OAuth的发展与设计
OAuth的中文名称是开放式授权协议,这个名字大家仔细品,它是一个授权协议,任何实现这个协议的网站都可以在用户同意的条件下给某些在自己这里注册的应用授予对应用户在本网站某些资源的权限,而这个权限一般用token来表示。
实际应用的举例
大家去leetcode登陆的时候,会弹出如下页面
在这里我们有两个选项,一个是直接注册一个账号,另一个就是选择第三方登陆,比如QQ登陆,这个第三方登陆中就使用了OAuth。
对于这第二种方式,这里要强调几点:
- 你的账号的数量根本没有减少,你还是同时拥有了leetcode以及qq两个账号,只不过qq提供了OAuth协议,你授权leetcode去获取你在qq的信息,leetcode利用这信息去创建了你在leetcode的账号,你在leetcode的账号也根本不会存储在qq,这就有点类似于实际生活中你在有关机构注册账户时都需要拿着身份证去,这个机构用你的身份证去公安局系统查找你的信息,然后用这些信息创建你在本机构的账户。你给这些机构身份证就类似于一个授权它去公安局操作你的信息的过程。
- OAuth协议只是一个授权协议,而上述的过程叫做第三方授权登录,登陆这个动作不是OAuth协议中规定的,也就是说仅凭OAuth无法完成授权登录这一套动作,OAuth也不仅仅是用来做第三方登录的。虽然我们大部分时间用第三方授权登陆讲OAuth,但是要打破这局限思维。
登陆方式的发展过程
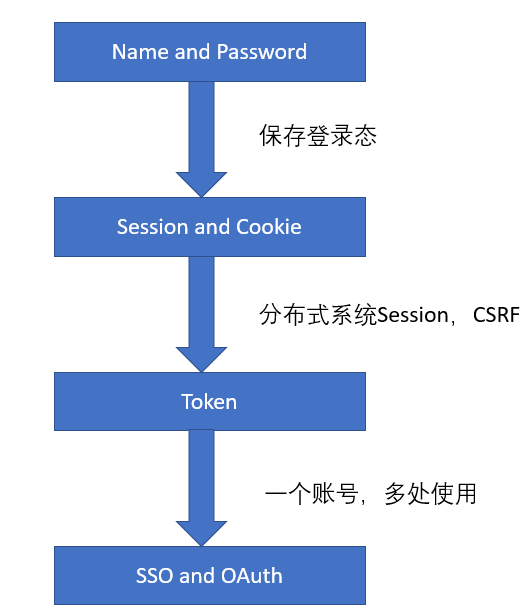
用户名密码
在一开始我们是服务端渲染以及静态页面的时候,我们仅仅通过用户名和密码进行身份验证,这也是所有身份验证的基础,以后的各种认证方式,大部分还是要基于这种方法的。
这种方法在一开始很管用,网站先给你一个登陆页面,你登录成功就给从服务器返回另外一个页面,你拿到了这个页面就表明你已经登陆过了,而且你的身份信息已经在返回之前写入了页面中,只是你看不到。
但是这样做最大的问题就是一旦你将这个页面关掉,你下一次再打开你就要重新登陆,这样就会有很差的用户体验。于是我们就开始想办法能不能将用户的登录态保存下来呢?于是就产生了第二种方式,Session和Cookie。
Session和Cookie
在这种方式中,用户在第一次登陆成功之后就会把用户的信息保存在session中存储在服务器中,然后生成一个sessionId标志该session并将其通过set-cookie头部返回给前端。这样一来,由于浏览器的实现决定,每次发起的同源请求都会自动带上该源之下的cookie,也就带上了sessionId,这样一来每次服务器只需要检查cookie中的sessionId,验证其有效性就可以找到用户信息。
但是这样又有了一个问题,浏览器是很不可靠的,基本上浏览器知道很有可能全世界都知道了,这里推荐仔细看一下同源策略,这东西没有想象中那么严格,最近我对它又多了几点认知:
- 同源策略一般只限制XMLHttpRequest之类的请求,比如Ajax。对于地址栏直接发出的请求是不加限制的,置于对这个请求重定向的请求是否限制还在探索中。
- 跨域写操作,如表单提交,重定向等一般是不限制的
- 跨域资源嵌入一般是不限制的。
- 跨域的读操作一般是不被允许的,但是可以通过上一条进行打破,比如利用script标签跨域加载脚本
- 不同域的脚本无法操作dom。
通过上述这些认知,我们可以发现一个比较关键的事情,浏览器的同源策略对于src中的直接发起的请求不怎么限制,而且只要是你请求的链接同个域名下的cookie都会被自动带上。
这里有个经典的例子,就是如果你去银行网站登录了之后,将sessionid存储在cookie中,在cookie过期之前,你打开了个攻击者的网站,里面有一个img标签,它的src属性是bank.com/tran/1000,也就是转账1000元的意思,由于它是src,所以浏览器会自动发起这个请求,虽然肯定是不会有图片返回,但是请求已经发出了,而且会自动带上未过期的该银行的cookie,因为浏览器看到你请求的地址是该银行,就自动帮你带上了。
上面这个例子就是比较简单的CSRF攻击。
上面这个例子的主要目的就是为了说明cookie是不安全的,即使有同源策略。
而且随着分布式系统的发展,如果通过这种方式来存储身份,你势必就要在每个服务器上维护一份身份的副本,而且要保证其一致性。
基于以上两点原因,我们又在想了,有没有什么办法可以既能将身份信息丢回给前端,这样每次前端带着身份信息过来,我验证一下是不是我授予他的就好,又能让这种方式比较安全呢?于是,我们就搞出了一个Token。这也是token的两个特点吧,一个是存储在前端,另一个就是服务器生成的,它一般不存储在cookie中。
Token
刚才我们说了Token是服务器生成的我们身份的证明,存储在前端,那我们又怎么保证其安全呢?一种比较古老的做法是如果你的页面是服务端渲染,那就在返回之前在每个需要提交请求的地方插入你的token,这样这个token就可以不存储在cookie中了,而跨域的脚本又无法操作dom也就无法获取你的token。
但是这样一来貌似又回到了一开始,页面一关闭,token就没了,而且这样消耗比较大。
另一种方法就是把这个token可以放在http头部中,也就是x-csrf头部。
还有许多token的使用方式,不是这次的重点,就不详细解释了。
SSO 和 OAuth
当我们身份认证的所有问题都得到比较好的解决之后,又出现了一个新的问题,那就是随着应用的增多,我们需要记住越来越多的账号,我们需要一个方法来帮我们记住所有账号或者只记一个账号,第二种方式就是SSO,它有多种实现基础,其中一种就是今天的主题OAuth。
在聊这个主题之前我们先定义几个关键字:
User:用户
User Agent:用户代理,如浏览器
Consumer:信息消费者,如Leetcode
Service Provider:分为两个,分别是身份认证提供者(Identity Provider, IDP),如QQ,以及资源提供者(Resource Provider),不过这二者一般是相同的。
所以:
- SSO的出现并不是为了解决一些登录上的安全或者流程问题,它是为了帮我们少记一些账号,OAuth只是它一种实现方式的基础。
- OAuth只负责user授权consumer去SP操纵一些属于user的资源,只不过在SSO中是用于在SP获取用户信息之后在consumer创建一个账号,这样下次只要user在SP通过了身份验证就等于在consumer通过了身份验证。
- User在consumer的身份和权限与OAuth没有关系,这是它们二者之间的事情,与OAuth无关,与SSO也无关,他们之间的认证又会退回前三种方式。SP不会关心也不会存储User在consumer的身份或者权限。
- 单凭OAuth,是无法完成授权登录整个流程的。
实际看一下SSO过程中关于OAuth的请求
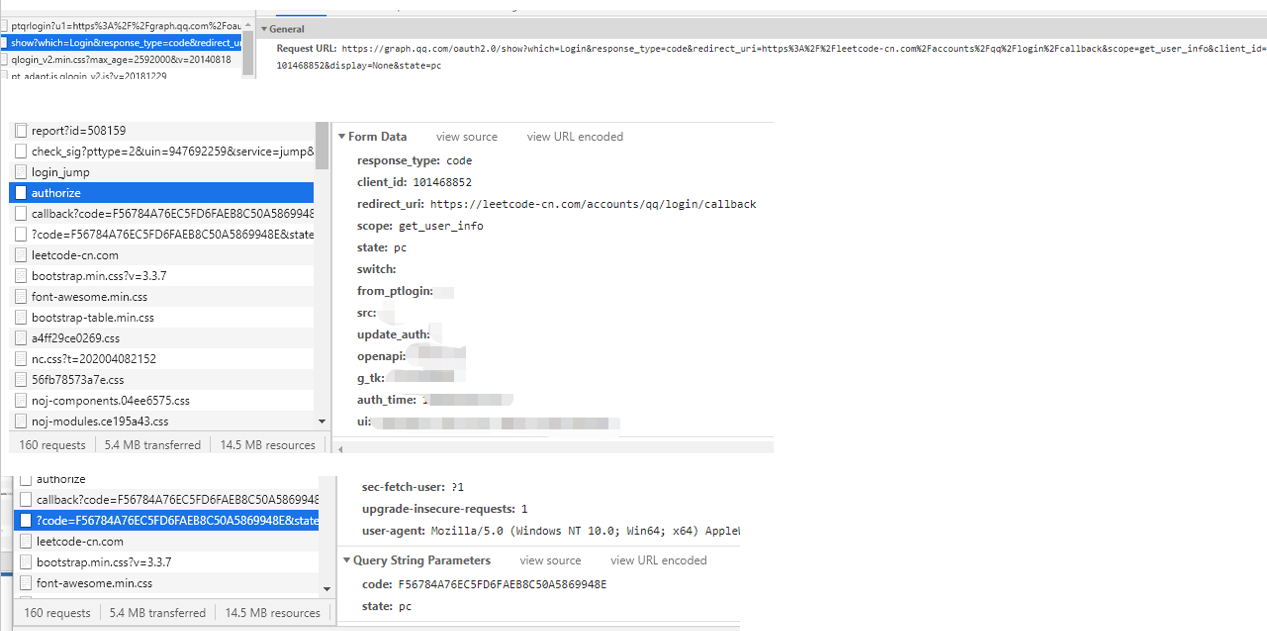
这张图是我截取的用qq去登陆leetcode中前端所涉及的请求,它大致分为以下几步:
- 去qq认证服务器拉取授权页面,参数中带有一些leetcode服务器生成的一些用于接下来授权请求的参数,只有带上这些参数,才可能通过qq认证服务器的验证并返回授权页面,同时授权页面接下来的请求需要用到这些参数
- 选择授权之后会发送第二个请求,请求中包括一些OAuth协议中定义的参数以及qq自身需要的参数。
- 第二个请求到达qq之后通过验证,返回一个302,location就是第二个请求参数中的redirect_uri,然后在参数中拼接qq为其生成的code和state。
- 浏览器收到302返回后,重新拿出location去发送请求,所以这个location一般是自身后台。
- 自身后台收到请求后,拿出code去qq换取token
OAuth协议就干了这些事情,那现在我们在leetcode有账号了吗?没有,接下来leetcode拿token去qq换回身份信息后才会进行leetcode账号的创建
以授权码模式说明一下OAuth2.0设计中的一些细节

这里的A请求就是刚才的第一个请求,B就是第二个授权请求,C是B的返回,状态码是302,location就是redirect_uri?code=XXX&state=XXX,浏览器收到后重新请求C的location,请求就到了leetcode后台,后台拿到code之后结合一些参数去qq换回了token。
这里大家可能会有很多疑问:
这些参数都表示什么:
redirect_uri:consumer在SP申请第三方授权登陆服务时填写的域名,一般是自身服务器的域名。
client_id:consumer在SP申请第三方授权登陆服务后,SP生成的该consumer的唯一id。
client_secret:consumer在SP申请第三方授权登陆服务后,SP生成的该consumer的唯一凭证,只有id与secret同时给出才能证明你是consumer
scope:你要申请的权限,一般都是由SP规定的。
state:一个随机字符串,consumer自身生成
code:用户授权后,SP返回给浏览器的code,consumer可以用这个code换token
access_token:最终目的。
为什么一开始就要发送个redirect_uri给IDP?
第一次是为了IDP设置返回地302中的Location,可以不验证是不是consumer设置好的,第二次就是验证这个redirect_uri是不是你当初在IDP这里设置的,与第一次过来的是否一样,这一步必须要验证,因为这一步是最关键的,这一步才会返回token。
为什么要绕这么一大圈,为什么要多一步code换access_token?
说到底还是信不过浏览器同志,让他当个工具人,让它帮自己地后台去第三方申请一个授权码,然后把这个授权码给自己的后台,再然后自己的后台用这个code去第三方申请token,完事还不告诉浏览器这个token是什么,自己留下了,也就是说浏览器同志从头到尾都没见过token。
Secret有什么用?
原因是IDP不信任何人,就信自己给出去的secret。因为redirect_uri是域名,最终到哪里还是要靠IP地址,如果域名是对的,但是域名被攻击者指向了自己的IP,攻击者就会收到token。怎么修改这个DNS指向就涉及DNS污染了,因为DNS会层层缓存,但是又有时间,如果你一直广播告诉路由器或者主机我是leetcode,我是leetcode,时间长了你在这一片局域网中就被认为是leetcode了。但是如果有了secret,就算你带着code过来了IDP,没有我给你的secret,IDP也不会给出token。所以client_id表明自己是谁,只有给了client_secret,IDP才会相信你说的话,并给你token,所以这个secret非常重要,我们的后台又不会相信浏览器同志了,所以我们的浏览器同志从头到尾也没摸过secret。
State又有什么用呢?
类似于防御CSRF,保证请求设备的一致性,不过不像CSRF是伪造受害者的请求,而是让受害者登录自己的账号,如果受害者在里面存个比特币账号岂不美哉?具体实现就是攻击者登录之后,正常申请,但是到了IDP返回302以后把请求拦下,不让浏览器发送请求给自己的后台,然后把这个带code的请求链接给受害人,受害人点进去之后就可以拿到access_token成功登录,如果不注意这个账号是不是自己的就上传敏感信息,就很happy。如果有了state,不同的设备我后台都生成一个随机的字符串给前端,攻击者就算把请求发给受害者,他也不知道受害者设备中的state,后台一看你的state和刚开始说好的不一样,就会直接把这个请求丢掉,当然硬要说攻击者把你的state从庞大的互联网的某个请求中给偷到了,那也是绝了,这就属于定点爆破了,就是要搞你,那这个人多半已经混在你的身边了。
为什么最后会返回两个token?
因为一个代表你是谁,一个代表你能做什么,你能做的事情随时可以被管理员改变,但是你是谁是固定的,而且一般access_token过期时间都比较短,如果我用着用着就过期了,总不能让用户重新登陆吧,那岂不是回到了起点?
OAuth2.0中的其他模式
简化模式
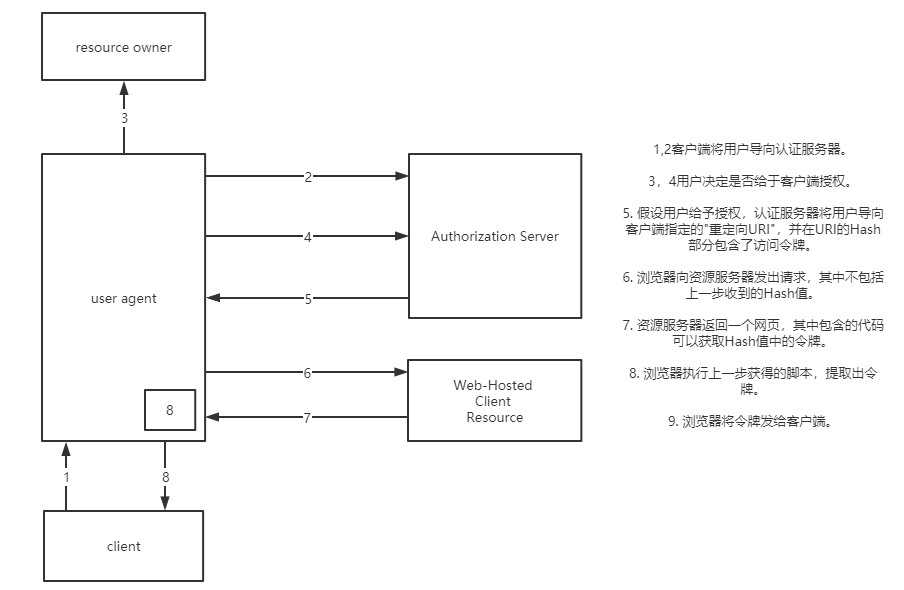
这种方式与授权码模式不同,它适用于没有服务端的情况,比如手机应用,前端直接就从SP拿到了token,但是要注意,这个token并不是像授权码模式中的code一样,拼在“?”后面,而是“#”后面,所以可以有效降低泄密的危险。
密码模式
密码模式(Resource Owner Password Credentials Grant)中,用户向客户端提供自己的用户名和密码。客户端使用这些信息,向"服务商提供商"索要授权。
在这种模式中,用户必须把自己的密码给客户端,但是客户端不得储存密码。这通常用在用户对客户端高度信任的情况下,比如客户端是操作系统的一部分,或者由一个著名公司出品。而认证服务器只有在其他授权模式无法执行的情况下,才能考虑使用这种模式。
客户端模式
客户端模式(Client Credentials Grant)指客户端以自己的名义,而不是以用户的名义,向"服务提供商"进行认证。严格地说,客户端模式并不属于OAuth框架所要解决的问题。在这种模式中,用户直接向客户端注册,客户端以自己的名义要求"服务提供商"提供服务,其实不存在授权问题。
OAuth1.0
在简单介绍一下1.0以及它为什么发展出了2.0
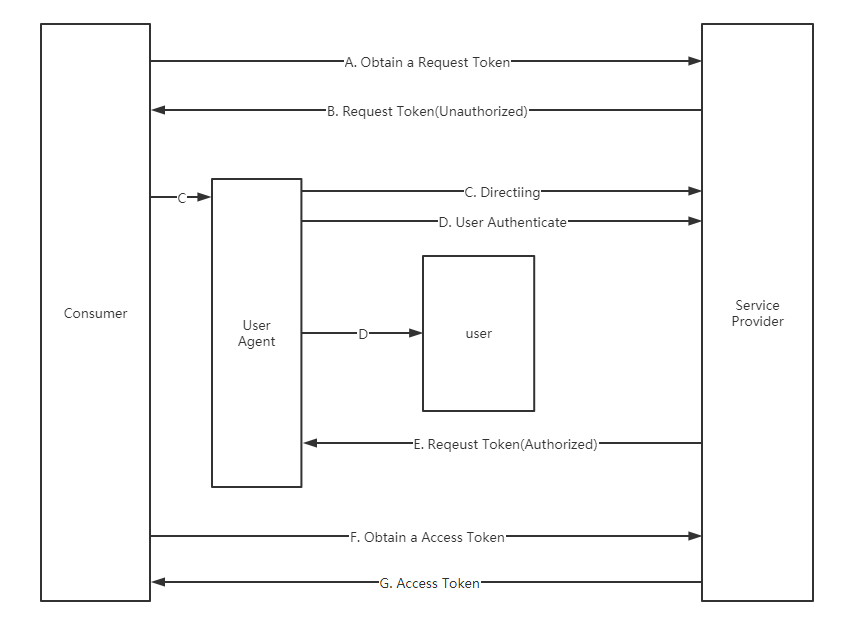
最大的不同就是多了AB两步,也就是1.0会先去SP申请一个未认证状态的request_token(可以类比为2.0的code),接下来的目的是为了把这个request_token变为认证状态,然后就可以拿这个request_token去换access_token了。
多了这一步就会出现问题,比如会话固定
还有就是对于手机或者客户端应用来说,重定向这一步是无法实现的,只能丢出一个连接来,让用户自己打开浏览器粘贴进去进行接下来的步骤。这样就会给攻击者很大的机会。
由此可以看出,1.0版本安全有很大的问题,而且对于非web应用来说体验比较差,所以就推出了2.0,。
比如2.0的简化模式就是为了适配客户端应用的,有兴趣的可以自己去了解一下。
1.0a
为了修复1.0中的安全问题,又提出了1.0a,他主要做了如下改变:
Consumer申请Request Token时,必须传递oauth_callback,而Consumer申请Access Token时,不需要传递oauth_callback。通过前置oauth_callback的传递时机,让oauth_callback参与签名,从而避免攻击者假冒oauth_callback。
Service Provider获得User授权后重定向User到Consumer时,返回oauth_verifier,它会被用在Consumer申请Access Token的过程中。攻击者无法猜测它的值。
参考资料:
https://sunra.top/2019/11/16/OAuth%20and%20OIDC/ :OAuth,OIDC简介
https://sunra.top/posts/74ee5df7/ :路由协议
https://sunra.top/posts/dfdf7442/ :ARP原理与防御
https://www.jianshu.com/p/0db71eb445c8 :OAuth认证流程举例
https://www.chrisyue.com/security-issue-about-oauth-2-0-you-should-know.html :OAuth2.0中的安全考虑
https://www.cnblogs.com/linianhui/p/openid-connect-core.html :OIDC文档
https://www.zhihu.com/question/19851243 :OAuth1.0与2.0区别
https://docs.azure.cn/zh-cn/active-directory/azuread-dev/v1-protocols-openid-connect-code :OIDC + AAD
https://www.sciencedirect.com/science/article/pii/S2215098617316750 :云服务中面临的安全问题
https://developer.mozilla.org/zh-CN/docs/Web/Security/Same-origin_policy :同源策略