as stated in “A Brief History of Humanity”, without a common imagination, the largest human can only be maintained into a small tribe, just like the animals, it is a common imagination, so that humans have a cooperative **. And the role of the market is to exchange information, no one person can handle all the information in human society, even if he has access to all information. Then there are luxury goods, such as jade, diamonds, gold, what makes you say that the price between them is different, is information, his physical nature is not expensive, so there is no need to ask why luxury goods are expensive, there is no reason.
- the fourth is artificial intelligence, which is considered a continuation of the third. Why there is this thing is because of the explosion of information, too much, ** individuals can not handle it, the speed of processing information is too low, and many people cooperate will bring new information to deal with, these are the management to do up**. There are many positions that acted as artificial intelligence in the past, such as low-end consulting positions, they actually help integrate information, because there is too much information, such as buying a house, unless you recently want to buy a house, you can not collect every day, to deal with, so it gave birth to people who specialize in processing this information it.
So if the third industrial revolution is allowing people to collect and process information faster, then the fourth, chatgpt including artificial intelligence in my personal opinion, is giving everyone stronger tools to filter and process information.
This may not seem like an essential change, still improving the speed of processing information, but don’t forget that any complex problem is caused by simple problems coupled together quantitative change produces qualitative change. When there are enough problems and enough people involved, it’s not really a problem anymore.
** complexity is the biggest problem, capital all efforts to improve efficiency, efforts to understand the laws of the world, management science, etc., are designed to reduce complexity, of course, the overall efficiency improvement does not mean individual happiness, because the overall want to be efficient, in which each individual can not have a personality **. Conversely, if a tool can improve the efficiency of enough, is the industrial revolution, the industrial revolution is actually a tool to bring great efficiency improvements.
All this to say, is to express a point of view, programmers deal with things is actually to reduce the complexity of information, the analysis and processing of information to the machine, the first thing to do the programmer itself to understand this information, and then transformed into a program, so the value of the programmer’s work does not lie mainly in programming, if not to help deal with information, reduce the complexity of the complexity to the machine, the more brilliant technology is useless. After all, it is never the capital that determines the direction of technological development.
So the focus of improving programmer productivity shouldn’t just be on how to knock out code faster, except of course for the very few people who make tools for programmers.
10x programmer work method
The following content comes from the column of the same name in the geek time, here is just a summary of my personal notes, we recommend you to see the column
Thinking Framework
Essential and Contingent Complexity
There is a famous book in the software industry called “The Myth of the Human Moon”, which mentions two very important concepts: Essential Complexity and Accidental Complexity.
Simply put, essential complexity is what must be done to solve a problem no matter how it is done, while accidental complexity is what has to be done more because of the improper choice of the way to do things.
For example, if you want to make a website, the content of the website is something you have to write anyway, and this is the “essential complexity”. If you are still writing a website in assembly today, it is impossible to be more efficient because you have chosen the wrong tool. This kind of problem caused by choosing the wrong method or tool is the “accidental complexity”.
Four principles of best practice
- Begin with the end in mind;
- Task breakdown;
- Communication feedback;
- Automation.
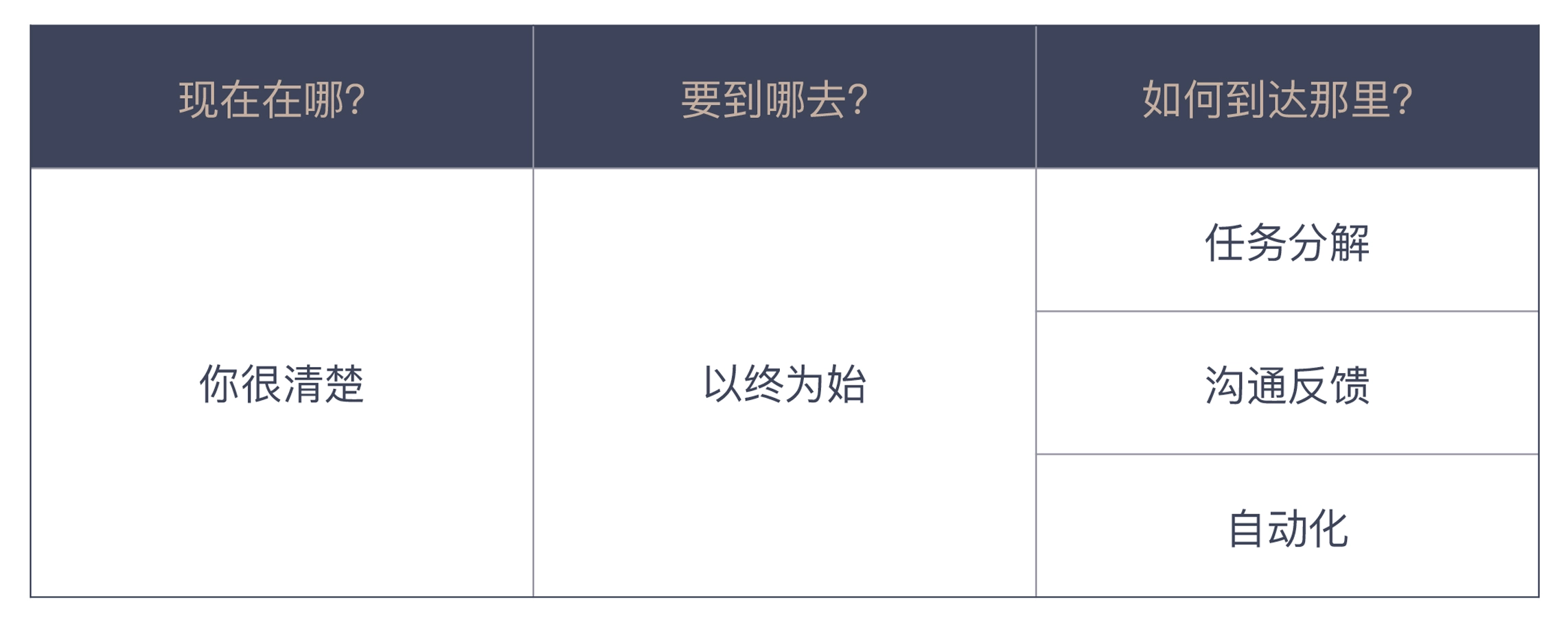
Thinking Framework:
- Where are we?
- Where are we going?
- How can we get there?
Linkage between the Four Principles and the Thinking Framework
In practice, this thinking framework will help me better understand my work. For example, when a product manager gives me an explanation of a feature to be developed, I usually ask him questions such as
- Why this feature and what value it will bring to users?
- What kind of users will use this feature, in what scenarios will they use it, and how will they use it?
- Are there other means to achieve this? Is it necessary to develop a system?
- After this feature goes live, how do you measure its effectiveness?
If the product manager can answer these questions well, it means that he has basically thought this job through more clearly, and at this time, I will feel comfortable to understand the details of the follow-up.
Begin with the end in mind means setting your goals at the beginning of your work. We need to see the real goal, not the work that others have explained to us as the goal. You can see that this principle is helping us to answer the question in the Thinking Framework, Where are we going? This question.
Task decomposition is to break down the big goal into feasible tasks. The more detailed the work is broken down, the better we can control the work. It is a way to help us answer the question of how can we get there?
If the first two principles are to be done before the hands-on analysis, then the last two principles are on the road to the goal, to escort us, because in practice, we can not help but deal with people and machines.
Communication Feedback is about unblocking the channels of interaction with others. On the one hand, we ensure that information can be communicated to reduce work omissions caused by misunderstanding; on the other hand, we must also ensure that we can accurately receive external information so that we do not feel good about ourselves and hinder progress.
Automation is the automation of tedious work to be performed by machines, which is part of our job as programmers. We are good at building automation for others, but we don’t apply it enough for our own work, and this is the part of our job that deserves optimization.
Begin with the end in mind
Begin with the end in mind: how to make the effort not in vain
We face real work scenarios on a daily basis: many of us just hear about a feature that someone has asked to do and start brainstorming everything that comes next. The result is that the effort put in is meaningless.
“Beginning with the end in mind” is a counter-intuitive way of thinking that most people do not possess. Therefore, in our daily life, we see many interesting phenomena. For example, when you graduate from college, there are many people who want to go to graduate school. If you ask them why they want to go to graduate school, the reason they get is usually to find a good job. But can studying really help him find a good job? Not necessarily, because finding a job and going to graduate school are not even the same skill tree. If you really want to find a good job, then you should understand what the job requires and how you can acquire the skills required for the job.
The example of “designing a login function”, compared with the thinking of “beginning with the end”, you may be unfair for my colleagues, they may also have the thinking of “beginning with the end”, only that Their “end” and I, the customer’s “end” is not the same. This brings us to ** do software, is essentially building a “collective imagination”. **
Imagined Community
We do software is actually a community of imagination, the “collective imagination” is the software we want to do, any imagination needs a carrier to show it, we write software is the process of the “collective imagination” to implement the process.
Since it is a “collective imagination”, it is difficult to unify our imaginations before the carrier presents them, and they all differ to a greater or lesser extent.
So, everything is created twice: once in the mind, which is the intellectual or first creation (Mental/First Creation), and then only when it is put into practice, which is the actual construction or second creation (Physical/Second Creation).
Going back to the “designing a login” example, my colleagues were building their own imagination, not ours.
One of the biggest differences is that no one will pay for their own imagination. So, ** they see the “end” is not the real end, but only an ego “end”, as to see what kind of “end”, it depends on each person’s insight **.
For those who do software, we should position the “end” to do a valuable software for users, to bring value to others, their value can be reflected.
Planning and Discovery
With the “end in mind” mindset, we think about how others will use our platform. We designed it in such a way that users would go to our website, read the documentation, and then follow the documentation step by step. One of the key points is that the documentation, especially the “Getting Started” documentation, is the first step for the user to get in touch with our platform and determines his first impression of our product.
So, we decided to start by writing the “Getting Started” document, which depicts how users can use our development platform step by step to complete their first “Hello World” level application. Note that at this point, we hadn’t written a single line of code.
Human beings are a group of people who are good at brainstorming. Once someone sees the document, he can already conceive the platform as it already exists, and then give all kinds of feedback: “I think this place can be done like this” "I think that place can be changed ".
**All of this feedback is real because they have “seen” a real thing. It was this real feedback that allowed us to gradually lock in our target. **After that, we started to write the code.
An “end-to-end” approach not only helps us plan our work, but also helps us identify problems in our work.
Amazon CTO describes how Amazon develops a product, in short, they use a backwards working approach, the sequence of developing a product is
- writing press releases;
- write FAQ (Frequently Asked Questions);
- writing user documentation;
- write code.
Chasm of Understanding
The topic of our discussion is “Begin with the end in mind”. Our first question is, what exactly is “the end”? In the previous example, the “end” is “finished”, but Li thinks his work is done, but Zhang thinks he is not done.
There are many ways to bridge the gap, but there is a best practice called DoD (Definition of Done), and it is easy to see from the name of this concept that it was created to solve the common problem of “completion” in software development.
How to make DoD work better.
- DoD is a checklist of check items that are used to check how well our work is done. A DoD check item is a set of valuable activities that we need to develop a product. For example: writing code, writing test code, passing acceptance by testers, etc. What kind of activities are valuable may be perceived differently by each team. But if your team perceives nothing but functional code as valuable, perhaps this is a sign that your team as a whole is lacking in professionalism and the prospects of working in such a team are not good.
- DoD’s check items should be actually checkable. You say the code is written, where is the code; you say the test coverage is up to par, how do you see it; you say you have the functionality done, demonstrate it.
- DoD is a mechanism for team members to report back to each other. Don’t think of “reporting” as complicated. The simplest way to report is to say “this feature is done”. When we have a DoD, there are only two states of doing things, “done” and “not done”. In teamwork, we often hear people say “this thing is 80% done”, sorry, that is called not done, there is no 80% done.
If you can think outside the box, you will find that DoD thinking is very versatile in your work. For example, when we need to work with other teams to develop an interface, we all know that the first step is to get the interface defined.
**Once the DoD is established in collaboration, we can even solidify it through a process to get the job done more efficiently and with high quality. **Of course, we inevitably have ad hoc tasks in our work lives that are not complex enough to require a process, but can be solved efficiently with a DoD mindset. For example, I often have people come over and ask me to help with something. Using DoD thinking, I first ask the person exactly what I need to do, confirm the details (equivalent to defining the “checklist”), and then I know how far I can go with the favor. When I ask someone for a favor, I tell them exactly what I need them to do to minimize unnecessary misunderstandings.
DoD is a mindset, a way to eliminate as much uncertainty as possible and reach consensus. We do things in a way that “the end is the beginning” and DoD allows us to clearly define the “end” at the beginning.
The root cause of all the problems that often arise in human collaboration is that there are too many misunderstandings caused by differences in understanding that waste a lot of time, and DoD is a way to put ideas that are prone to ambiguity into practice.
**Define the criteria for completion before you do anything. **
What is the first thing to do when you receive a requirement assignment? **
In software development, what programmers do is generally defined by requirements. We all know that requirements are an important part of software development, but you may not have thought carefully about the different ways of describing requirements that may affect our programmers’ understanding of them.
Because the transmission of information decays, you cannot transmit 100% of what you understand to another person, and in between, how it is transmitted, i.e. how it is described, will directly determine the percentage of decay.
Many companies have a software development model based on a feature list that “defines” what programmers will do, and each group gets the list from the product manager and starts writing the code “as is”. However, often this feature list is just a simple description and you don’t see the big picture.
One of the states of many teams is that the programmers know what the feature to be developed is, but many of them can’t answer who is using this feature in what scenario. If you ask him why he is developing this feature, he usually says: it is specified in the feature list.
** This feature list style of requirements description knocks a complete requirement into pieces. ** Only when all the features are developed and dovetailed together is it time to “break the mirror”.
Based on this feature list-based requirement description, each group schedules its work with the features as it understands them. So, when your group finishes a feature, that feature may not make it to the line because you have to depend on the work of another group that, not coincidentally, happens to have the related feature development scheduled. This is just the case where there are dependencies between two groups, so imagine how bad the situation would be if multiple groups need to collaborate.
As a result, new ways of describing requirements have emerged, of which User Story is one of my favorites. It describes a user’s desired functionality from the user’s point of view, focusing on the path the user needs to take to complete an action in the system. Since it is a “story”, it needs to be a complete scenario that can be told.
It’s good if your team uses a user story format for requirements description, but if not, supplementing the feature list with acceptance criteria will greatly improve the efficiency of collaboration between the two parties. **
The implementation details given in the acceptance criteria should be business, and it is really a waste of time for programmers to think about such issues, and our space to play should be in the technical implementation.
Although you are nominally a programmer, when you get a requirement, the thing you have to do is not to write code immediately, but to play the role of a product manager, analyze the requirement and circle the scope of the task. Trust me, analyzing beforehand is definitely much better than taking a written system to your boss and him telling you it’s not what he wants.
If there is only one thing you can remember from today, remember this: Set acceptance criteria before you do any requirements or tasks.
Lean Startup
What Lean Startup provides us is a framework for thinking about making products, and most of the products we can come across can be put into this framework.
With the framework structure, our life is simple. When a product manager wants to make a new product or a new feature of a product, we can use these concepts of Lean Startup to check whether the product manager has thought it through.
For example, ** you want to do this product feature, what is the thing that you want to validate? Is there data available to measure the goal he is trying to validate? Is this problem to be solved the most important thing at the moment, and are there other more important problems? **
If the above questions are answered in the affirmative, is there a simpler solution to validate this goal, and does it have to be achieved by developing a product feature?
Expanding the work context
Programmers always like to use technology to solve all problems, but many of the problems that make people sleepy are not problems at all. The reason why they can’t find a simpler solution is that many times programmers are limited by their own thinking.
**The real difference between working in different roles is the difference in context. Problems that are difficult to solve in one local context can even be left unsolved by switching to another context. So no matter how hard a single point is worked on it is only a local optimization, and it is difficult to achieve optimal results. **
If you want to do your job well, you need to constantly expand the context of your work, learn more about what the logic of other people’s work looks like, and recognize the full lifecycle of software development.
Expanding your context can be good for your career, in addition to helping you to be more productive at the moment. As you see a wider world, you get more and more opportunities.
If there’s only one thing you remember from today, remember this: **Expand the context of your work and don’t limit yourself to the role of a “programmer”. Don’t limit yourself to the role of a “programmer.” **
Path to Results
With regard to “beginning with the end”, what we have been talking about is seeing results, and results are important. However, it is the path to the result that is more important.
In contrast to our work, in most cases, even if the goal is clear, the path is blurred. So, different people have different ways of dealing with it. Some people go where they go and then look at it; others project the path first and see how far they can go. In our process of making software, the differences brought by these two paths have been reflected in the previous short story. One is the first period of its happiness, the later hand to hand; one is the front of thinking ahead, the back of the four stable. I personally respect the latter approach.
This idea is not difficult to understand, and we can easily apply it to many aspects of our work. For example:
- before making a product, to deduce how this product will be promoted and to what kind of people by what means;
- Before making technical improvements, consider how going live is a process and prepare a plan for possible problems;
- Before designing a product feature, let’s consider who provides the data and what the complete process looks like.
Make the results of your work digitally available
Iteration 0
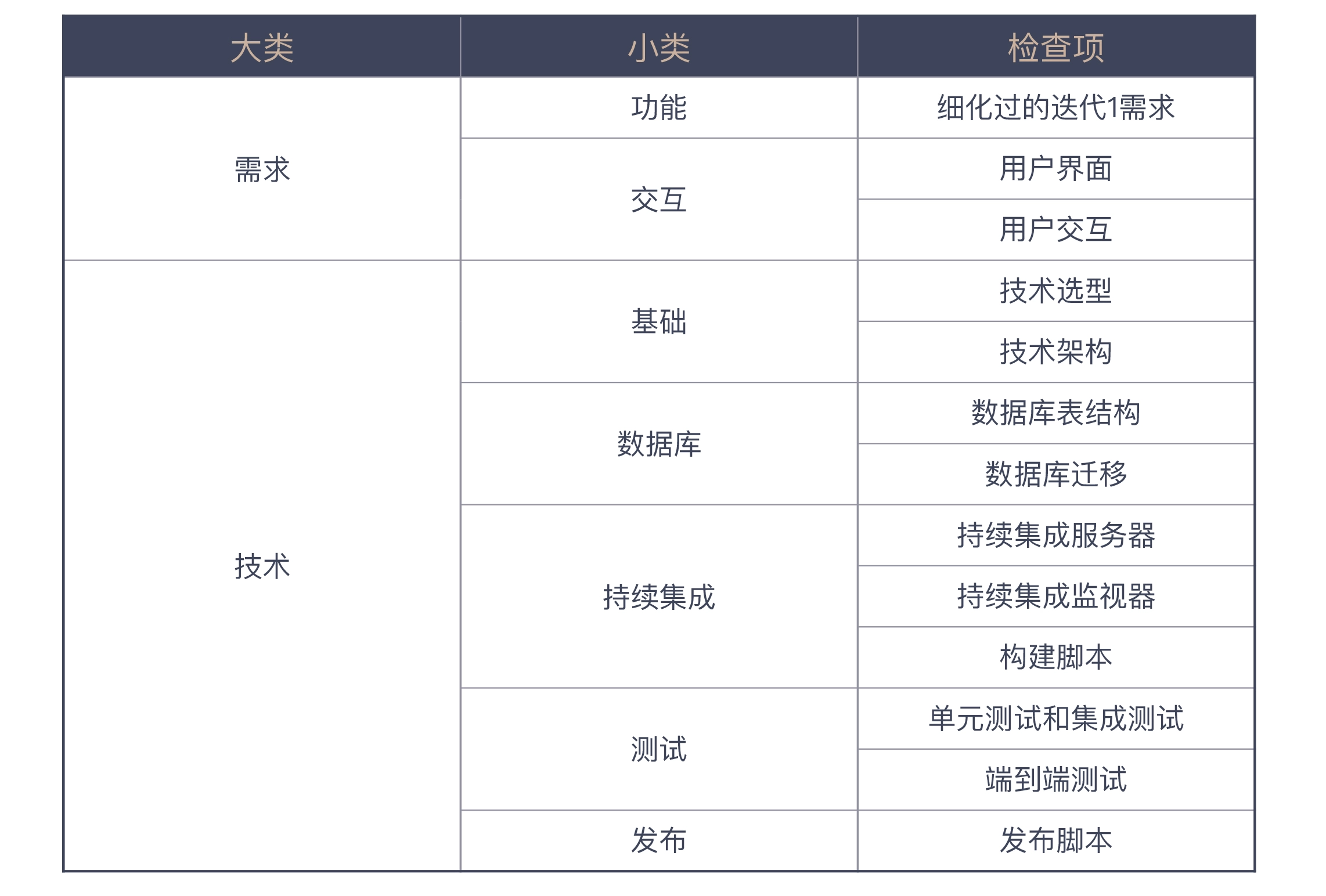
Compare this list to the fact that most new projects are under-prepared on one or more items. Even if you are not doing a project from scratch, comparing this list will reveal that the project is lacking in some items and you can make some targeted additions. If there’s only one thing you remember from today, remember this: design your Iteration 0 list and give your project a medical checkup.
Task Breakdown
Well, sharing these two examples with you is just to warm up and show that human problem solving solutions are pretty much the same. When a complex problem is presented to us, one of the main ideas we have to solve it is to divide and conquer.
A big question is one that we all struggle to give answers to, but answering small questions is something we excel at. So, when we learn to break down a problem, it is a big step toward its solution.
** So, what is the difficulty in solving problems with this mindset? Give an executable decomposition. **
However, in practice, most people overestimate their executable granularity and underestimate the degree of task decomposition. In other words, if you haven’t done the practice of task decomposition, most of the tasks you decompose will be on the large side of granularity.
Only if you can break down the task very small, you can have a clearer understanding of your ability to perform, the real masters are very strong decomposition ability. This difference is equivalent to, the same observation of an item, you use the eyes, while the master is using a microscope. In your opinion, the masters are all micro-operations.
**The software industry today is all about embracing change, and task decomposition is a prerequisite for us to embrace change. **
**In fact, the main reason why many people can’t write tests well is that they don’t understand task decomposition. **
Small things have a short feedback cycle, while big things have a long feedback cycle. Small things are easy to do well, while big things are much more difficult. So, with this criterion, it is easier to write good tests at the bottom level. In addition, because there are too many modules involved, any module that is adjusted may break the high-level test, so the high-level test is usually relatively fragile.
Test Driven Development TDD
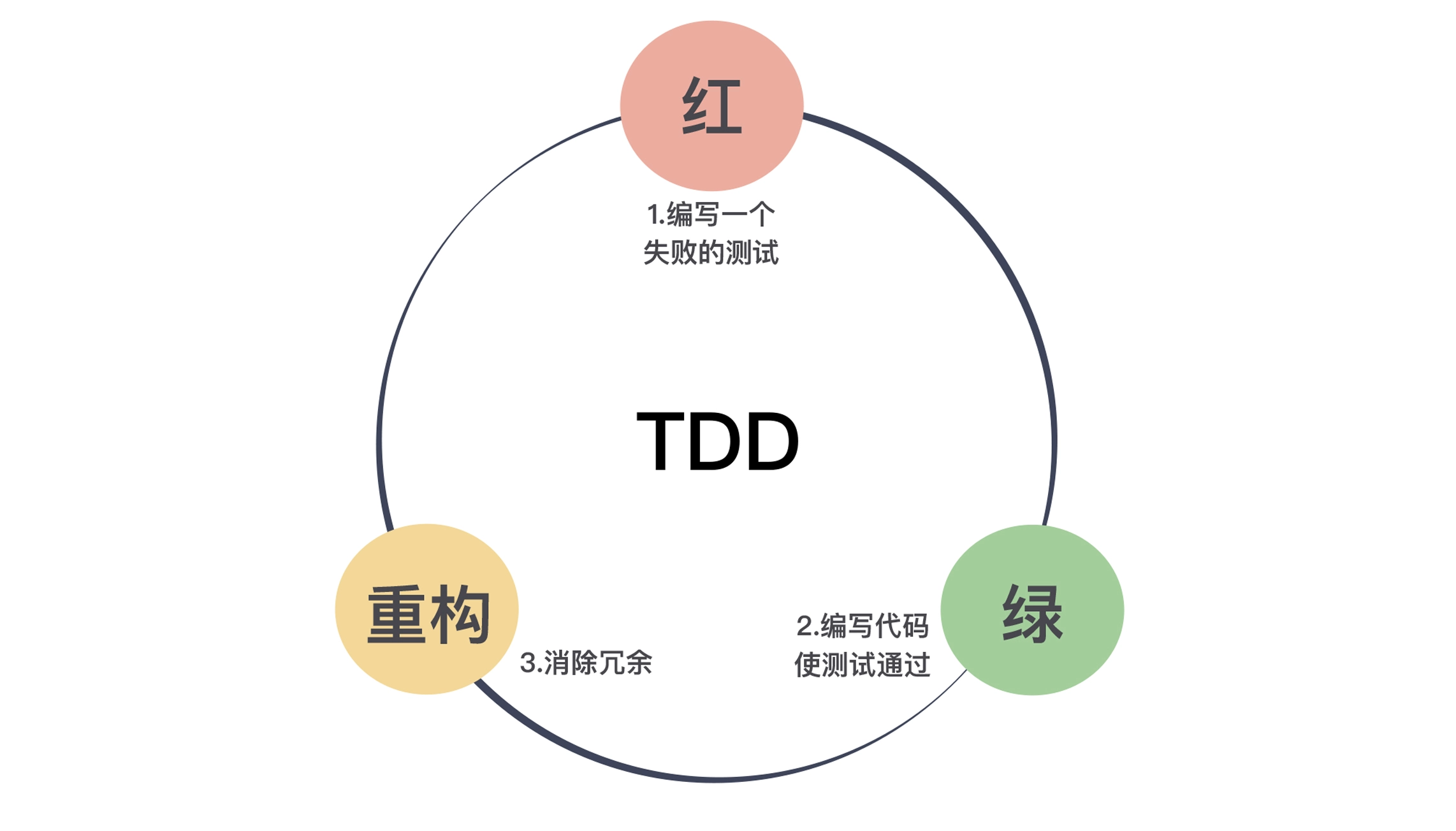
In test-driven development, refactoring and testing go hand in hand: without testing, you can only refactor in fear; without refactoring, the code is progressively more confusing and the tests become worse and worse to write. Because refactoring and testing work together, it drives you to write better and better code. This is the crudest understanding of the word “drive”.
Test Driven Design
There are two main reasons why many people resist testing:
First, testing requires an “extra” amount of work. I put extra in quotes here because, while you might instinctively think that testing is extra work, it should actually be part of the programmer’s job, as I mentioned in the previous article.
Second, many people will feel that there is too much code to test. The reason why these people think that the code is not good to test, which implies an assumption: the code has been written, and then, then write tests to test it.
If we reverse the thinking, I have a test, how do I write code that will pass it. **Once you think about the test first, the design thinking changes completely: how do I write my code so that it is testable, that is, we have to write code that has testability. With this perspective, doesn’t testing become easier?
Let’s take one of the most common problems in writing code: static methods
The Mock object approach doesn’t work with static anymore. Because it is outside the object system, static methods cannot be inherited, i.e., they cannot be handled in a series of object-oriented ways.
You don’t have a way to use the Mock object, and you can’t set the corresponding method return value. To get the method to return the corresponding value, you have to open the static method, understand its implementation details, carefully follow the path inside, and carefully set the corresponding parameters before you can get it to give you the expected result. Worse yet, because the method is maintained by someone else, one day he modifies the implementation on a whim and your carefully set parameters fall apart. And to do the setup again you have to reread the code all over again.
In this way, your work reverts to its original state. What’s more, it’s not what you should be focusing on, and it doesn’t add to your KPIs.
Obviously, you’ve gotten off track. By this point in the discussion you already know that static methods are not test friendly. So, if you want to make your code more testable, a good solution is to try not to write static methods.
static is a convenient but evil thing. So, limit its use. Unless your static method does not involve any state and has simple behavior, for example, determining whether a string is null. Otherwise, don’t write a static method. As you can see, such static methods are better suited for library functions. So, when we write applications on a daily basis, we try not to use them if we can.
What if you encounter a third-party static method in your own code? It’s simple, just wrap the third-party code so that your business code is facing your own wrapper.
How to do a good task breakdown
Finally, I want to emphasize one thing in particular, all the tasks that are broken out, are independent. That is to say, for every task done, the code is committable. Only in this way can we achieve a real sense of small step commits.
If there is only one thing you can remember from today, remember this: Arrange the decomposed tasks in the order of complete implementation of a requirement. **
**Why are your tests not good enough? **
I have seen many teams that have had a variety of problems with testing, such as
- Inconsistent testing, passing this time but not the next;
- sometimes it is a test to test something very simple, test around a lot of dependencies, build the environment will take a long time;
- For this test to run, it must wait until the other test has finished running; …
If you have encountered similar problems in your work, then what you understand by writing tests and what I understand by writing tests may not be the same thing, so where does the problem lie? Why are your tests not good enough? Mainly because these tests are not simple enough.
** Testing can only be done well if complex tests are broken down into simple tests. **
Why should testing be simple? There is an interesting logic, I don’t know if you have thought about it, what is the role of testing? Obviously, it is used to ensure the correctness of the code. An ensuing question is, who guarantees the correctness of the tests?
Since it is impossible to write a program in a way that guarantees the correctness of a test, we have only one solution: ** Write the test simple, so simple that it is easy to understand at a glance and does not need to prove its correctness. **So if you see any test written in a complicated way, it must not be a good test.
Test for bad taste
** Many people always want to do many things in one test, for example, there are several different method calls. May I ask, who exactly is your code testing? ** Once this test goes wrong, you need to look at all the several methods involved, which definitely adds complexity to the work.
Another area of high incidence of typical “bad taste” is in assertions, and remember, tests must have assertions.
There is another common “bad taste”: complexity. The most typical scenario is that when you see all kinds of judgments and loops in the test code, there is basically something wrong with the test. For example, testing a function, your assertion is written in a bunch of if statements, and the name is that it executes according to the condition. How do you guarantee that the test function is written correctly? Unless you use debugging means, you can not even tell whether your conditional branch is executed to. You may wonder, I have a whole bunch of different data to test, without loops or judgments, what do I do? What you should really be doing is writing several more tests, each covering one scenario.
A journey (A-TRIP)
How about a test that is considered a good test?
Someone made a summary A-TRIP, which is an acronym for five words, are
- **Automatic, automated; **leave the tests to be executed by machines as much as possible, the less human involvement the better.
- **Thorough, comprehensively; ** you should cover as many scenarios as possible with tests. There are two perspectives to understand this. One is to consider various scenarios before writing the code: normal, abnormal, various boundary conditions; the other perspective is that after writing the code, we have to see if the tests covered all the code and all the branches, and this is the scenario where various test coverage tools come into play.
- **Repeatable; **There are two perspectives in this: a particular test should be run repeatedly and the result should be the same, which says that each test itself should not depend on any environment that is not under control; there is another perspective that a bunch of tests should be run repeatedly and the result should be the same. This shows that there is no dependency between tests and tests, which is another feature of tests that we will talk about next.
- **Independent; **There should not be any dependency between tests and tests. For example, if a test depends on an external database or a third-party service, and Test A writes some values in the database when it runs, and Test B has to use those values in the database, Test B must run after Test A. This is called having a dependency.
- **Professional, professional. **
**How to cut the demand? **
If I ask you what this requirement is, for example, most people’s first instinct is still username password login.
Basically, the requirement description that pops into your head is the topic (epic), which in agile development some call the master story.
If the granularity of your management of requirements is the subject, then so many things can not be talked about. For example, when time is short and I want to cut requirements, you ask the product manager if it’s okay if I don’t do logins, and you wait for the rejection.
However, if you say time is tight, can I put the login captcha to the back, or the email address verification function to the back, this kind of suggestion product manager is able to talk to you.
The difference lies in the fact that the latter breaks down the requirements.
Needs to be broken down
“Themes” only help you remember the general direction, but the real use of requirements management relies on further decomposition of requirements. For this discussion, we’ll continue with the requirements description we’ve already described in the previous column: the user story, which will be the basic unit of our requirements management discussion here.
Evaluating user stories has an " INVEST Principle ", which is an acronym for six words, namely:
- Independent, standalone. A user story should accomplish a separate function and not depend on other user stories as much as possible, because user stories that depend on each other make it more difficult to manage priorities and estimate workloads. If dependencies do exist, a good practice is to break out the dependent parts and realign them.
- Negotiable. It is a prerequisite for working together. We can’t guarantee that all the details will be 100% implemented in the user story, so the best way to do this is to negotiate. It is also a prerequisite for meeting other judging criteria, as mentioned earlier, a user story is not independent and needs to be broken down, which also needs to be discussed together.
- Valuable, valuable. A user story should have its own value, this item should be the easiest to understand, no value of things not done. But as we have been saying, before doing any of these things, ask where the value lies.
- Estimatable. We will use the results of user story estimation to arrange the subsequent work plan. User stories that cannot be estimated are either because there are many uncertainties or because the requirements are still too large, such stories are not yet in a state where they can be developed and need further analysis by the product manager.
- Small, small. Big steps, no. User stories that can’t be completed in a certain amount of time should only have one result, split. A small user story is easy to schedule, so you can organize your work. testable. Who knows if you’re doing it right if you can’t test it. This is what we have emphasized earlier, that is, the acceptance criteria, you have to know how to be considered work done.
The first concern is negotiability. As implementers, we have to ask questions. Programmers who are just passive recipients are worth half as much, and as soon as you start asking questions, you’ll find a lot of things that the people who wrote the requirements didn’t think through.
Countless times in my career I’ve blocked requirements back, not because I wasn’t cooperative, but because I didn’t want to do something muddled. The reason I can ask questions is partly out of common sense, and partly whether the user stories described here are valuable. User stories, the reason they are stories, are to be told and communicated.
There is a more important concern, and one that is at the heart of this module: smallness. Whether it’s independent or estimable, the premise is small. Only when the user story is small enough, our subsequent room for maneuvering will be large. The next important question is, how to be considered small? This brings us to another important aspect of user stories: estimation.
Usually, it is the two sides that have a deviation in understanding the requirements, and then the colleague responsible for writing the user story has to step up and help clarify the requirements. So, in general, the estimation process is also a process for everyone to deepen their understanding of the requirements. Estimation has another important role: to discover particularly large user stories. In general, a user story should be completed within one iteration.
The real dilemma for many teams is the lack of requirements decomposition in the development process. In this case, the basic unit of requirements management is a theme, and since it is the basic unit, it is an indivisible whole. The team is then tied alive to a huge requirement with no room for maneuvering. If the team can decompose the requirements, the basic unit of requirements will be reduced, and everyone will no longer see the “ironclad” piece, so they can adjust more easily and have more room to move.
Demand Management
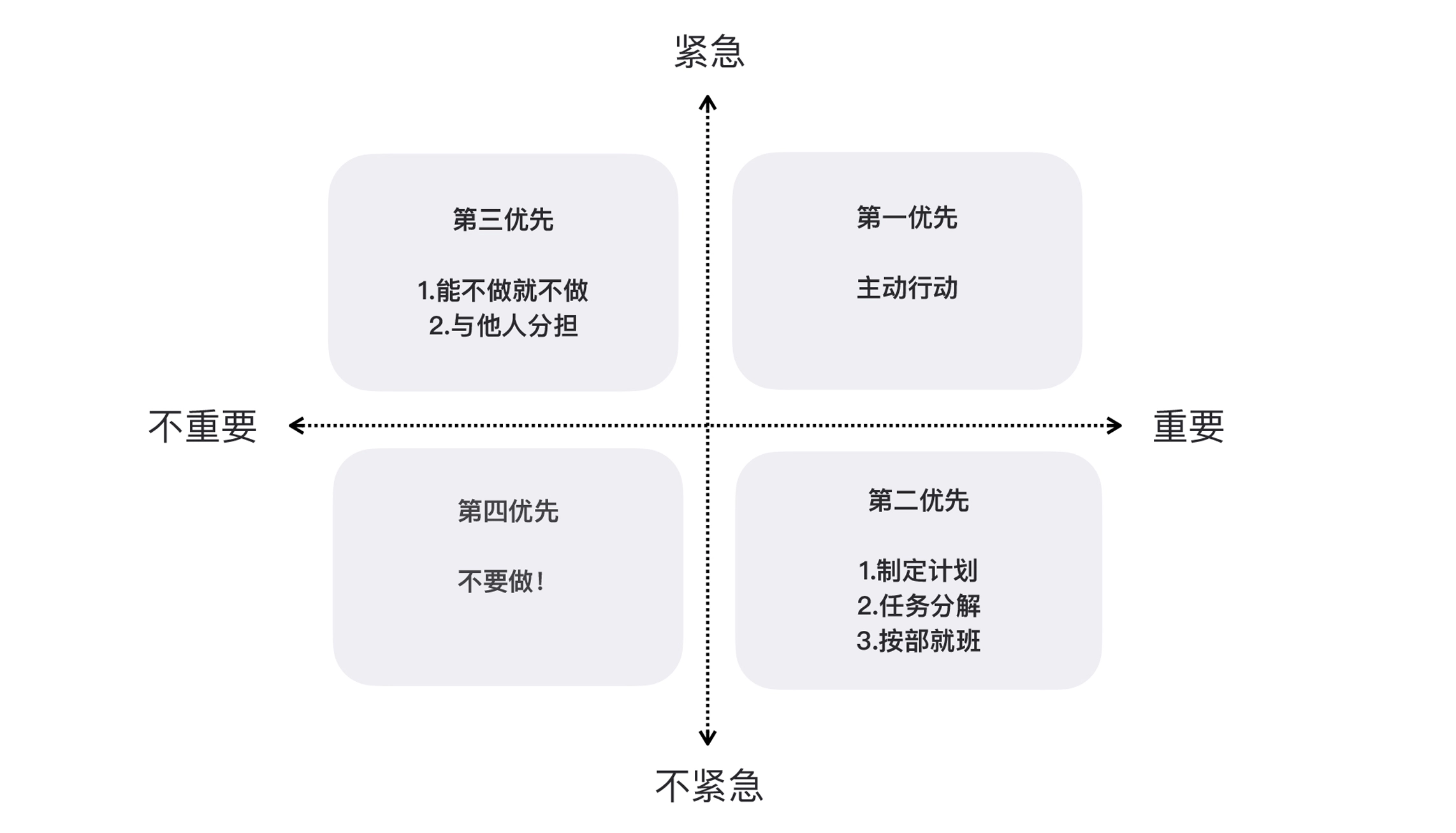
Use a few examples from the life of a programmer to help you understand. Let the system can not run properly online failure, it belongs to important and urgent things, do not rush to solve, it will affect the normal operation of the company. The team to upgrade the system transformation is important not urgent: transformation is good, performance is also good, maintainability is also improved; not transformation, a moment can also be used. Some temporary tasks are urgent and unimportant, while the brush of friends is neither urgent nor important.
According to the concept of time management, important and urgent things should be done immediately. The important but not urgent things should be where we focus our efforts. Things that are urgent but not important can be delegated to others. Things that are not important and not urgent should be done as little as possible. The biggest change this matrix brings to our thinking is the realization that things and things are not equivalent. If one does not focus on the important things, in the end they may all become urgent things.
Bringing this idea back to our reality of requirements management, you will find that in fact, the priority ranking used for the various requirements faced by the team is basically in order of urgency, but are they really important?
If you throw this question at the person who created the requirement, I’m almost certain that the answer they give you is that the requirement they created is important. One possibility is that they can’t tell the difference between important and urgent, just as we are sometimes confused.
Imagine two product managers show up in front of you, one tells you that the company wants to expand in a new direction and this feature has to be done, while the other says that the company wants to further profitability and that feature has to be done. To you, they both say the right thing, and both sound pretty important. But the bone-chilling reality is that you put both things next, and what awaits you is an exhausting task that can’t be completed. What can we do at this point? Jump out of this context and into a larger context. ** You can’t judge which need is more important, so ask a higher level boss to do so. **
A few more words of divergence, for people to do the same to constantly expand their own context, which is what we often say to increase knowledge. Many so-called life problems are caused by limited insight. For example, if you feel that there are always people in the company and you than the technology, such as the long-term vision, put yourself on the level of the whole industry to compare. Because you are working for your own career, not a company.
After the decomposition of the requirements, the most important thing is, to arrange the priority of the requirements. There are many ways to prioritize, we can take a cue from time management and divide things according to the dimensions of importance and urgency to get four quadrants. We need to focus on the important things as much as possible, rather than the urgent things as a way to prioritize.
Breaking down requirements into smaller pieces actually breaks down the context that was originally unified. If you want to manage requirements effectively, especially to determine how important things are,** one way is to retrieve the lost context**. If we can’t determine the context ourselves, a good way to do that is to bring in a larger external context.
How to make a product with minimum cost? **
Our instinct, of course, is to implement everything and then test it, but the world doesn’t stop and wait for us. Time and time again, we have been taught that “hold back” waterfall software development has become an anachronism. So how do we achieve our vision? The only way is to break it down.
As we mentioned earlier, Lean Startup is about validating product ideas in the real world through continuous experimentation, and one of the key practices is Minimum Viable Product (MVP), which we will discuss this time.
Let’s start with “minimal”. Here the “minimum” refers to the minimum cost. How to call the minimum cost, is not to do what can not do, can simplify things to simplify.
First of all, we must be clear about one thing, what we want to do is to verify the feasibility of an idea, not even to develop a software, developing software is just a means of verification.
Many programmers have a misconception that it is easy to treat the solution as a problem. We develop software for the purpose of solving problems, wouldn’t it be better if we solved the problem without writing the software.
The first step was to verify whether such an idea was feasible. We made a product document, as if we already had the product, and asked our sales colleagues to take the document to the customer to see how the customer reflected on the idea. In the process, we validated the basic idea that the need for IoT transformation of existing devices existed, and when customers saw such a thing, all kinds of ideas and requirements popped up. In addition, we gained an additional benefit, we knew the price range that customers would accept for such a product, which helped the team to price the product appropriately. Having validated the directional ideas, we moved on to the specific product design phase. What we wanted to verify in this phase was whether the product design we gave was acceptable to the users. So, we decided to make the interaction of this product. Thanks to the rapid development of prototyping tools, we made a relatively complete user interface with a prototyping tool and made all kinds of interaction flows. To the user, this is almost complete software.
After “minimal”, let’s look at “feasible”. ** Feasible is to find a path to give the user a complete experience. People who come from a programmer’s background always know software systems module by module, and the relatively weak aspect is the lack of a complete picture. But from the perspective of product viability, we need to shift our thinking, not a module to do how complete, and a user path is smooth
When time is limited, we need to learn to find a viable path to find a balance between a complete user experience and a complete system.
Step by step, we launched a relatively complete P2P platform. In this process, we put new features on line at each stage, and from the user’s visible point of view, what he sees is always a complete platform, the changes of which can only be seen clearly from the perspective of the internal implementer. (For example, the repayment function, although it is one of the complete life cycle, no user will use it in the first month, so the scheduling can be a bit later)
To use the concept of minimum viable product well in practice is to find a viable path at minimal cost. **Minimal cost means not doing what can be done and simplifying what can be simplified. **
Programmers are usually willing to solve problems with their own code, and writing code is usually a very costly solution, which should be the final product solution. The path that works is a complete user experience path, at least in the eyes of the user.
We often want to give our clients a complete system, but with limited time, we must learn to break it down.
If there’s only one thing you can remember from today, remember this: the most viable way to do good product development is to use MVP.
In this module, we learned some best practices:
Test Pyramid
– Best practices for testing portfolios in the industry.
– Writing more unit tests is key.
Test Driven Development
– The rhythm of test-driven development is: red - green - refactoring, refactoring is the key to test-driven development area different from test first.
– Some people understand test-driven development as test-driven design, and it brings a change in thinking to the industry to write testable code.
Eisenhower Matrix (Eisenhower Matrix)
– Divide things according to importance and urgency.
– The important and urgent things should be done immediately. The important but not urgent things should be where we focus our efforts. Things that are urgent but not important can be delegated to others. Things that are not important and not urgent should be done as little as possible.
Minimum Viable Product
– products that are “just right” for our customers’ needs.
– in practice, to find a viable path at minimal cost.
In addition, I mentioned a number of practices and rubrics that can be applied directly in the workplace:
- Try not to write static methods;
- A master branch development model as a better development branch model;
- Good user stories should conform to the INVEST principles;
- Estimation is a process of deepening understanding of requirements, and good estimation is based on task decomposition;
- A good test should comply with A-TRIP.
I’ve also taken you through some important ideas to help you better improve your own development work::
- Divide and conquer, a basic human problem-solving tool;
- Software change costs, which increase over time and in development phases;
- Testing frameworks that introduce automated testing as a best practice into the development process, allowing testing actions to be fixed by standardized means;
- Extreme programming is called “extreme” because the idea behind it is to push good practice to its limits;
- The secret of the master programmer’s work is task decomposition, down to the micro-operations that can be performed; arranging development tasks in the order of complete implementation of a requirement.
Communication Feedback
We work hard to learn all kinds of knowledge in order to better understand how the world works, and communicating feedback is the best way for us to interact with the real world.
When several people discuss a problem together, someone else often just starts a conversation, he thinks he has understood the idea of others, and then starts to express his own point of view. The information is incomplete, so how can we talk about decoding. So, development team discussions often involve one person talking about something but getting off topic. We have to accept feedback from the real world if we want to make our work life better, and accepting feedback from the real world requires us to, first, open our own receiver to accept the signal in and let the feedback in, which is the premise of decoding; second, expand our insight and improve the effect of our decoder to better understand what others want to express in the end. Having said that the encoder and decoder may have problems, let’s look at another problem that may cause impact: codec algorithm, that is, how to coordinate the two sides of communication to communicate more effectively.
Life is not as good as it should be. A big reason why many people have so many bad things is that we have a lot of unrealistic fantasies about the real world, and good intentions do not drive the world, and this is also true in software development. Although people and people live in one world, their understanding of the world is very different.
Improving codecs requires several perspectives: encoders, which allow for more accurate information output; decoders, which reduce signal filtering and improve decoding capabilities; and codec algorithms, which are various “best practices” from the industry that coordinate both sides of the communication.
Write code in the language of the business, one is highly readable, the other is able to identify the constant and changeable parts of the code, better practice design patterns, and achieve domain-driven design
Lightweight Communication
The meeting is to solve the problem, but the real situation is to open the meeting and did not solve many problems, this is a strange contradiction. Thinking back, have you ever attended a meeting that worked particularly well? In my career, where the effect of the meeting is particularly good, basically used to do information synchronization. For example, the leader announces a thing, this kind of meeting will hardly waste time. The message is announced, everyone receives it, and it ends. And what is a bad meeting like? Almost all of those discussions, you say one thing and I say another, each meeting almost without exception, there are a few good at interrupting, this meeting will basically run out of time, the time will be so minute by minute.
The first action item to improve the meeting is to reduce the number of people involved in the discussion. Some people will say, "I have several topics for this discussion, and each topic requires different people to participate, so what you need to do is to find these people separately to discuss specifically, instead of putting everyone together. Compared to the meeting format, face-to-face communication is not possible because of the limited attention span and the number of participants is not too large. Also because the number of participants is relatively small, each person’s input will be a little more.
**The second action item is, if you want to discuss, find people to communicate face to face. **If there is an issue that needs to be discussed, what I want to do is to find the relevant people to discuss it separately for the topic of concern, and then, I will summarize the results of the discussion and then go back to seek everyone’s opinion. If everyone agrees, I will choose to meet only. This time, ** the purpose of the meeting is no longer a discussion, but a synchronization of information **: I am ready to do so, the relevant parties have agreed, to inform everyone, end.
Try to communicate in a more visual way.
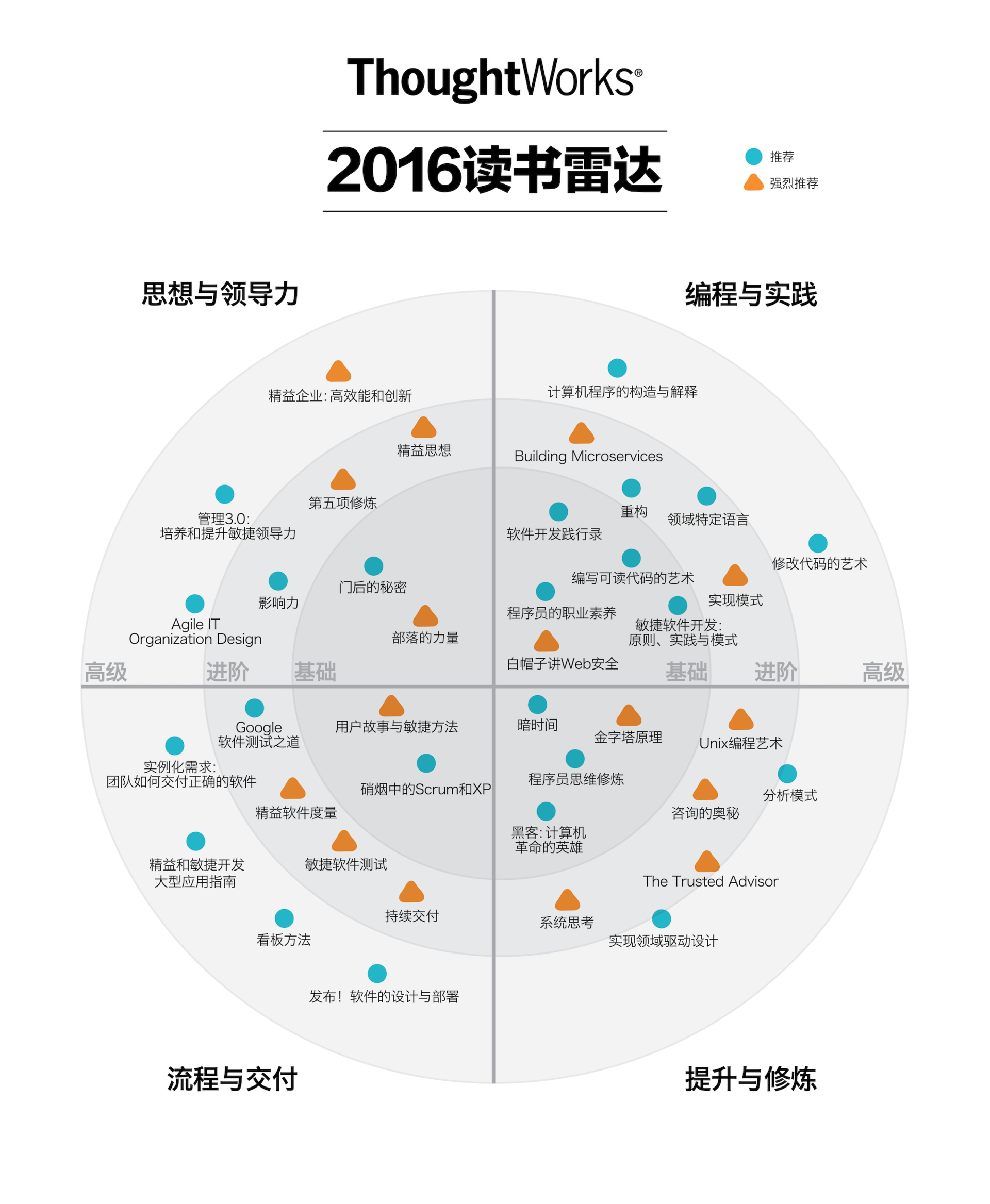
The birth of continuous integration is the result of people trying to shorten the integration cycle. Why shorten the cycle time? Because we want to get feedback as early as possible to know if the results of our work are working. So, to do continuous integration well, you need to go along with the essence of continuous integration: getting feedback on your work as soon as possible.
From there, we get to the key point of continuous integration, you just have to remember the phrase, quick feedback.
Quick feedback, this sentence is divided into two parts, quick and feedback, which leads to two important goals of continuous integration: how to get feedback quickly, and what kind of feedback is effective.

What is replay? A replay is a Go term that means that after a player has played a game, he replayed the game to see what went well, what didn’t go well, what could have been played differently or even better, etc. This way of restoring the process and discussing and analyzing it is a replay. This way of restoring the process, discussing and analyzing it, is replay.
Nowadays, the concept of review has been used in many aspects, such as stock market review, business management review, and it has become the most important tool for many people to help individuals and enterprises to continuously improve. The most famous one is Liu Chuanzhi, the founder of Lenovo, who even wrote “review” into the core values of Lenovo. Why is it so useful to review? In my opinion, there is an important reason, lies in the objectification. As the saying goes, the authorities are confused, the onlookers are clear. Using our software development as an example, when solving a problem, we focus more on the problem itself and rarely think about how the problem was caused. **When you review the problem, you will stand in a different perspective to think about what caused the problem. At this time, you are no longer the person involved, but have become a bystander. **You observe the process of how that original thing happened, as if someone else was doing it. You go from a subjective perspective to an objective one. Seeing things from someone else’s perspective is objectification.
If your team can see the root cause at once is good, but if not, then it is best to ask more why. How to ask, there is a common practice is: 5 Whys (5 Whys). This practice was introduced by Saji Toyoda, the founder of the Toyota Group, and has since become widely known with the Toyota Production System. Why do you need to ask more whys? Because the initial question, you can get only the surface reason, only a few more whys, you can find the root cause. Let me give you an example. The server often returns 504, so we can use the “5 Whys” approach to ask.
- Why is there a 504? Because the server takes longer time to process and timeout.
- Why does it time out? Because the Redis behind the server query is stuck.
- Why is accessing Redis stuck? Because another service updating Redis deleted a large amount of data and then, when it was reinserted, the server blocked.
- Why does it delete data in bulk and reinsert it? Because the update algorithm is not designed properly.
- Why does an ill-designed algorithm go live? Because this design was not reviewed according to the process.
More close to the user, in order to understand what their code is used to do, but also in the discussion of requirements to better understand which needs are necessary
As a programmer, overcoming technical challenges is an important part of our job, so we subconsciously throw ourselves into them as soon as they arise. But is this really the best approach? Not really, **not all problems are technical challenges worth solving. **
There is an important principle of writing programs called Fail Fast, what does this mean? It means that if you encounter a problem, report the error as early as possible.
What are you going to do if the configuration file is missing an important parameter, for example, the maximum number of database connections? Many people will choose to give a default value, which is not a Fail Fast approach. Since it is an important parameter, reporting an error if it is missing is called Fail Fast.
In fact, Fail Fast also smacks of something counter-intuitive; many people are compatible with a lot of weird problems on the grounds of building robust systems, rather than exposing it. Instead, they hide the bugs in the system. We all know that relying on debug to locate problems is one of the most time-consuming and costly practices. So, don’t be afraid to report problems with the system early.
Automation
In my opinion, it is important to do what is valuable, not just what is “done”, but also what is valuable in terms of time and cost savings by “not doing”. Two of my colleagues prevented the client from wasting money, so I view this project as a success.
For development, the same reasoning is followed. Programmers as a group are so technically competent that it is simply too intuitive to make a technical solution, we just faithfully make one requirement after another and automate “the world”. **But the truth is, too much of the world’s waste is doing things that shouldn’t be done. In our column, I repeatedly say that we need to ask more questions in order not to do things that we shouldn’t do.
Beware of NIH syndrome
You can judge from the perspective of the requirements of which work can not be done, but we also want to prevent programmers themselves “add drama”, I will tell you a common problem of technical personnel: NIH syndrome (Not Invented Here Syndrome).
For example, this kind of chaos in the field of front-end also appeared, a variety of frameworks, so many front-end programmers cry, really can not learn. Another example is that I once interviewed a programmer who had contact with Go earlier, and he just couldn’t wait to write all the frameworks himself.
Having said that, it’s just to illustrate one thing Before writing code, ask yourself if you really want to do it? Don’t do it if you can, until you have enough reason to do it. ** Corresponds to Larry Wall’s statement that you have to be lazy and put a lot of effort into circumventing the energy drain.
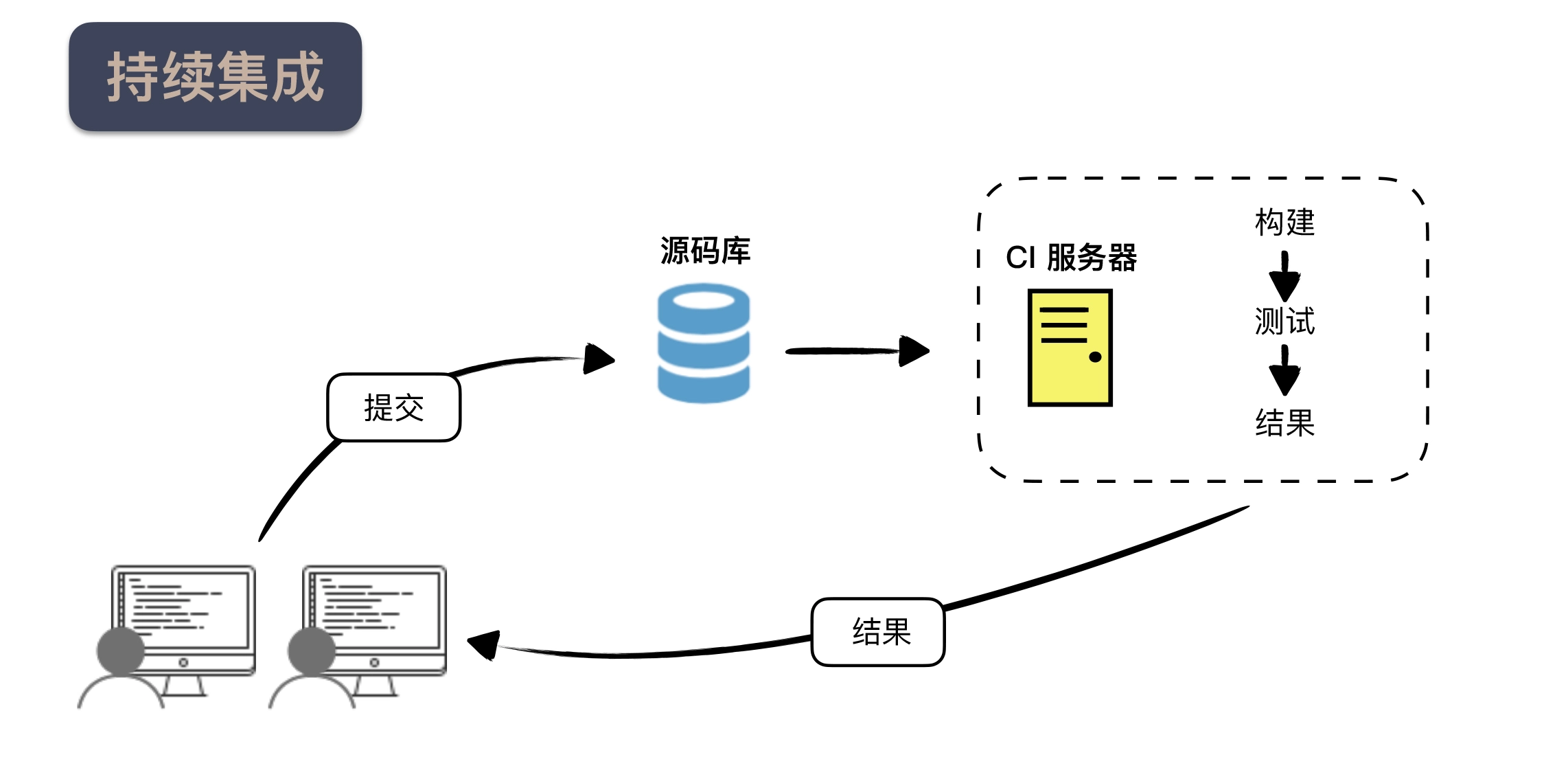
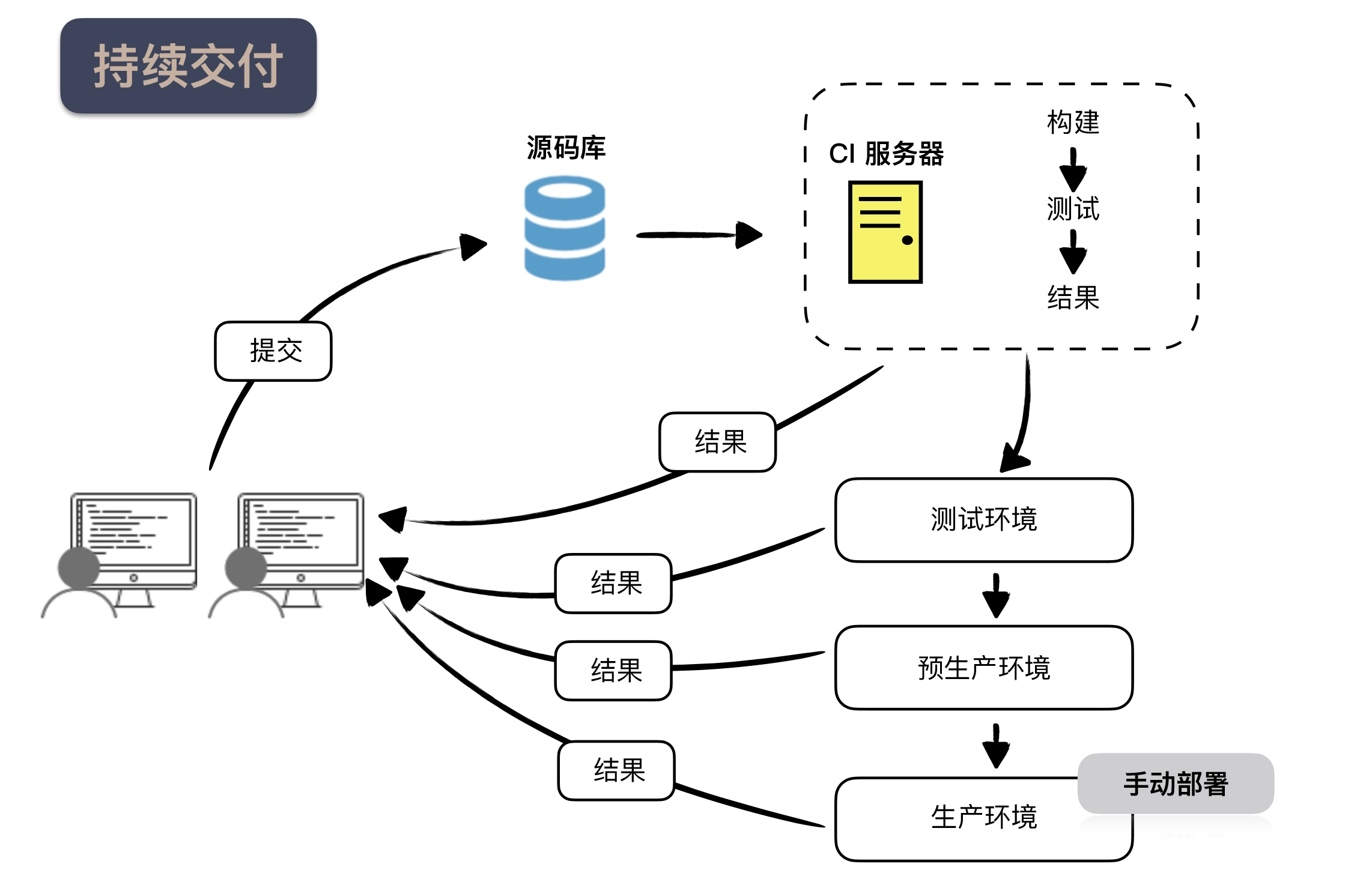
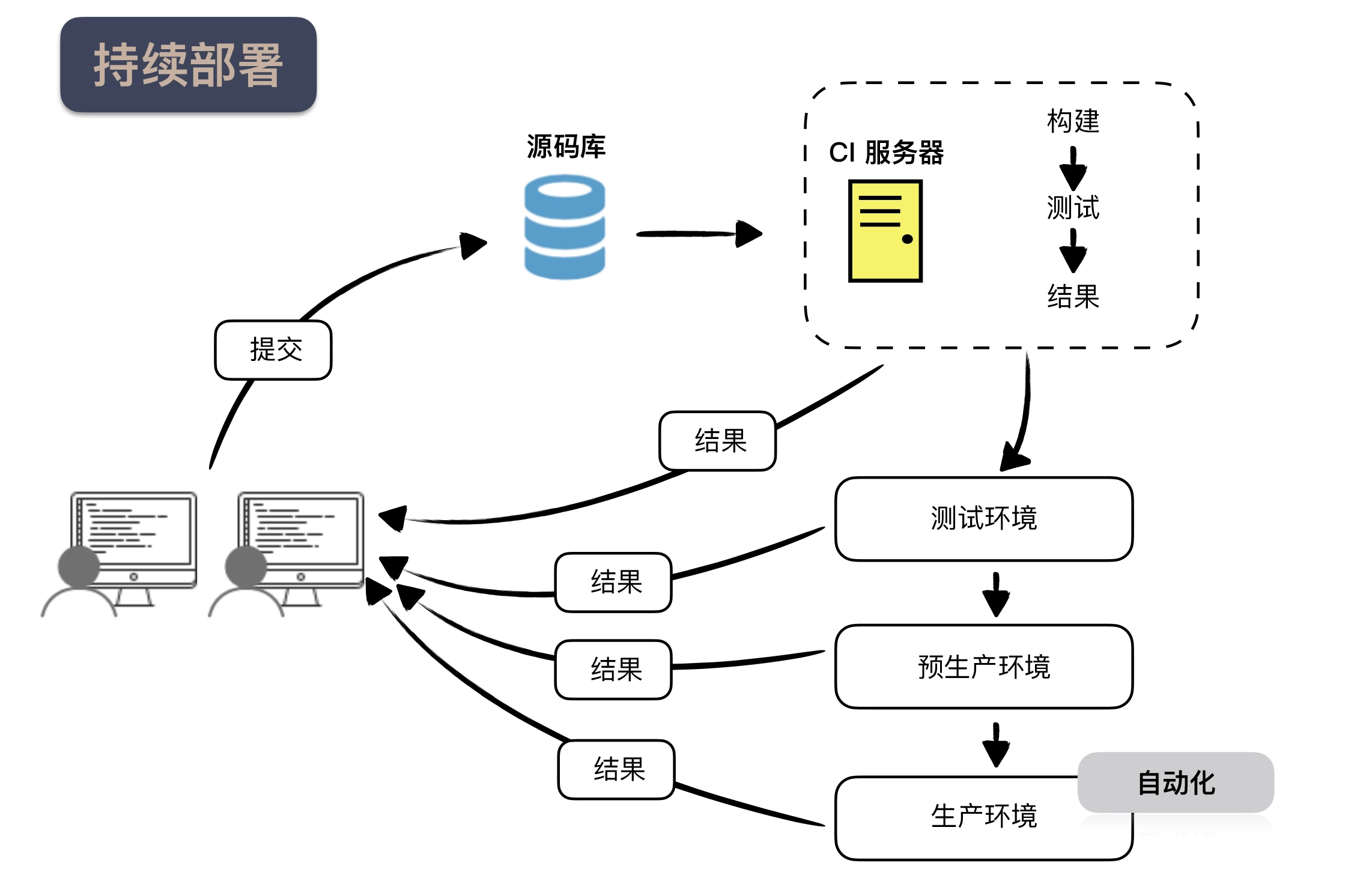
In general, there are several different environments when building an infrastructure for continuous delivery, as described below.
- Continuous integration environment, continuous integration is a prerequisite for continuous delivery, this process is mainly to perform basic checks and hit a package that can be released.
- Test environment (Test), this environment is often stand-alone, mainly responsible for functional verification, where the tests run are basically acceptance test level, and generally put the unit tests and integration tests and other tests that are executed faster into the continuous integration environment to execute.
- pre-production environment (Staging), this environment is usually the same as the production environment configuration, for example, load balancing, clustering and so on should have, but the number of machines will be less, is mainly responsible for verification of the deployment environment, for example, can be used to find some problems brought about by the concurrency of multiple machines.
- production environment (Production), which is the real online environment.
Ensure your code is not too confusing: the SOLID principle
Today, we start with a segment of the software industry. Party A wants to do an e-commerce website, as party B programmer asked: “What kind do you want to do?” Party A said, “Like Taobao is good.” The programmer asked, “How much are you going to pay?” Party A thought about it, “50,000 yuan is about right!”
This is, of course, a flirtation with the customer does not understand the requirements of the paragraph, but have you ever thought, ** Why in the A does not seem to be a complex system, you find it difficult? Because what you want is simply not a thing**.
In the customer’s opinion, what I want is a website where I can buy things. As long as the product can be online, the user can see and buy it, 50,000 yuan is almost enough.
And what you think in your head is, “Taobao ah, that has to be a big technical challenge ah, every year to the ‘double 11’, that will have to consider all kinds of concurrent snapping. Taobao has to have how many programmers, 50,000 you want to do a, the door is not.”
When doing a new project, it is not necessary to consider too many imaginary needs, the most important thing is to do two things well
- **analysis of requirements, good domain division and abstraction (the higher level of abstraction the more stable, the more detailed things are easy to change), to ensure the scalability of the architecture **
- ** Minimize the introduction of various frameworks, or to ensure that the framework is pluggable and can be quickly replaced **
Reviewing the above process, you can see that each time the original technology cannot meet the needs as the business volume grows, so it is necessary to solve the problem with new technology. The key point here is: different business volumes.
A system that serves only a few people, a single machine is enough, and a programmer just starting out can implement this system very well. When the volume of business reaches the point where a single machine cannot resist, it needs to be handled by multiple machines, and this time the problem of distributed systems must be considered, and middleware may have to be introduced appropriately. And when the system becomes to provide services for a huge amount of business, there is no which has been built to help the middleware, need to solve the problem from the bottom themselves. Although these systems seem to be the same in business, in technical terms, a system faces different problems at different stages, because it faces different levels of business. To be more precise, systems of different magnitudes are not a system at all.
In the previous example, the real driver for Taobao’s engineers to improve the system is not the technology, but the complexity of the problem due to the escalating business volume. Therefore, assessing the current stage of the system and using the appropriate technology to solve it is the most important thing we should consider.
**Then remember: use simple techniques to solve problems until they become complex. **
Maybe you’ll say, what if I make a system that doesn’t have that much business and I still want to improve my skills? The answer is to go to a place where there are good problems. Nowadays, the IT industry offers many opportunities for programmers, and it is not difficult to find a place with good problems, but of course, the prerequisite is that you have the basic ability to solve problems yourself.
How to do microservices
Let’s start by answering the question, why do we want to do microservices? The standard answer to this question is that microservices are small enough, easier to understand in code, easier to test, and simpler to deploy compared to monolithic services (Monolithic). All of this makes sense, but it is the result of doing microservices well.
How can we get to this state? There is a key factor, how to divide microservices, that is, how to decompose a huge system in a way. This is the most lacking in many discussions about microservices, and is the fundamental reason why many teams do “microservices” but die hard.
Without understanding this, write services that either call each other from service to service, causing the whole system to execute very inefficiently, or you need to spend a lot of effort to solve the data consistency between the various services.
**In other words, a poorly delineated service awaits the team in an endless quagmire of contingent complexity. Only when microservices are delineated correctly will it be what you have in mind to aspire to. **
** And how should you divide microservices? You need to understand domain-driven design. **
Domain Driven Design (DDD) is a methodology proposed by Eric Evans for moving from systems analysis to software modeling. What is the problem it is trying to solve? It is to transform business concepts and business rules into concepts and rules in software systems, so as to reduce or hide business complexity and make the system more scalable to cope with complex and changing real business problems.
**What exactly does DDD say? It pulls your starting point of thinking from a technical perspective to the business. **
We’ve mentioned this many times in this column. DDD is based on the Ubiquitous Language, which allows business people to speak the same language as programmers. This is something I mentioned in "21 | Who do you write code for? I’ve already mentioned this in 21 | Who do you write code for? Using a universal language is the same as pulling the level of thinking from the code details to the business level. The higher the level of abstraction the more stable it is, and the more detailed it is the more likely something will change.
With a common language as the foundation, it is time to move on to the practical aspects of DDD. DDD is divided into Strategic Design and Tactical Design. DDD is divided into Strategic Design and Tactical Design.
Strategic design is the high-level design that helps us divide the system into different domains and deal with the relationships between them. I gave you the example of “orders” and “users” in the previous section. This is the fundamental solution to the problem, otherwise, no matter how well you write your code, confusion is inevitable. And this way of thinking in terms of business is what DDD strategic design brings to me. Tactical design, usually refers to how to organize different domain objects within a domain at the technical level. As an example, domestic programmers like to use myBatis for data access instead of JPA, the common reason is that JPA has too poor performance in case of association. But the real reason is that the associations are not designed well.
After all, what does this have to do with microservices? The real difficulty of microservices is not the technical implementation, but the business segmentation, which happens to be the strong point of Bounded Context in DDD strategic design.
Although a common language bridges the gap between business and technology, computers are not good at dealing with ambiguous human language, so a common language must be expressed in a specific context to be clear. Like the “order” example we talked about, the “order” of a transaction is different from the “order” of logistics, and they both have their own contexts, and that context is the bounding Context.
It delimits the boundaries of the free use of the common language, and once outside the boundaries, the meaning is not guaranteed. It is because of the boundary that a bounded context can become just a separate deployment unit, and that deployment unit can then become a service.
** So to do microservices well, the first step should be to identify the bounding context. **
As you can see, each bounding context should be independent, and there should not be a lot of coupling between each context. The large number of mutual invocations between microservices that plague many people is itself a pseudo-proposition brought about by a failure to delineate the boundaries, relying on technology to solve business problems, with half the effort.
With a bounded context you can do microservices, right? Wait a minute!
In my humble opinion, it is not very easy to draw the boundaries clearly at once. It is much easier to adjust when everyone is in one process. Then, let the different bounding contexts evolve independently on their own first. Wait for it to evolve to the point where it’s worth deploying independently, and then think about microservice splitting. By then, you’ve also learned all sorts of techniques about microservices that should come in handy!
DDD and lean startup, microservices division is similar, both need to delineate the contextual boundaries, cut with the simplest way to achieve the needs of the moment, and then gradually expand (need good design to ensure scalability) lean startup is actually a continuous validation, verify the validity of the idea, to obtain the validated knowledge (Validated Learning).

If you understand the business, you can deduce the basic code structure yourself. But conversely, if you are asked to look at the code and deduce the business from it, it is almost impossible.
In fact, every time I learn about a business, I go over in my head how I would do it if I were doing it. This way, I will have a preconception on the whole first, and then correspond to the actual code later, so it will not be so strange. To understand the business, I usually ask someone to tell me what the business does, what kind of problem it solves, what the specific business process is like, and so on.
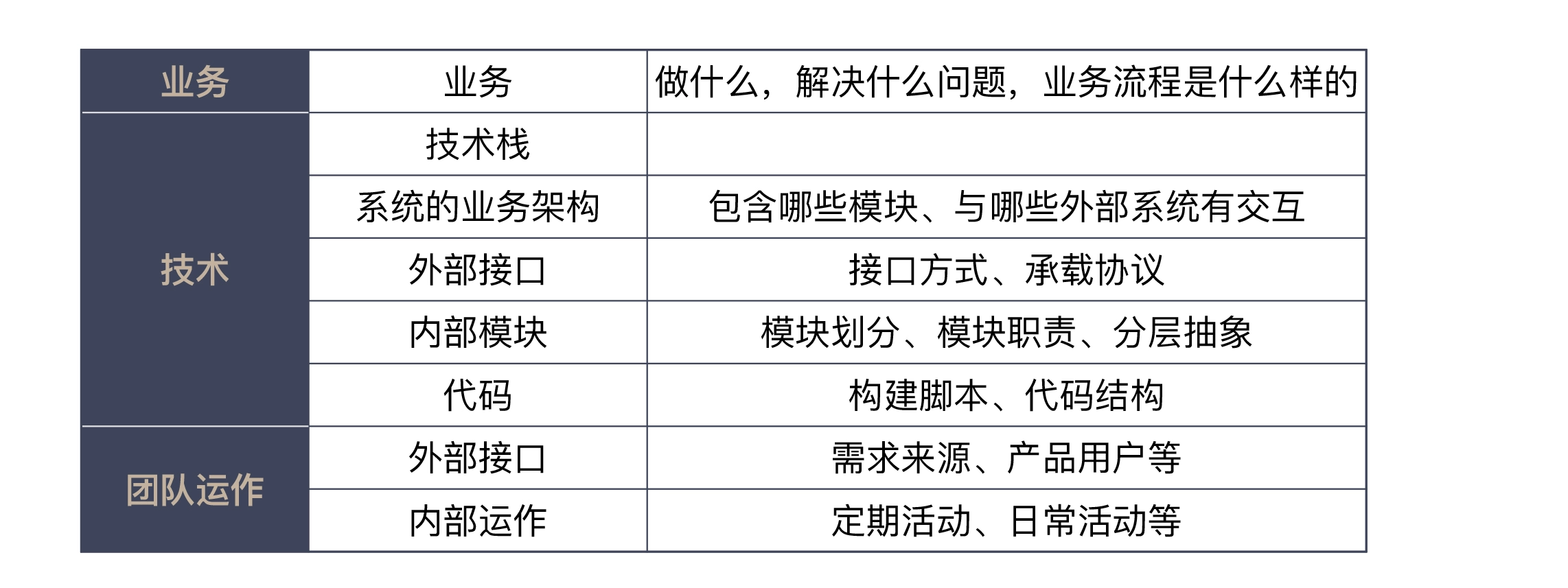
To revamp the legacy system, I will give you a few suggestions:
- building a test protection network to ensure consistent functionality of old and new modules;
- divided into small pieces and gradually replaced;
- constructing a good domain model;
- Find the latest understanding of system building in the industry.