Unity Rendering Principle (1) Rendering Pipeline - From Point on Model to Point on Screen
General description
This article roughly summarizes how some 3D space coordinate data is transformed into pixels of different colors on the screen through the rendering pipeline. When reading, you need to pay attention to the difference between data elements, slice elements, and pixels.
The following figure is an overall flow chart, and the specific details can be seen later.

What is a rendering pipeline
The task of rendering pipeline
The job of the rendering pipeline is to render a two-dimensional image from a three-dimensional scene.
That is to say, it is necessary to start from a series of three-dimensional spatial information, such as vertex data, texture and other information, and finally convert this information into a two-dimensional image that the human eye can see.
This work is usually done jointly by the CPU and GPU.
Three conceptual stages of the rendering pipeline
Note that these three stages are only conceptual stages, and there are many steps inside each stage, usually a pipeline system.

Application phase
The reason why it is called the application phase is because this phase is the work carried out in our application, usually executed in the CPU, and the developer has absolute control over this phase.
At this stage, developers have three main tasks:
Prepare scene data, such as the position of the camera, the viewing cone, the point information of the model in the scene, the position intensity of the light source and other information.
With the above information, in order to improve rendering performance, we need to do a culling of Coarse Grain to remove those invisible objects, so that there is no need to hand them over to the geometry stage.
Note that culling is different from the later clipping. It completely eliminates the object information that is not in the visual cone, and directly discards the object information. The clipping mentioned later refers to those that are half in the visual cone and half are not. For this kind, while discarding part of the point information, we also add the intersection information when the object and the visual cone intersect.
- Finally, we need to set the rendering state of each model, including but not limited to materials (diffuse color, highlight color), textures, shaders, etc. The most important thing at this stage is to output the geometric information required for rendering, that is, render graph primitives. In general, graph render elements can be points, lines, triangles, etc.
The result of the application phase is all the 3D information that needs to be rendered.
Geometric stage
The Geometry phase deals with all things related to the geometry we want to draw. For example, deciding what elements to draw, how to draw them, and where to draw them, this phase is usually done on the GPU
The geometry phase is responsible for dealing with each render graph element and then performing vertex-by-vertex, polygon-by-polygon operations. This phase can be further divided into smaller pipeline stages.
An important task in the geometry stage is to transform the vertex coordinates into screen coordinates, and then hand them over to the grater for processing.
After multi-step processing of the input primitive, this stage will output the two-dimensional vertex coordinates of the screen space, the depth value corresponding to each vertex, coloring and other related information, and pass it to the next stage.
Grating stage
This stage will use the data passed in the previous stage to generate pixels on the screen and render the final image.
This stage also runs on the GPU.
The main task of grating is to decide which pixels of each render graph element should be drawn on the screen. It needs to interpolate the vertex-by-vertex data (such as texture coordinates, vertex colors) obtained in the previous stage, and then perform pixel-by-pixel processing.
The point of the result obtained in the previous step is not one-to-one correspondence with the pixels on the screen. For example, suppose that the coordinates of the pixels on the screen are all integers, and the screen coordinates calculated in the previous step are likely to be decimal places. We cannot simply and roughly choose the value of this point to be given to the nearest pixel, but to perform interpolation calculations.
Communication between CPU and GPU
The starting point of the rendering pipeline is the CPU, which is the application phase. The application phase can be roughly divided into three stages:
Load the data into video memory.
Set render status
Call Draw Call to notify the GPU.
Load data into video memory
All the data needed for rendering needs to be loaded from the hard disk into system memory. Then data such as meshes and textures are loaded into the storage space on the graphics card - video memory. This is because graphics cards have faster access to video memory, while most graphics cards do not have direct access rights to memory.
When the data is loaded into video memory, the data in RAM can be removed. But for some data, the CPU still needs to access it (for example, we want the CPU to have access to grid data to detect collisions), so we may not want this data to be removed.
Set render state
A popular explanation is that these states define how the mesh in the scene is rendered, such as which vertex shader, slice shader, light source properties, materials, etc.
If we don’t change the render state, then all meshes will use the same render state.

Call Draw
After all the above work is ready, the CPU needs to call a rendering command to tell the GPU to work according to the set rendering data and rendering state.
When receiving a Draw call, the GPU will calculate based on the rendering state (such as materials, textures, shaders, etc.) and all input vertex data, and finally output them as pixels displayed on the screen.
GPU pipeline
After the application phase, the CPU notifies the GPU through the Draw call command to render according to the data generated by the CPU, and then enters the GPU pipeline.
For the last two stages of the concept stage, namely the geometry stage and the rasterization stage, the developer cannot have absolute control, and the carrier of its implementation is the GPU. The GPU greatly speeds up the rendering speed by implementing pipelining.
Although we cannot fully control the implementation details of these two stages, the GPU opens up a lot of control to developers

As can be seen from the figure, the GPU’s rendering pipeline receives vertex data as input. These vertex data are loaded into video memory by the application phase and specified by the Draw call, and these data are then passed to the vertex shader.
Vertex shader. It is fully programmable and is usually used to implement functions such as spatial changes of vertices, vertex shading, etc.
Surface Subdivision Shader. Is an optional shader that is used to subdivide data.
Geometry shader. It is an optional shader used to perform element-by-element shading operations or generate more elements.
Crop. The purpose of this stage is to crop out the vertices that are not in the camera’s field of view and remove some triangular elements. This stage is configurable, for example, we can use a custom crop plane to configure the crop area, or we can control the front or back of the triangle element through commands.
Screen mapping. Not configurable and programmable, responsible for translating the coordinates of each primitive into the screen coordinate system.
Triangle setting and triangle traversal. Fixed function phase
Element shader. Element-by-element shading operation.
Piece-by-slice meta operation. Responsible for performing many important operations such as modifying colors, depth buffering, blending, etc., non-programmable, but highly configurable.
Vertex shader
In the first stage of the pipeline, the input comes from the CPU, and the processing unit of the vertex shader is the vertex.
That is, each vertex entered will call the vertex shader once.
The vertex shader itself cannot create or destroy any vertices, and cannot obtain the relationship between vertices. For example, we cannot know whether two vertices belong to the same triangular network. But precisely because of this independence, GPU can use its own characteristics to parallelize each vertex without being blocked by other vertices.
The main functions of the vertex shader are coordinate changes and vertex-by-vertex lighting.
Of course, in addition to these two main tasks, vertex shaders can also output the data required for subsequent stages

Coordinate transformation. As the name suggests, it is to perform some kind of transformation on the coordinates of the vertices. Vertex shaders can change the position of the vertices in this step, which is very useful in vertex animation. For example, we can simulate water surface, cloth, etc. by changing the vertex position. But it should be noted that no matter how we change the vertices in the vertex shader, one of the tasks a vertex shader must do is: convert the vertex coordinates from model space to齐次裁剪空间
We can often see the following code in vertex shaders:
o.pos = mul(UNITY_MVP, v.position);
The purpose of this code is to convert the vertex coordinates to the homogeneous clipping coordinate system, and then usually do the perspective division by the hardware, and finally get the normalized device coordinates (Normalized Device Coordinate, NDC).

Note that the coordinate range given in the figure above is both OpenGL and Unity’s NDC, and its z component has a range between [-1, 1], while in DirectX, the z component of the NDC has a range of [0, 1]. Vertex shaders can have different output methods.
The most common output path is grated and then handed over to the chip element shader for processing. In modern Shader Models, data can be sent to the Surface Subdivision Shader or Geometry Shader.
Cropping
Since our scene is very large, and the camera’s field of view is likely not to cover all scene objects, it is a natural idea that those objects that are not in the field of view do not need to be processed, and Clipping is for this.
There are three relationships between a primitive and the camera field of view: completely within the field of view, partially within the field of view, and completely outside the field of view.
What is completely within the field of view is passed to the next pipeline, and what is completely outside the field of view does not need to be passed.
The part that is in the field of view needs to be cropped.
Since we have normalized all the vertices into a cube in the previous step, clipping is simple: just crop the primitive into the unit cube:

Unlike vertex shaders, this step is not programmable, that is, we cannot control the clipping process through programming.
Screen mapping
The input coordinates in this step are still the coordinates in the 3D coordinate system (the range is within the unit cube). The task of screen mapping is to convert the x and y of each primitive to the screen coordinate system (two-dimensional coordinate system), which has a lot to do with our display screen resolution
Suppose that we need to render the scene onto a window, the window range is from the smallest window coordinates (x1, y1), to the largest window coordinates (x2, y2), since our input coordinates are -1 to 1, From this you can imagine that this process is actually a scaling process, in which the z coordinate remains unchanged.
The screen map does not do anything with the z coordinate, and the screen coordinate system and the z coordinate together form a new coordinate system, called the window coordinate system, and these values are passed together to the grating stage

Triangle settings
From this step we enter the grating phase.
The information output from the previous stage is the position of the vertices in the screen coordinate system and additional information related to them, such as depth value (z coordinate), normal direction, viewing angle direction, etc.
The two most important goals of grating are to calculate which pixels are covered by each primitive, and to calculate their colors for those pixels.
The first pipeline stage of grating is triangle setup. This stage calculates the information needed to grate a triangle mesh.
Specifically, the output from the previous stage is the vertices of the triangular mesh, that is, we get two vertices on each edge of the triangular mesh. But if we want to get the coverage of the entire triangular mesh on pixels, we must calculate the pixel coordinates on each edge.
In order to be able to calculate the coordinate information of the boundary pixels, we need to obtain a representation of the boundary of the triangle.
Such a process of calculating the data represented by a triangular mesh is called triangle setup. Its output prepares for the next stage.
Triangular traversal
Each pixel (pixel on the screen) is checked if it is covered by a triangular mesh, and if it is covered, a slice is generated. Such a process of finding which pixels are covered by the triangular mesh is triangle traversal, which is also known as scan transformation.
The triangle traversal stage will determine which pixels are covered by a triangular mesh based on the results of the previous stage, and use the three vertex information of the triangular mesh to interpolate the pixels of the entire coverage area.
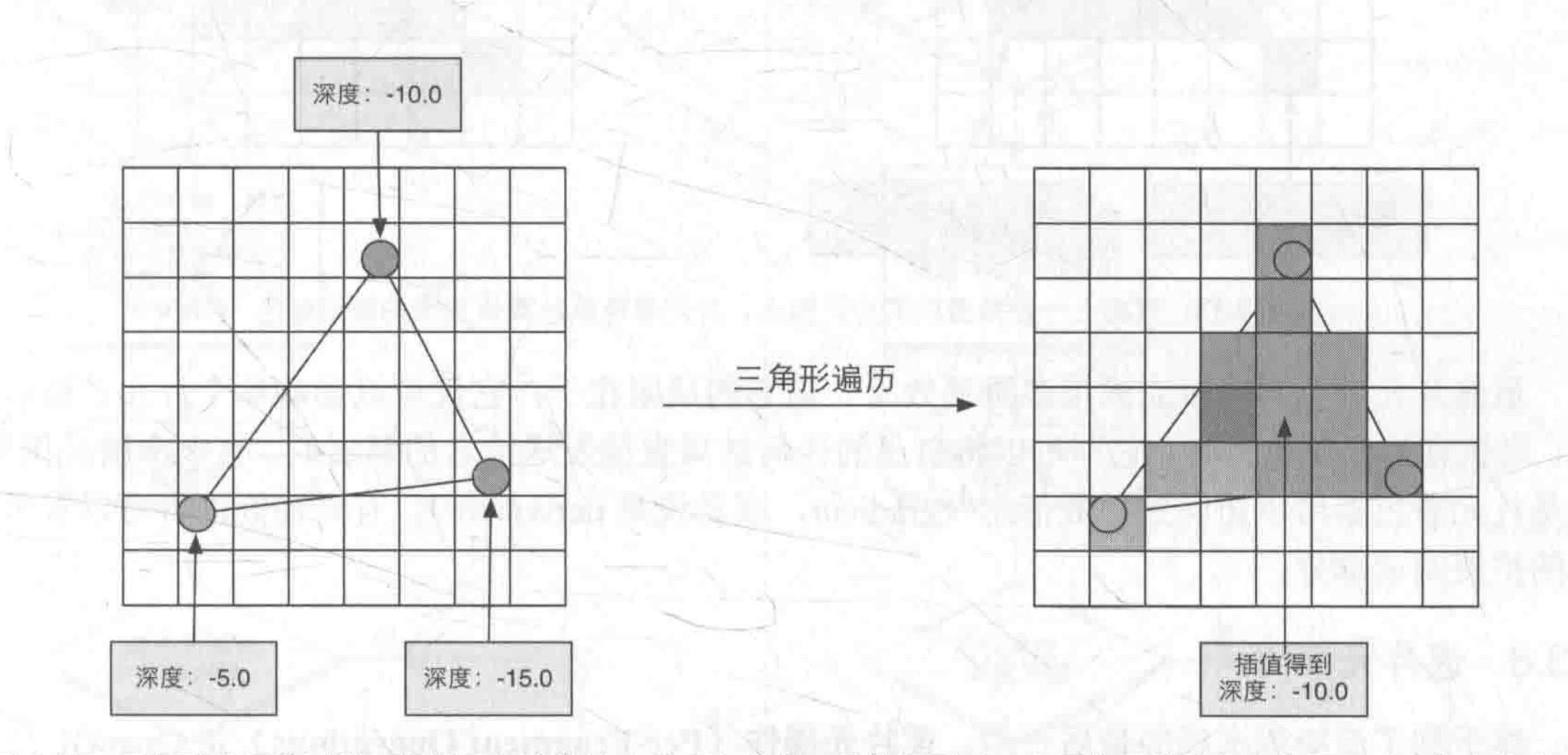
The result of this step is a sequence of elements.
A slice corresponds to a pixel, but it is not a pixel in the true sense, but a collection of states that are used to calculate the final color of each pixel. These states include but are not limited to its screen coordinates, depth information, and other vertex information output from the geometry phase, such as normals, texture coordinates, etc.
Element shader
A very important stage of programmable shaders, also known as pixel shaders, but chip shaders are more appropriate because chip shaders are not yet a true pixel.
The previous grating stage does not affect the pixels on the screen, but generates a series of data to describe how a triangular grid covers each pixel. And each chip element stores such a series of data.
What really affects the pixels is the next stage of the pipeline - slice-by-slice operations.
The input of the slice element shader is the result of the difference value of the vertex information obtained in the previous stage.
This stage can complete a lot of important rendering techniques, one of the most important techniques is texture sampling, in order to sample the texture element shader, we usually output the texture coordinates of each vertex in the vertex shader, and then through the grating phase of the three vertices of the triangular mesh corresponding to the texture coordinates of the interpolation, you can get the texture coordinates of the chip element covered.

Piece-by-slice operation
This step is the final step in the rendering pipeline, also known as the output merge phase.
There are several main tasks in this stage:
Determine the visibility of each element, which involves a lot of testing work, such as in-depth testing, template testing, etc.
If a chip passes all tests, it is necessary to merge the color value of the chip with the color already stored in the color buffer, that is, blend.
Piece-by-piece operation first needs to solve the visibility of each piece element. This requires a series of tests. If the test cannot be passed, the piece element will be discarded directly, and the previous work will be in vain.
Briefly introduce template testing and in-depth testing

Template testing
Related to this is template buffering, which, like color buffering or depth buffering, can be understood as something like a register in an operating system for temporary storage.
When template testing is enabled, the GPU will first read the template value of the chip element location in the template buffer (through a mask, similar to a subnet mask), and then compare the value with the read reference value.
This comparison function can be specified by the developer, such as discard the element when less than, or discard when greater than
Depth test
If the depth test is turned on, the GPU will compare the depth value of the film element with the depth value of the depth buffer. This comparison is the same as the template test and can also be specified by the developer. Usually, this comparison function is less than or equal to the relationship, because we In general, we only want to display points close to the camera.
After passing the template test, the developer can also specify whether to update the template buffer content with this value.
Merge
Our rendering is object by object drawn onto the screen, and the color value of each pixel is stored in the color buffer.
When we perform this render, we often have the last result in the color buffer, so whether we overwrite directly or blend in some way is the problem solved by merging.
For opaque objects, just turn off the blending and cover it.
But for translucent objects, we need to combine the contents of the buffer to mix.