数学之美梳理(七)深度学习与神经网络
我们首先来了解下解深度学习、机器学习与人工智能的定义:
深度学习是机器学习的子集,它基于人工神经网络。 学习过程之所以是深度性的,是因为人工神经网络的结构由多个输入、输出和隐藏层构成。 每个层包含的单元可将输入数据转换为信息,供下一层用于特定的预测任务。 得益于这种结构,机器可以通过自身的数据处理进行学习。深度学习的用例范围一直在不断扩展,但如今最流行的三大技术,当属计算机视觉、语音识别和自然语言处理
机器学习是人工智能的子集,它采用可让机器凭借经验在任务中做出改善的技术(例如深度学习)。 学习过程基于以下步骤:
- 将数据馈送到算法中。 (在此步骤中,可向模型提供更多信息,例如,通过执行特征提取。)
- 使用此数据训练模型。
- 测试并部署模型。
- 使用部署的模型执行自动化预测任务。 (换言之,调用并使用部署的模型来接收模型返回的预测。)
- 人工智能 (AI) 是使机器能够模拟人类智能的技术。 其中包括机器学习。
- 神经网络是机器学习的一种算法,而监督学习,无监督学习,强化学习等属于机器学习的训练方法,都可以应用于神经网络的训练,不同的训练方法适用于不同的机器学习算法,比如监督学习就适用于回归和分类,不同的算法适合解决不同的问题,比如回归问题适合解决拟合出一条曲线的问题,聚类问题适合分类问题
人工神经网路
人工神经网络和人脑没有任何关系,它本质上是以一种有向图,只不过是一种特殊的有向图。
我们都知道有向图包括节点和连接这些节点的有向弧,而神经网络也有节点,不过它使用了一个新的名词——神经元,而它的有向弧则被看成是连接神经元的神经。
当然,它是一种特殊的有向图,其特殊性可以概括为:
- 图中所有节点都是分层的,每一层节点可以通过有向弧指向上一层节点,但是同一层节点之间没有弧直接相连,而且每个节点不能越过一层连接到上上层的节点。
- 每一条弧上有一个值(称为权重或者权值),根据这些值,可以用一个非常简单的公式计算出它们所指的节点的值。如图中的 的值取决于 和 的值以及相应的有向弧上的值 和。
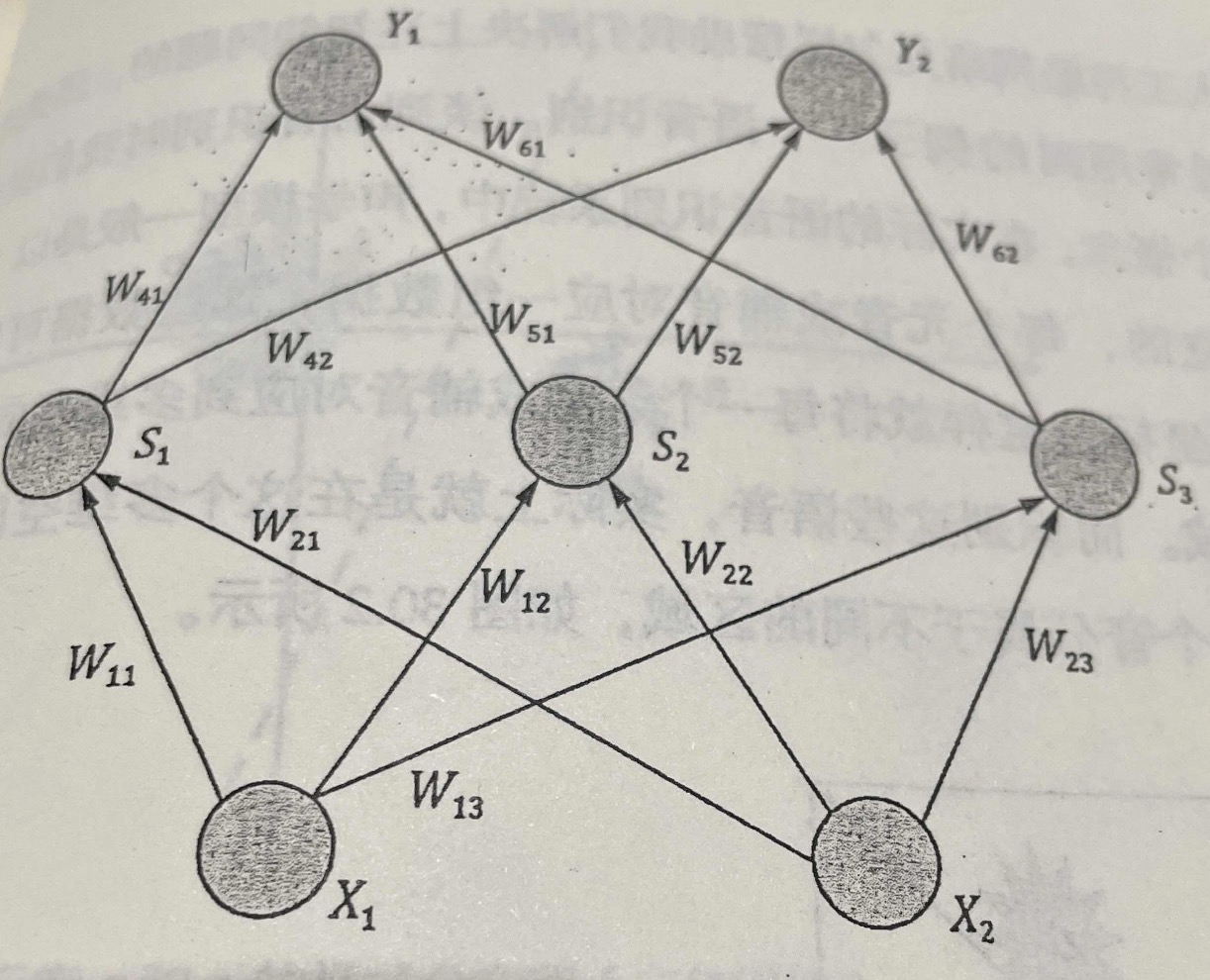
为了便于交流,一些书和论文中还有一些约定俗成的提法,比如图中最下面一层的节点有时被称为输入层,因为在各种应用中,这个模型的输入值只是赋值给了这一层节点,有向图中其他各节点的值都是通过这些输入值直接或者间接得到的。
对应于最底下的输入层,模型的最上一层节点被称为输出节点,因为我们要从这个模型获得的输出值都是从的那个这一层节点得到的。当然中间的其他层就被统称为中间层,对外不可见,因此又被称为隐含层。
到此为止,就是人工神经网络的定义。是的,神经网络就是这么简单。但是这么简单的东西有什么用呢?
无论是在计算机科学,通信,生物统计和医学,还是在金融和经济学,大多数与智能有点关系的问题,都可以归类为一个在多维空间中进行模式分类的问题,而人工神经网络所擅长的就是模式分类。我们可以列举出人工神经网络的很多应用领域,比如语音识别,机器翻译,人脸识别,癌细胞识别,股市走向预测等。
机器学习除了分类问题,还有其他类型的问题,比如回归问题,分类问题是为了的到分界线,将不同的数据分类,回归问题则是为了得到一条连续的曲线,然后根据曲线计算出结果,比如根据转发量估算阅读量
为了进一步说明人工神经网络是如何帮助我们解决上述智能问题的,还是用一个在前面各章经常用到的例子——语音识别。在实际的语音识别系统中,声学模型一般是以元辅音为单位建立的,每个元音或者辅音对应一组数据,这些数据可以看成是多维空间中的坐标,这样就将每一个原因或者辅音对应到多维空间中的一个点或者一个区域,而识别这个元音或者辅音就是在这个多维空间中划分一些区域,让每一个音分属于不同的区域。
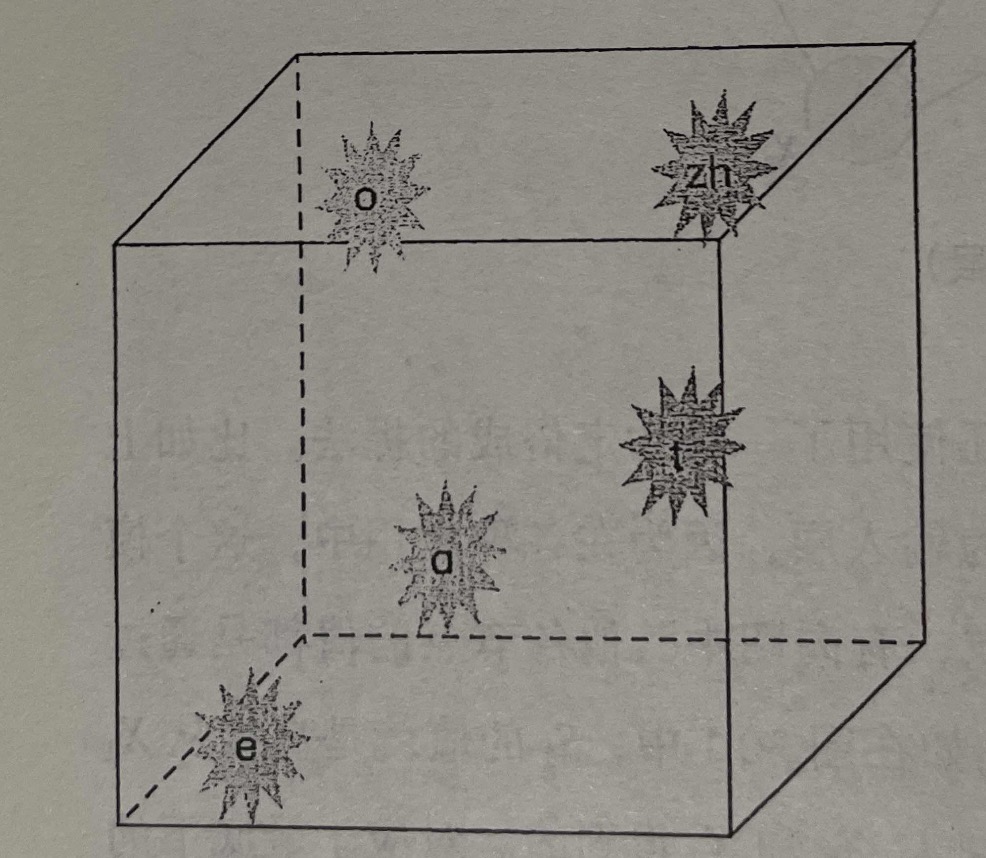
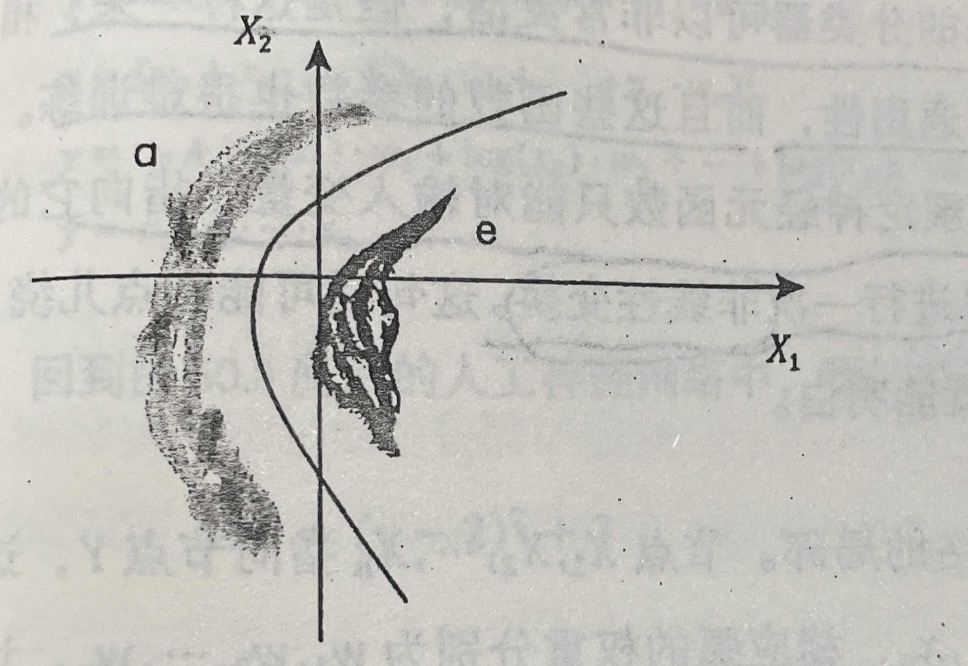
我们在空间中随机挑选5个元辅音,a,o,e,t,zh的位置,模式分类的任务就是在空间中切几刀,将这些音所在的区域划分开。
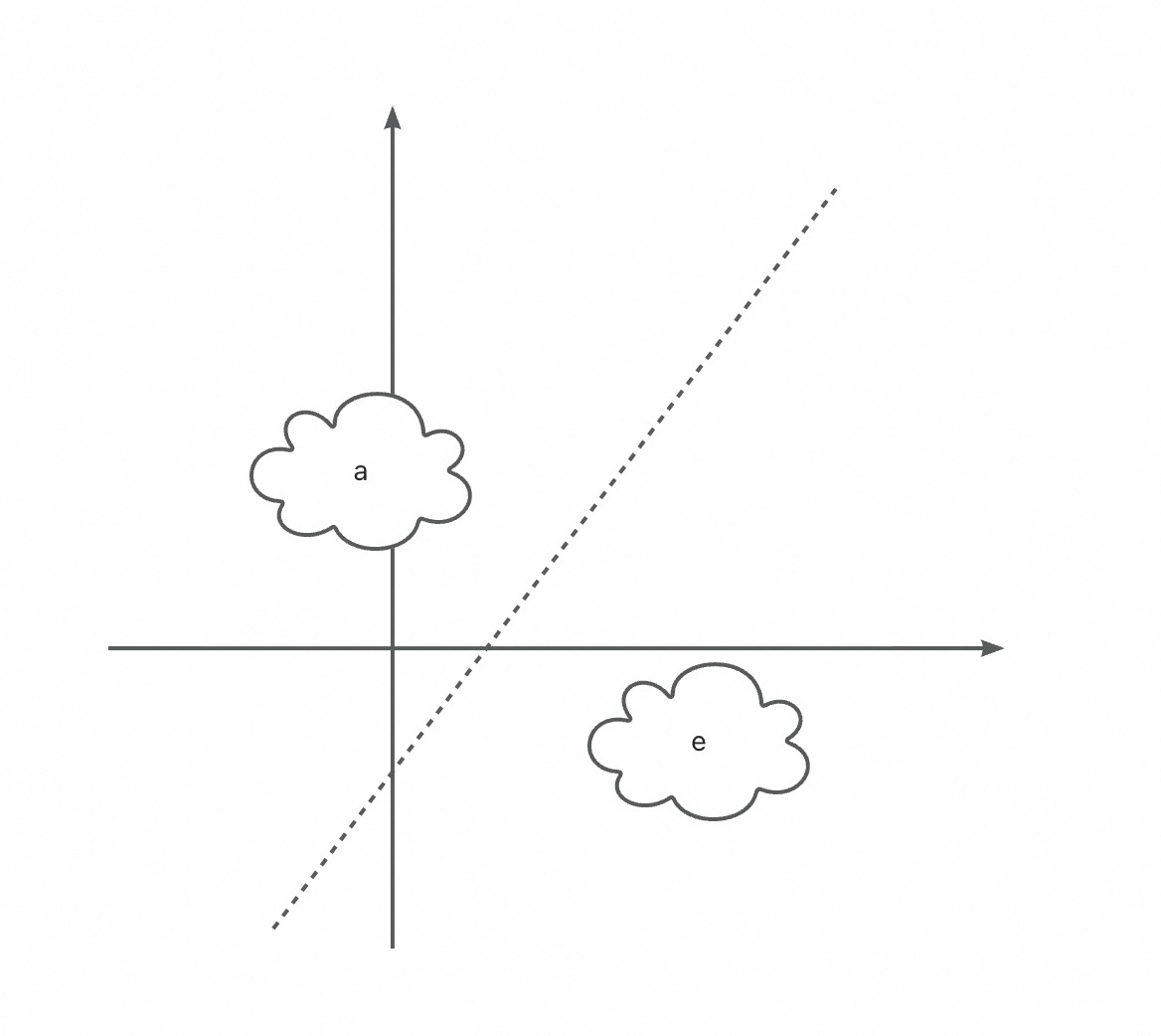
言归正传,让我们来看看人工神经网络是如何来分辨这几个音的。为了简单期间,假设空间只有两维,要区分的两个元音只有a和e,它们的分布
我们在前面讲了,模式分类的任务就是在空间切一刀,将a和e分开,图中的虚线就是分割线,左边是a,右边是e,如果有新的语音进来了,落在左边我们就将其识别为a,落在右边则将其识别为e。
现在可以用一个人工神经网络来实现这个简单的分类器(虚线),该网络结构如图所示:
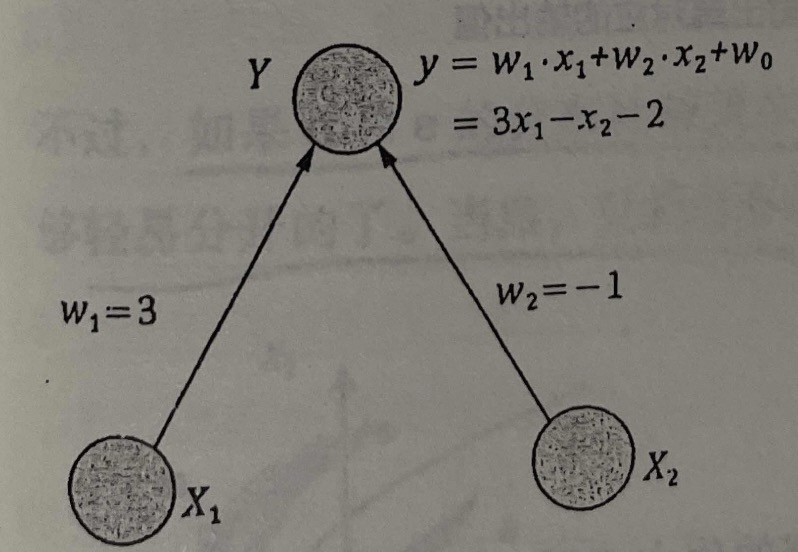
这是一个再简单不过的人工神经网络了。这个网络有两个输入节点 和,一个输出节点Y。在 到 Y 的弧上,我们赋予一个权重,在 到 Y 的弧上,我们赋予一个权重,然后将Y这一点上的数值设置为两个输入节点数值 的一种线性组合,即,注意,这个函数是一个线性函数,他也可以被看作是输入向量 和有向弧权重向量 的点积,为了后面判读时方便起见,不妨在公式中再加一个常数项 -2,即
接下来,可以将平面上一些点(0.5,1),(2,2)的坐标带入第一层的两个节点上,看看在数据节点上得到了什么值,只要得到的Y大于零,这个点就和e是同类,反之和a同类。
当然还可以在这个神经网络中将Y变成一个中间节点S,然后增加一个明显的输出层,包含两个节点 和。
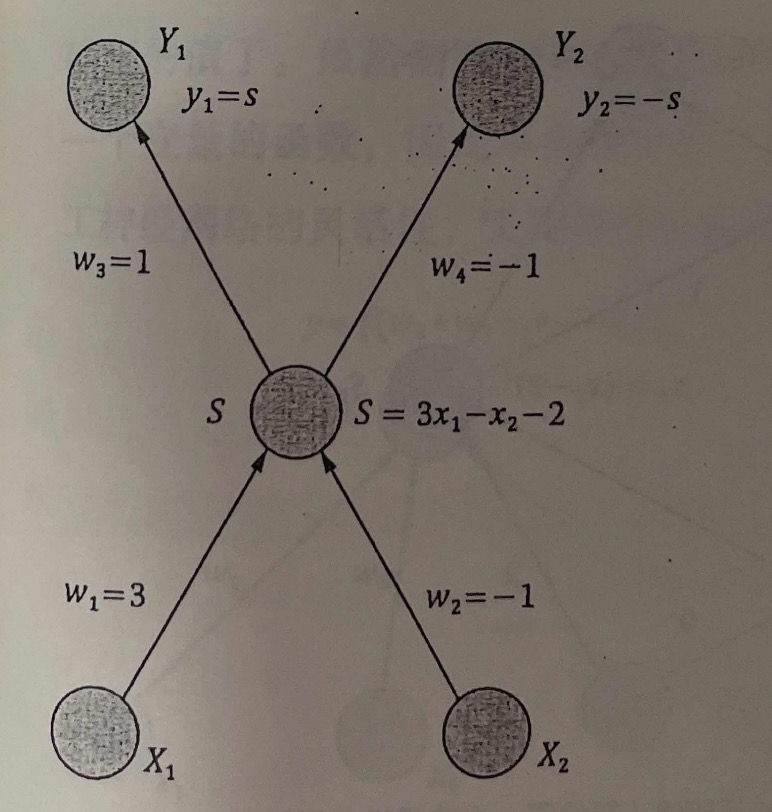
这样, 和谁的值大,我们就认为这个点应该属于相应的哪一类。
不过,如果a和e的分布比较复杂,就不知用一条直线可以分开的了,当然,只要分界线可以弯曲,还是能够区分这两类的。
为了实现一个弯曲的分解,我们设计了如图所示的人工神经网络:
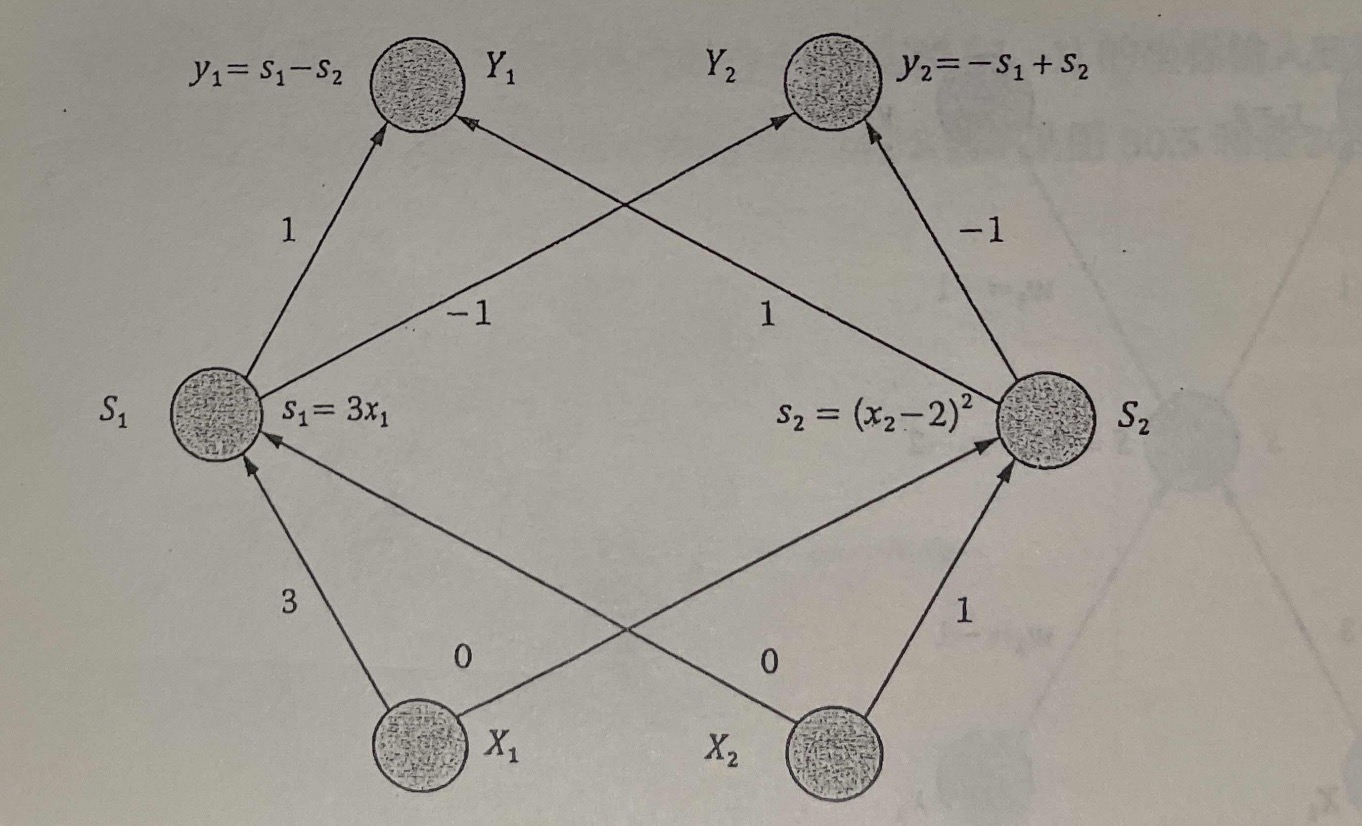
这个神经网络不仅结构稍微复杂了一点,多了一层,而且每个节点取值的计算也变得稍微复杂了一点:节点 的取值是用一个非线性函数计算出来的,这个函数被称为神经元函数,具体到这个例子中 采用了一个平方函数。
大家可能会有疑问,计算每个节点数值的函数是如何选取的?显然,如果允许函数随便选取,设计出来的分类器可以非常灵活,但是这样一来,相应的人工神经网络就缺少了通用型,而且这些函数的参数也很难训练。
因此,在神经网络中,规定神经元函数只能对输入变量(指向它的节点值)线性组合后的结果进行一次非线性变换。
举个例子,假设节点 指向节点Y,这些节点上的值分别是,相应弧的权重值分别为,计算节点Y的取值y分为两步,第一步是计算来自这些 数值的线性组合:
第二步是计算Y的值,。完成了第一步之后,G其实已经是一个定值了。虽然函数 本身可能是非线性的,但是由于它只是接受一个变量的函数,因此不会很复杂。这样两个步骤的结合,既保证了人工神经网络的灵活性,又使神经元函数不至于太复杂。
从理论上讲,人工神经网络只要设计得当,是可以实现任何复杂曲线的边界的。
在人工神经网络中,需要设计的只有两个部分,一个是它的结构,即网络分几层,每层几个节点,节点之间如何连接,第二个就是非线性函数 的设计,常用的函数是指数函数,即:
这时,它的分类能力等价于最大熵模型。
训练人工神经网络
人工神经网络的训练分为有监督学习(Supervised Training)和无监督学习(Unsupervised Training)两种,我们先来看一下有监督的学习。
在训练之前,需要先取得一批标注好的样本(训练数据),就像之前的图上的数据一样,既有输入数据,又有它对应的输出值y。
训练的目标是找到一组参数w,使得模型给出的输出值和这组训练数据中事先设计好的输出值尽可能一直,用数学语言来表达这段文字,应该是这样的:
假设C为一个成本函数(Cost Function),它表示根据人工神经网络得到的输出值(分类结果)和实际训练中数据输出值之间的差距,比如可以定义(即欧几里得距离),我们训练的目标是找到参数,使得
现在,训练人工神经网络就变成了一个最优问题,说通俗点就是我们中学数学里,寻找最值问题。解决最优化问题的常用方法是梯度下降算法。
现在一切都齐备了,我们有了训练数据,定义了一个成本函数C,然后按照梯度下降算法找到了让成本达到最小值的那组参数。这样,人工神经网络的训练就完成了。
不过,在实际应用中,我们常常无法获取大量标注好的数据,因此大多数时候,又必须借助无监督学习的训练得到人工神经网络的参数。
和有监督学习不通,无监督的训练只有输入数据,而没有对应的输出数据,这样一来,上面的成本函数C就没办法使用了,因为我们无从知道模型产生的输出值和正确的输出值之间的误差是多少,所以我们需要定义一种新的且容易计算的成本函数,它能够在不知道正确的输出值的情况下,确定或者说预估训练出来的模型的好坏
设计一个这样的成本函数,本身又是一个难题,使用人工神经网络的研究人员需要根据具体的应用来寻找合适的成本函数。不过总的来讲,成本函数的设计要遵循一个原则:既然人工神经网络解决的是分类问题,那么我们希望分类完成后,同一类样本应该相互比较靠近,而不同类的样本应该尽可能远离。比如多维空间的模式分类问题,就可以把每一个样本点到训练出来的聚类中心的欧几里得距离均值作为成本函数。对于估计语言模型的条件概率,就可以用熵作为成本函数。定义了成本函数,就可以用梯度下降算法进行无监督学习了。