Introduction to TCP Protocol
Features
- TCP is a connection-oriented transport layer protocol. That is, a TCP connection must be established before an application can use it. After the data is transferred, the TCP connection must be released.
- Each TCP connection can only have two endpoints, and each TCP connection is point-to-point.
- TCP provides reliable delivery service, which means that data is error-free, not lost, not duplicated, and arrives in order.
- TCP provides full-duplex communication, allowing both sides of the communication to send data at any time.** Both sides of TCP have a send cache and a receive cache**, which are used to temporarily store data for both sides of the communication.
- Byte-stream-oriented The term "stream " in TCP refers to the sequence of bytes** flowing into and out of a process. Byte-stream oriented means that although the application and TCP interact one block at a time, TCP sees the data handed off by the application as just a sequence of unstructured byte streams. TCP does not know the meaning of the byte stream being transmitted, nor does it guarantee that the size of the block received by the receiver corresponds to the size of the block sent by the sender. It is possible to send and send 10 blocks of data to the upper layer and have it organized into 4 blocks on the receiving side.
TCP and udp use a completely different approach when sending messages. TCP does not care how long messages are sent by the application process to the cache of the TCP connection at a time, but decides how many bytes each message should contain based on the window value given by the other side and the current network congestion (the message length of UDP is given by the application process, and the messages given by the application process, UDP just (simply add the header and pass it to the next layer).
My current understanding is that after the upper layer deposits the byte stream into the cache in multiple blocks of different sizes, TCP will re-cut the byte stream to send messages based on window values, congestion conditions, etc., just to ensure that all bytes eventually arrive in order.
What is a TCP connection
TCP uses connections as the most basic abstraction, and many of TCP’s features are built on this connection-oriented foundation, so we need to figure out what a TCP connection really is.
Each TCP connection has two endpoints, also called sockets or sockets, which are actually port numbers spliced together behind an IP address; the endpoint of a TCP connection is a very abstract socket, and the same IP address can have multiple different TCP connections, while the same port number can appear in multiple different TCP connections. A socket-based abstraction.
My current understanding of why TCP is connection-oriented is this:** A TCP connection requires a port on both sides of the connection, and during that time, the data transmitted on that port belongs only to the TCP connection, so it is like a link for both sides, but it does not mean that all routers between TCP connections have to do anything special for that connection. **
When you read the following content, if you have the question: What makes TCP designed this way to achieve this effect, think about its connection-oriented feature.
Principle of reliable transmission
The network beneath the TCP protocol provides unreliable transport, so TCP must take steps to remedy some of the surprises and make transport between transport layers reliable.
Stop waiting protocol
The Stop and Wait protocol is very simple.
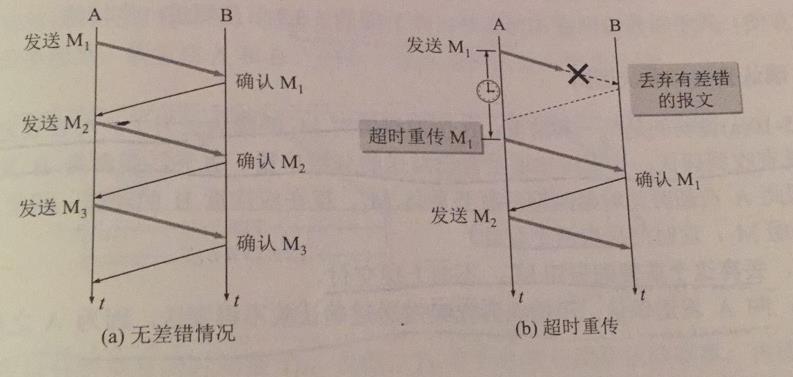
A pauses after sending packet M1 and waits for an acknowledgement from B. B sends an acknowledgement to A when it receives M1, and A continues with the next packet M2 after receiving an acknowledgement for M1.
There is an error. B detects an error when it receives M1 and simply discards M1** and then does nothing**. A assumes that the packet just sent is lost as long as no acknowledgement is received for a period of time, and thus retransmits the packet sent earlier. This is called a timeout retransmission. To implement timeout retransmission, you must set a timeout timer for each completed packet sent, and if an acknowledgement is received before the timer expires, the timer is revoked. There are three points to note here:
- A After a group is sent, a copy of the sent group must be temporarily stored until an acknowledgement is received before it can be deleted.
- Both the subgroup and the acknowledgement subgroup must be set up with numbers so that we know which subgroup received the acknowledgement and which did not.
- The timeout timer is set for a retransmission time that should be slightly longer than the average round trip time of the data during packet transmission.
Lost acknowledgement and late. If the acknowledgement to M1 sent by B is lost and A does not receive an acknowledgement within the set timeout period, there is no way to know if the packet it sent was in error, lost, or if the acknowledgement sent by B was lost, so after the timeout timer expires A has to retransmit M1, assuming that B receives M1 once again, and takes two actions:
- This duplicate packet M1 is discarded and not delivered to the upper layer.
- Send the delivery confirmation to A again, and you cannot assume that a confirmation that has already been sent will not be sent again.
Channel Utilization. The advantage of the stop-wait protocol is its simplicity, but the disadvantage is that the channel utilization is too low
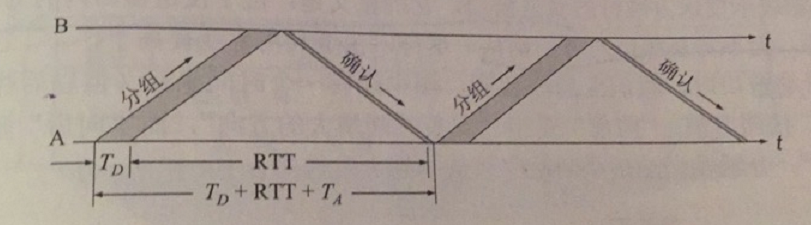
Assume that the time required for A to send the packet is TD, which is obviously equal to the packet length divided by the data rate. Further assume that the processing time is negligible after the packet arrives correctly at B, while the acknowledgement is sent immediately. Assume that B takes time TA to send the acknowledgment packet. if A also takes negligible time to process the acknowledgment packet, then A can send the next packet only after time (TD + RTT + TA) has elapsed. Since only useful data is used for transmission within TD, the channel utilization U can be expressed as
To improve transmission efficiency, instead of using the inefficient stop-and-wait protocol, the sender can use pipelined transmissions. Pipelining means that the sender can send multiple packets in succession without having to stop after each packet to wait for an acknowledgement from the other side.
When using pipelined transfers, continuous ARQ protocol and sliding window protocol are used.
Continuous ARQ protocol

The above figure indicates the sending window maintained by the sender, which means that all 5 packets located in the sending window can be sent out consecutively without waiting for an acknowledgement from the other party.
When discussing the sliding window, we should note that there is also a time coordinate in the graph. By convention, forward refers to the direction of increasing time, while backward refers to the direction of decreasing time. Grouped sends are sent from the smallest to the largest group number.
The continuous ARQ protocol specifies that the sender slides the sending window forward one packet position for each acknowledgment received.
The receiver generally adopts the cumulative acknowledgement method, which means that instead of sending an acknowledgement for each packet received, the receiver receives several packets and sends an acknowledgement for the last packet that arrives in order.
TCP message segment header
Although TCP is byte-stream oriented, the data unit transmitted by TCP is the message segment. A TCP message segment is divided into two parts, the header and the data, and the entire function of TCP is reflected in the role of the fields in the header. Therefore, only by mastering the role of each field in the TCP header can you master the working principle of TCP.
The first 20 bytes of the TCP header are fixed, and the next 4n bytes are options to be added as needed.
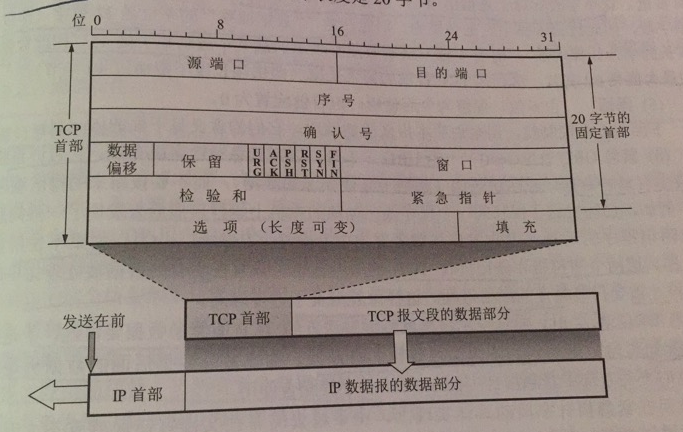
Source and destination ports
Each takes up two bytes and writes the far port number and the destination port number, respectively.
Serial number
It takes up four bytes, and the range of serial number is [0, 2^32 - 1], and after the serial number increases to the maximum, it is using the modulo operation.
Each byte in a stream of bytes transferred in a TCP connection is numbered sequentially. The starting serial number of the entire stream of bytes to be transmitted must be set at connection establishment. The sequence number field in the header refers to the first byte sequence number of the data sent in this message segment.
Confirmation number
It takes up four bytes and is the sequence number of the first data byte of the next message segment expected to be received from the other party. For example, B correctly receives a message segment from A with a sequence number field value of 501 and a data length of 200 bytes, which indicates that B correctly receives the data sent by A up to sequence number 700. Therefore, B expects A’s next data number to be 701, so B sets the acknowledgement number to 701 in the acknowledgement message segment sent to A. In summary, if the acknowledgment number equals N, then all data up to serial number N-1 has been received correctly.
In general, it can be ensured that when the serial number is reused, the data of the old serial number has already reached the end point through the network.
Data Offset
Occupying 4 bits, it indicates the TCP message segment header length. The data offset is necessary because there are also option fields of indeterminate length in the header. This field unit is 32 bits (4 bytes). Since the maximum number of 4-bit binary numbers that can be expressed is 15, the maximum data offset is 60 bytes.
Reserved
Occupies 6 bits, reserved for future use, currently set to 0
Emergency URG (URGent)
When URG is 1, it indicates that the urgent pointer field is valid, which tells the system that there is urgent data in this message and should be transmitted as soon as possible instead of following the original queue book order. For example, if the user issues Ctrl + C from the keyboard when a remote control program is running and needs to be interrupted, these two characters will be stored at the end of the receiving TCP cache if no urgent data is used. Only after all the data has been processed are these two characters given to the receiving application.
When URG is set to 1, the sending application process tells the sender’s TCP that it has urgent data to send, so TCP inserts the urgent data at the top of the data in this message segment, which is then paired with another prefix field The urgent pointer field indicates the length of the urgent data, and then the rest of the data remains as normal data.
Confirm ACK
The acknowledgement number field is valid only when ACK = 1, and invalid when ACK = 0. TCP specifies that all messages transmitted after the connection is established must have ACK set to 1
Forwarding PSH (PuSH)
When two application processes communicate interactively, sometimes the application process at one end wants to receive a response from the other immediately after adding a command, and this is when a push operation can be used. In this case, the sender sets PSH to 1 and immediately creates a message segment to send out, and the receiver receives the message with PSH of 1 and hands it to the receiving process as soon as possible, instead of waiting for the cache to fill up before delivering it together.
Reset RST
When a major error occurs, the connection must be released and a new one established. Or it can be used to reject an illegal message or refuse to open a connection.
Synchronized SYN
When SYN = 1 and ACK = 0, this is a connection request message, and if the other party agrees to establish a connection, SYN = 1 and ACK = 1 are used in the response message. Therefore, a SYN of 1 indicates that this is a connection request or a connection establishment message.
Terminate FIN
Used to release a connection. When FIN = 1, it indicates that the sender data for this message segment should have been sent and requests the release of the transport connection.
**That means that in theory, the TCP connection will not be broken without sending a message with this field of 1. **
Window
Occupies 2 bytes and the window value is an integer between [0, 2^16 - 1]. The window value is the receive window of the party sending this message segment. The window value tells the other party: The amount of data (in bytes) that the receiver is currently allowing the other party to send, counting from the acknowledgement number at the beginning of this message segment The window value is used as a basis for the receiver to allow the sender to set its send window.
The window field specifies the amount of data the other party is allowed to send now, and the window value changes frequently.
Test and
Occupies 2 bytes, the test and field test range includes the first part and data two parts. How to calculate the specific is more complex, interested in their own search
Emergency pointer
Occupies 2 bytes, meaningful only when URG = 1, indicates the length of the urgent data in this message segment, ** when all urgent data are processed, normal operation will resume for the next normal data in this message segment**.
Options
Variable length, up to 40 bytes, when no option is used, the length of the first part is 20 bytes.
Initially, only the MSS (Maximum Segment Size) was specified. The MSS should be as large as possible, as long as the IP layer is transmitted without further fragmentation, but of course, because the path experienced by the IP layer is dynamically changing, this MSS is also very difficult to determine.
During connection establishment, both parties can write their supported MSS into this field and later transmit according to this field, both transmission directions can have different size MSS. if the host does not fill in this field, the default is 536 and all Internet hosts should be able to accept an MSS of 536 + 20 (fixed prefix length) = 556 bytes.
Principle of TCP reliable transmission
Sliding window in bytes
TCP’s sliding window is all in bytes. Suppose A receives an acknowledgement message segment from B, where the window value is 20 and the acknowledgement number is 31 (this indicates that the next sequence number B expects to receive is 31, and the data up to sequence number 30 has already been received). Based on these two pieces of data, A constructs its own send window.
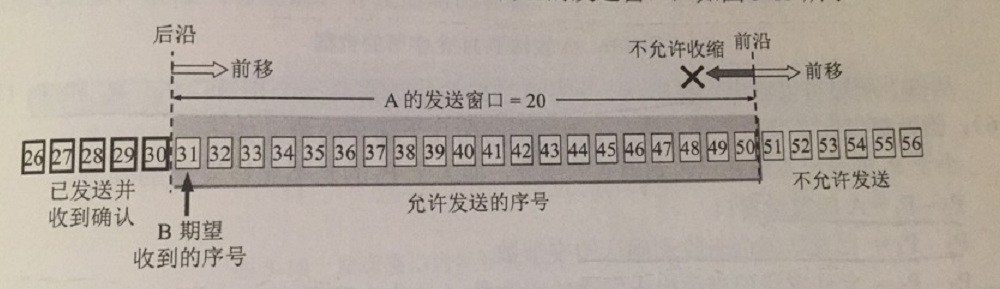
There may be some people here who are suddenly a bit confused as I am. If you have to wait for B to return an acknowledgement of A each time before you can change the window position and size and then send the window data out, what is the difference between that and the stop-wait protocol? The difference I can see so far is that the window size may be much larger than the MSS, requiring multiple groupings to be sent out, and each acknowledgement does not mean that the entire window is acknowledged.
For A’s send window, A can send all the data in the window continuously until an acknowledgement is received from B. Any data that has been sent must be temporarily stored until an acknowledgement is received, for use in timeout retransmissions.
The serial number inside the send window indicates the number of allowed sends. Obviously, the larger the window is, the more data the sender can send in succession before receiving an acknowledgement from the other party, thus obtaining higher data transmission efficiency.
The back part of the trailing edge of the send window means that the data has been sent and an acknowledgement has been received, and this data obviously does not need to be kept any longer. The leading part of the leading edge means that the sending is not allowed because the receiver has not reserved cache space for temporary storage of this data.
The position of the sending window is determined by both the leading edge and the trailing edge. There are two cases of changes in the trailing edge, i.e. not moving (no new acknowledgement received), and moving forward (new acknowledgement received). It is not possible for the trailing edge to move backward, because it is not possible to revoke an acknowledgement already received. The leading edge can keep moving forward, or it can be immobile. There are two cases of immobility, one is that no new confirmation is received, and the size of the window of more notifications is also unchanged, and the second is that a new confirmation is received, but the window of the other notification shrinks, which just makes the leading edge immobile. Of course the frontier can also shrink backward, but TCP standard strongly discourages doing so.
Now suppose A sends the data of serial numbers 31-41, the position of the sending window does not change at this time, the 11 bytes behind the window means that the acknowledgement has been sent but not received, and the 9 bytes in front means that the sending is allowed but not yet sent.
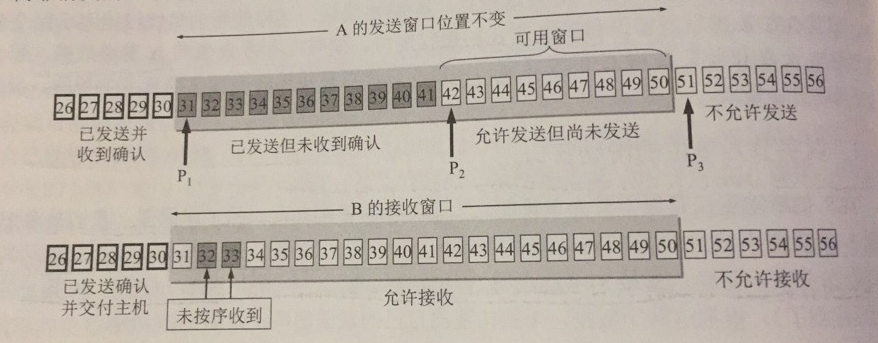
As can be seen from the above figure, to describe the state of a send window requires three pointers, P1,P2,P3, less than P1 is the part that has been sent and received, and greater than P3 is the part that is not allowed to be sent.
The size of B’s receive window is 20. Outside the receive window, all data up to 30 has been acknowledged as sent and delivered to the host, so B can no longer retain this data. 31-50 is allowed to be received.
In the above diagram 32,33 has been received by B, but not in order, because 31 has not been received, at this time B can only give an acknowledgement to the highest order number received in order, which means that the acknowledgement number in the message returned by B now is still 31.
If B receives number 31 and delivers 31-33 to the host, B deletes these data and moves the receive window forward by three serial numbers while sending an acknowledgement to A. The window value is 20 and the acknowledgement number is 34. After A receives it, P1,P3 move forward by three serial numbers and P2 remains unchanged.
Next, if A sends 42-53, ** pointers P2 and P3 overlap, the data in the window is sent, and no further acknowledgement is received, you need to stop sending**.
cache
The sender’s application process writes the byte stream to TCP’s send cache, and the receiver’s application reads the byte stream from TCP’s receive cache
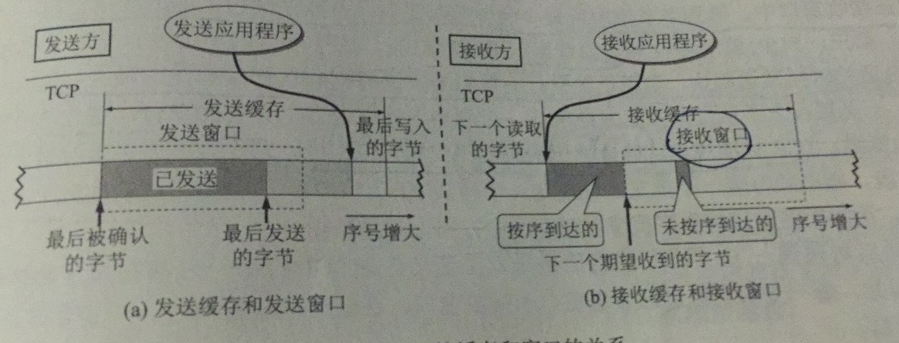
To be clear: both cache space and serial numbers are limited and recycled.
The send cache is used to temporarily store:
- The sending application transmits to the sender the data that TCP is ready to send.
- The part of TCP that has been sent but not yet acknowledged.
The send window is usually only part of the send cache and the acknowledged data should be removed from the send cache, so the trailing edges of the send cache and the send window are coincident. The last byte written to the send cache by the sending application minus the last byte acknowledged is the number of bytes still remaining in the send cache to be written.
The receive cache is used to temporarily store:
- Sequentially arriving data that has not yet been read by the receiving application
- Data that did not arrive in order.
If the application does not have time to read the received data, the receive cache will eventually fill up and the receive window will be reduced to 0.
Three additional points** are emphasized here**:
- Although A’s send window is set according to B’s receive window, at the same time, the size of A’s send window is not the same size as B’s receive window. Because there is a delay in the transmission of the network, and A’s sending window is also limited by the network congestion, when congestion occurs, the value of its own sending window should be reduced appropriately.
- For data that arrives out of order, TCP usually stores the data that arrives out of order** in a cache** first, and then delivers it to the upper layer application process** in order when the missing bytes are received in the byte stream**.
- TCP requires the receiver to have cumulative acknowledgements. The receiver can send an acknowledgement when appropriate or piggyback the acknowledgement when it has data to send itself, but the acknowledgement should be delayed no more than 0.5 seconds.
Selection of timeout retransmission time
TCP’s timeout retransmission time uses an adaptive algorithm. It records the time when a message segment is sent and the time when the corresponding acknowledgement is received. The difference between these two times is the message segment round-trip time RTT, and TCP keeps a weighted average round-trip time RTTs , also known as smoothed round-trip time.
When the RTT sample is measured for the first time, the RTTs takes the value of the RTT sample value and is recalculated every time the RTT is received next:
New RTTs = (1 - α)* (old RTTs) + α * new RTT samples
where the alpha is recommended to be 0.125
Obviously the timeout retransmission time RTO (RetransmissionTime-Out) should be slightly greater than RTTs.
RTO = RTTs + 4 * RTTD
RTTD is the weighted average of the deviations from RTTs. For the first measurement, RTTD takes the value of half of RTT, and the following algorithm is used next:
New RTTD = (1 - β)*(old RTTD) + β * |RTTs - new RTT samples|
The recommended value of β is 0.25
Now there is a problem, when the set retransmission time is up, still no acknowledgement is received, so the message is retransmitted and after some time an acknowledgement is received, ** how to confirm whether this acknowledgement is for the previously sent message or for the retransmitted message? **, this has a big impact on the RTTs calculation.
For this case, the current approach is to increase the RTO to twice as much for each retransmission of the message
Select to confirm SACK
If there is no error in the received message segment, but it just didn’t arrive in order, and there is some serial number data missing in the middle, **can we find a way to transmit only the missing data and not the data that has been received correctly? **
The answer is yes, it is SACK, and here is just a brief explanation of the principle.
Suppose the received message sequence number is 1 - 1000,1501 - 3000,3501 - 4500, the middle is missing two parts, if **these bytes of the sequence number are within the reception window **, then first these data received, but to find a way to notify the sending send I have received.

From the above figure we can see that every byte block that is not contiguous with the preceding and following bytes has two boundaries, and the figure uses L1, R1, L2,R2 to represent these four boundaries
We know that the TCP header does not have a field that can be populated with such boundary values.
If you want to use SACK you have to add allow SACK option to the header during the TCP establishment phase. If you confirm the use, the original usage of the acknowledgement number field remains the same, only the SACK option is added to the options. However, a maximum of 4 bytes of information is specified in the option, because the serial number has 32 bits and requires four bytes, a byte block requires two serial numbers and 8 bytes, while two bytes are required to specify which are SACK options, 4 byte blocks will use up 34 bytes, and the maximum option is 40 bytes, so adding another byte block will exceed it.
TCP Traffic Control
So-called flow control is to keep the sender from sending too fast and the receiver from receiving in time.
Traffic control on the sender side can be easily implemented using sliding windows.

The flow of the above diagram can be summarized as follows
- When the connection is established, B tells A: My receive window is rwnd = 400, so the sender’s send window cannot exceed the receive window given by the receiver. Note that the TCP window unit is bytes and not message segments.
- Let the length of each message segment be 100 bytes, the initial sequence number be 1, ACK is the acknowledgement bit, and ack is the acknowledgement number.
- B performed three flow controls, the first reducing rwnd to 300, the second to 100, and finally to 0.
Think about a problem. If A sends a zero-window message segment shortly after B has space in its receive cache again and sends rwnd = 400 to A, but this message is lost, A keeps waiting for B to send a non-zero-window notification, and B keeps waiting for A’s data, a deadlock is created.
To solve this problem, TCP sets a persistent timer for each connection, and whenever the TCP side receives a zero-window notification, it turns on the timer, sends a probe message when it does, and breaks the deadlock if the result returned is not zero.
Timing of sending TCP message segments
The application process will transfer the data to the TCP send cache and leave the rest of the task to TCP. Different mechanisms can be used to control the timing of sending TCP message segments.
- The first one is to use MSS to encapsulate the data stored in the cache into a message segment and send it out as soon as the MSS is reached.
- The second is the application specifying the send, such as PSH operations
- The third is for the sender to set a timer and send the data in the cache packaged when the time comes.
Congestion Control
In computer networks, link capacity, caches and processors in switching nodes are resources of the network. When the demand for a resource in the network exceeds the available portion of that resource, the network performance has to change, and this situation is called congestion.
Congestion control is about preventing too much data from being injected into the network, which keeps the routers or links in the network from being overloaded.
Congestion control is a global process that involves all hosts, routers and all factors related to degrading network transmission performance, while Traffic control often refers to the control of point-to-point traffic and is an end-to-end problem.
There are four congestion control algorithms for TCP, the very familiar slow start, congestion avoidance, fast retransmission, and fast recovery.
The sender maintains a value called the congestion window cwnd. The size of the congestion window depends on the congestion level of the network and is dynamically changing. The sender makes its sending window equal to the congestion window.
The principle of cwnd control on the sender side is to expand cwnd a bit as long as there is no congestion, and to reduce cwnd as long as there is congestion or the possibility of congestion, and the basis for determining that the network is congested is that there is a timeout.
Principle
We also use this classic diagram to illustrate:
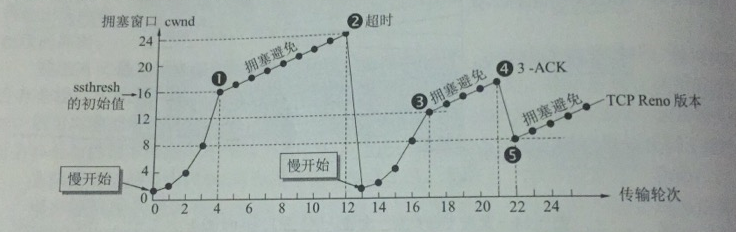
**The idea of slow start is this: when the host starts to send data, it is not clear about the load of the network, and if a large amount of data is injected into the network immediately, congestion may occur, so it increases the cwnd from small to large.
When the messages are first sent, the congestion window cwnd is first set to 2 to 4 sender maximum message segments SMSS.
If no acknowledgement is received, cwnd is increased by up to one SMSS.
cwnd per increment = min(N, SMSS), N is the number of bytes of messages that were originally unacknowledged and just received in the acknowledgment segment of the acknowledgment message.
We use the following example to illustrate the principle of slow start. For the sake of illustration , we use the number of message segments as the unit of cwnd, which should actually be the number of bytes.
At the beginning, the sender sets cwnd to 1, sends the first message M1, and the receiver receives M1 and returns an acknowledgement. After the sender receives an acknowledgement from M1, it increases cwnd from 1 to 2. Then it sends M2 and M3, and after receiving an acknowledgement from both, cwnd increases from 2 to 4, which means that the slow start algorithm, with each transmission round elapsed, cwnd doubles. The elapsed time of one transmission round is actually an RTT
To prevent cwnd from growing too fast, a slow start threshold ssthresh also needs to be set.
- When cwnd < ssthresh, the slow start algorithm is used.
- When cwnd > ssthresh, use congestion avoidance algorithm
- Both are possible when cwnd = ssthresh.
The idea of congestion avoidance is to make cwnd grow slower and let cwnd add 1 for every RTT passed. when cwnd grows to ssthresh (point 1 in the figure) change to congestion control algorithm from slow start.
After a timeout (point 2 in the figure), the sender determines that the network is congested and adjusts ssthresh = cwnd / 2, cwnd = 1 to re-enter the slow start.
Sometimes the sender receives three ACKs in a row (point 4 in the figure). This occurs because it is thought that sometimes, individual message segments are lost in the network, when in fact the network is not congested, and if the sender is late in receiving an acknowledgement, a timeout is generated and it is thought that congestion has occurred, which can lead to a false start of slow start by the sender. The use of the fast retransmission algorithm allows the sender to know early that individual messages are lost.
The fast retransmission algorithm requires the receiver not to wait for its own data to be sent before waiting for an acknowledgement, but to send an acknowledgement immediately. Repeat acknowledgements of received messages are sent immediately even if out-of-sequence messages are received. Suppose the receiver receives M1 and M2 and acknowledges them in time, now suppose the receiver does not receive M3 but receives M4, the receiver cumulatively confirms that it can only send an acknowledgement of M2, and then receives M5 and M6, and retransmits two more acknowledgements of M2 respectively, the sender receives a total of four acknowledgements of M2, three of which are duplicates, and knows that the receiver should initiate an immediate retransmission.
At point 4 in the figure, the sender, knowing that only individual segments of the message are lost, does not perform a slow start but a fast recovery with ssthresh = cwnd / 2, cwnd = ssthresh.
The above process can constantly adjust the size of cwnd, thus the size of the send window will be controlled by the level of congestion, but in reality the receiver has limited cache space, the receiver sets rwnd (receiver window, aka notification window) according to its receiving capability and writes this value into the window field in the TCP header, from the receiver’s point of view, the sender’s send window cannot exceed rwnd, so the upper limit of the sender’s sending window should be the smallest of rwnd and cwnd.
TCP connection management
We’ve said from the beginning that TCP is connection-oriented, and much of its design is based on that premise to function properly, so how does TCP establish and maintain that connection?
There are three problems to be solved during the establishment of a TCP connection:
- To enable each party to confirm the presence of the other
- To allow both parties to agree on some values, such as the maximum window value
- Ability to allocate resources to the most transportable entities.
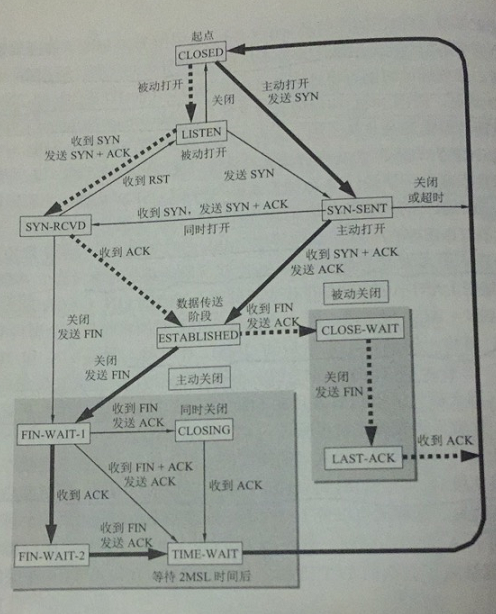
TCP connection establishment (three handshakes)
The process of establishing a TCP connection is called handshaking and requires the exchange of three TCP messages between the client and the server
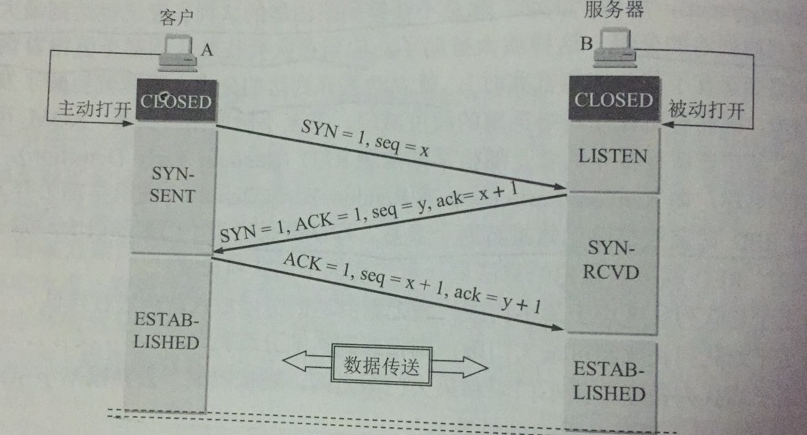
- Initially both ends are closed, in the above diagram it is A that actively opens the connection and B that passively opens it.
- At the beginning B’s TCP server creates the transport control block TCB, ready to accept connections from client processes, and then the server is in the LISTIN state.
- A’s TCP client creates a TCB, and before establishing a connection, first sends a connection request message to B with synchronization bit SYN = 1, while selecting an initial sequence number seq = x. TCP specifies that SYN messages cannot carry data, but a sequence number is consumed and the TCP client enters the SYN-SENT state
- After receiving the request message, B sends an acknowledgement to A if it agrees to establish a connection, sets both SYN and ACK to 1, ack to x + 1, and chooses an initial sequence number for itself seq = y. This message segment also cannot carry data, but consumes a sequence number.
- The TCP client of A has to give an acknowledgement to B after receiving the acknowledgement from B. ACK is 1, ack = y + 1, seq = x + 1, and at this time, the ACK message segment can carry data. At this time, A has entered the ESTABLISHED state, and B has also entered the ESTABLISHED state after receiving the acknowledgement.
The above process is called three handshakes, but the message segment sent by B to A can also be split into two message segments by sending an ACK = 1, ack = x + 1, and a synchronization message (SYN = 1, seq = y),** which becomes four handshakes. **
So why does A send an acknowledgement at the end? The main reason is to prevent connection request messages that have failed from suddenly arriving at B again. This situation generally arises after the first connection request message sent by A timeout, A again sent a request, B received a second request to complete the establishment of the connection and send data, after releasing the connection after the first request again, this time if B did not receive a second confirmation from A, it will not care about the first request.
TCP connection release (four waves)
The release process is similar to the build process, except that it is more complex and uses a header field of FIN
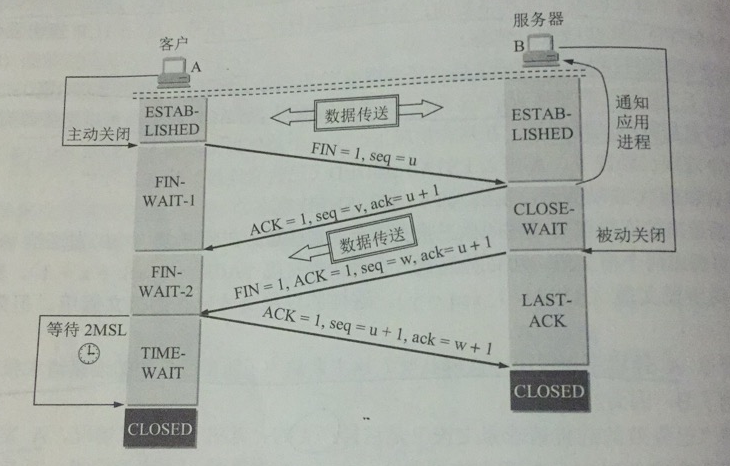
A’s application process first sends a connection release message to its TCP and stops sending data, actively closing the TCP connection
A sets the first field of the connection release message, FIN, to 1, with the sequence number seq = u, which is equal to the sequence number of the last byte of all data transmitted before it plus 1. At this point, A enters the FIN-WAIT-1 (abort-wait-1) state.
B receives the connection release message and sends an acknowledgement, ack = u + 1, with its own ordinal number seq = v, equal to the ordinal number of the last byte of data transmitted by B plus 1, and then B enters the CLOSE-WAIT (closed and waiting) state. At this point TCP enters a semi-closed state, i.e. A has no more data to send, but if B wants to send data, A can accept it, i.e. the connection from B to A is not closed.
A receives an acknowledgment hand from B and enters the FIN-WAIT-2 state, waiting for a release message from B.
If B has no more data to send, its application process notifies TCP to release the connection, at which point B sends a FIN message, seq = w (assuming B has sent some data in the semi-closed state), and ack remains u + 1.
After A receives the connection release message, it must send an acknowledgement for it, ACK = 1, ack = w + 1, seq = u + 1, and then enters the TIME-WAIT state. After the time set by the Time-WAIT timer (TIME-WAIT timer) of 2MSL, A enters the CLOSED state, MSL is called Maximum MSL is called Maximum Segment Lifetime (MSL).
There are two reasons for waiting this amount of time:
- It is guaranteed that the last ACK message sent by A reaches B. This message may be lost, so B may retransmit the last FIN message, at which time it is necessary for A to retransmit an acknowledgement and then restart the 2MSL timer.
- Preventing the above-mentioned failed connections by waiting for 2MSL ensures that all messages generated during the duration of this connection disappear from the network.
- In addition to the time waiting timer, there is a keepalive timer, the server did not receive a client data, it will reset it, the time is two hours, if two hours did not receive data, it will send a probe message, every 75 seconds to send a, if there is no reply for 10 consecutive, then close the connection.
TCP’s finite state machine