HTTPS协议简介
HTTPS协议是HTTP + SSL/TLS组合而成的,而HTTP是用来从万维网服务器获取信息的协议,所以我们就从万维网开始讲起。
万维网与HTTP
万维网(WWW)并非某种特殊的计算机网络。万维网是一个大规模的,联机式的信息储藏所,英文简称web。万维网用链接的方式可以非常方便地从互联网上的一个站点访问另一个站点。
每一个万维网站点都存放了许多文档。在这些文档中有一些地方的文字是用特殊方式显示的,当我们鼠标移动到这些地方的时候,鼠标的箭头就变成了一只手的形状,这就表明这里有一个链接。如果我们点击这些链接,我们就可以从这个文档链接到可能相隔很远的另一个文档。
正是由于互联网的出现,使得互联网从少数计算机专家使用变成了普通百姓也能使用。
我们平时从浏览器打开网页就是从万维网服务器获取信息,使用的是HTTP协议。但是我们去玩LOL的时候,客户端与服务器之间的交流就可以不是HTTP协议了。
万维网是一个分布式的超媒体,他是超文本系统的扩展、所谓的超文本就是指包含连接向其他文档的链接的文本。一个超文本由多个信息源链接而成,而这些信息分布在世界各地。
万维网的客户端程序就是浏览器,万维网文档存储的主机就是万维网服务器,运行万维网服务器程序。客户程序向服务器程序发送请求,服务器程序就向客户端程序发送客户所需的万维网文档。在浏览器中显示的万维网文档就称为页面。
问题
从上面的描述可以看出,万维网必须解决几个问题:
- 怎样标志分布在整个网络上的万维网网络。
- 用什么样的协议来实现万维网上的各种链接。
- 怎样使不同作者创作的不同风格的万维网文档,都能在互联网的各种主机上都能够显示出来,并是用户清楚地知道在什么地方存在链接。
- 怎样使用户能够很方便地找到所需要的信息。
要解决第一个问题,万维网使用统一资源定位符URL(Uniform Resource Locator),来标志万维网上的各种文档,并使每个文档在整个互联网范围内具有唯一的标识符URL。
为了解决第二个问题,就要是万维网的客户程序与万维网服务器之间的交互遵守严格的协议,就是超文本传输协议HTTP(HyperText Transfer Protocol),它是一个应用层协议,使用TCP进行可靠传输。
为了解决第三个问题,万维网使用超文本标记语言HTML(HyperText Markup Language)。
解决最后一个问题的办法就是搜索引擎。
统一资源定位符URL
URL相当于是一个文件在网络范围内的扩展,是与互联网相连的机器上任何可访问的对象的一个指针(不止用于HTTP)。由于访问不同对象用的协议不同,所以还需要指出读取某个对象所需要的协议。
URL一般形式由四个部分组成:<协议>://<主机>:<端口>/<路径>
现在有的浏览器为了用户方便,在输入URL时,可以吧最前面的HTTP://甚至是www给省略掉。
超文本传输协议HTTP
HTTP是面向事务的应用层协议,它是万维网上能够可靠交付文件的重要基础。
每个万维网服务器都有一个服务器进程,它不断监听TCP的80端口,以便发现是否有浏览器向它发出连接建立请求。一旦监听到连接建立请求并建立TCP连接之后,浏览器就像万维网服务器发送某个页面的请求,服务器就返回所请求的页面作为响应。
HTTP规定在HTTP客户和HTTP服务器之间的每次交互,都由一个ASCII码串构成的请求和一个类似的通用互联网扩充,即“类MIME(MIME-like)”响应组成。
HTTP使用了面向连接的TCP作为运输层协议,保证了数据的可靠传输,HTTP不必考虑数据在运输过程中被丢弃后又怎样重传。
用户在点击鼠标链接某个万维网文档时,HTTP协议首先要和服务器建立TCP连接,这需要三次握手,当建立TCP连接的三次握手前两次完成后,浏览器就可以把HTTP请求报文作为第三个报文的数据发送过去。服务器收到请求后,就把请求的文档作为响应报文返回给客户。
上述过程就是HTTP1.0,它请求一个文档的时间是该文档的传输时间加上两倍的RTT,一个RTT用于连接TCP连接,另一个RTT用于请求和接收文档。
但是1.0主要的缺点是每请求一个文档,都要有两倍的RTT开销。若一个主页上有很多链接的对象需要一次连接,每一次下载都要有2RTT。另一种开销就是浏览器和服务器每一次建立新的TCP链接都要分配缓存和变量,特别是服务器要服务与大量的浏览器,所以这种非持续连接会使万维网服务器负担很重
HTTP/1.1协议采取了持续连接,它在服务器返回响应后仍在一段时间内保持这条连接,使同一个客户和服务器可以继续在这条连接上发送后续的HTTP请求和响应。1.1有两种工作方式,一种是非流水线,一种是流水线。第一种方式需要等前一个请求的响应到达之后才可以发送下一个请求,而流水线方式不用。
代理服务器
代理服务器是一种网络实体,又称为万维网高速缓存(Web Cache),可以将最近的一些请求和响应暂存在缓存中。
HTTP报文结构
HTTP有两类报文:
- 请求报文
- 响应报文
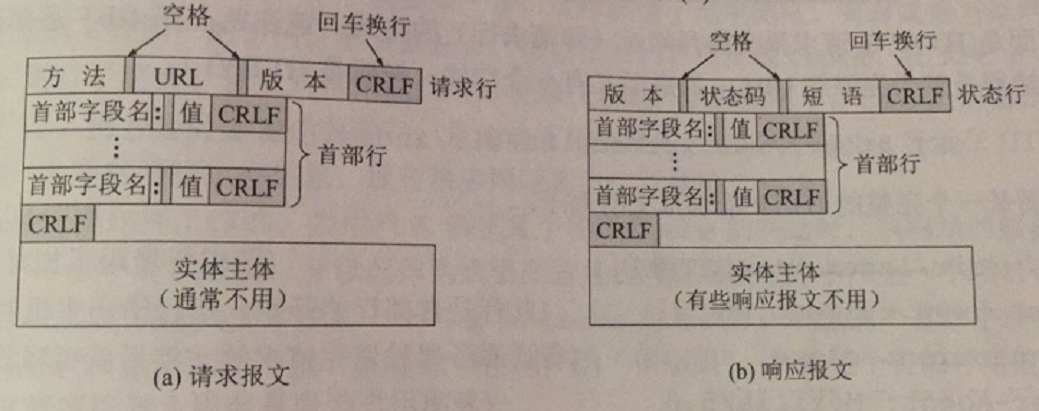
HTTP的请求和响应报文都是由三个部分组成:
- 开始行:用于区别请求报文还是响应报文,请求报文中叫做请求行,响应报文中叫做状态行
- 首部行:用来说明浏览器,服务器或报文主体的一些信息,可以有好几行,也可以一行不用
- 实体主体:在请求报文中一般不用,想用报文中也可能没有这个字段。
这里只是简单介绍一下HTTP,实际中的HTTP非常复杂,各种头部的使用种类繁多。
SSL/TLS
在理解这段内容之前,需要了解一下非对称加密,数字签名和证书
作用
不使用SSL/TLS的HTTP通信,就是不加密的通信。所有信息明文传播,带来了三大风险。
(1) 窃听风险(eavesdropping):第三方可以获知通信内容。
(2) 篡改风险(tampering):第三方可以修改通信内容。
(3) 冒充风险(pretending):第三方可以冒充他人身份参与通信。
SSL/TLS协议是为了解决这三大风险而设计的,希望达到:
(1) 所有信息都是加密传播,第三方无法窃听。
(2) 具有校验机制,一旦被篡改,通信双方会立刻发现。
(3) 配备身份证书,防止身份被冒充。
互联网是开放环境,通信双方都是未知身份,这为协议的设计带来了很大的难度。而且,协议还必须能够经受所有匪夷所思的攻击,这使得SSL/TLS协议变得异常复杂。
基本流程
SSL/TLS协议的基本思路是采用公钥加密法,也就是说,客户端先向服务器端索要公钥,然后用公钥加密信息,服务器收到密文后,用自己的私钥解密。
但是,这里有两个问题。
(1)如何保证公钥不被篡改?
解决方法:将公钥放在数字证书中。只要证书是可信的,公钥就是可信的。
(2)公钥加密计算量太大,如何减少耗用的时间?
解决方法:每一次对话(session),客户端和服务器端都生成一个"对话密钥"(session key),用它来加密信息。由于"对话密钥"是对称加密,所以运算速度非常快,而服务器公钥只用于加密"对话密钥"本身,这样就减少了加密运算的消耗时间。
因此,SSL/TLS协议的基本过程是这样的:
(1) 客户端向服务器端索要并验证公钥。
(2) 双方协商生成"对话密钥"。
(3) 双方采用"对话密钥"进行加密通信。
上面过程的前两步,又称为"握手阶段"(handshake)。
详细过程
"握手阶段"涉及四次通信,我们一个个来看。需要注意的是,"握手阶段"的所有通信都是明文的。
4.1 客户端发出请求(ClientHello)
首先,客户端(通常是浏览器)先向服务器发出加密通信的请求,这被叫做ClientHello请求。
在这一步,客户端主要向服务器提供以下信息。
(1) 支持的协议版本,比如TLS 1.0版。
(2) 一个客户端生成的随机数,稍后用于生成"对话密钥"。
(3) 支持的加密方法,比如RSA公钥加密。
(4) 支持的压缩方法。
这里需要注意的是,客户端发送的信息之中不包括服务器的域名。也就是说,理论上服务器只能包含一个网站,否则会分不清应该向客户端提供哪一个网站的数字证书。这就是为什么通常一台服务器只能有一张数字证书的原因。
对于虚拟主机的用户来说,这当然很不方便。2006年,TLS协议加入了一个Server Name Indication扩展,允许客户端向服务器提供它所请求的域名。
4.2 服务器回应(SeverHello)
服务器收到客户端请求后,向客户端发出回应,这叫做SeverHello。服务器的回应包含以下内容。
(1) 确认使用的加密通信协议版本,比如TLS 1.0版本。如果浏览器与服务器支持的版本不一致,服务器关闭加密通信。
(2) 一个服务器生成的随机数,稍后用于生成"对话密钥"。
(3) 确认使用的加密方法,比如RSA公钥加密。
(4) 服务器证书。
除了上面这些信息,如果服务器需要确认客户端的身份,就会再包含一项请求,要求客户端提供"客户端证书"。比如,金融机构往往只允许认证客户连入自己的网络,就会向正式客户提供USB密钥,里面就包含了一张客户端证书。
4.3 客户端回应
客户端收到服务器回应以后,首先验证服务器证书。如果证书不是可信机构颁布、或者证书中的域名与实际域名不一致、或者证书已经过期,就会向访问者显示一个警告,由其选择是否还要继续通信。
如果证书没有问题,客户端就会从证书中取出服务器的公钥。然后,向服务器发送下面三项信息。
(1) 一个随机数。该随机数用服务器公钥加密,防止被窃听。
(2) 编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
(3) 客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时也是前面发送的所有内容的hash值,用来供服务器校验。
上面第一项的随机数,是整个握手阶段出现的第三个随机数,又称"pre-master key"。有了它以后,客户端和服务器就同时有了三个随机数,接着双方就用事先商定的加密方法,各自生成本次会话所用的同一把"会话密钥"。
至于为什么一定要用三个随机数,来生成"会话密钥",dog250解释得很好:
"不管是客户端还是服务器,都需要随机数,这样生成的密钥才不会每次都一样。由于SSL协议中证书是静态的,因此十分有必要引入一种随机因素来保证协商出来的密钥的随机性。
对于RSA密钥交换算法来说,pre-master-key本身就是一个随机数,再加上hello消息中的随机,三个随机数通过一个密钥导出器最终导出一个对称密钥。
pre master的存在在于SSL协议不信任每个主机都能产生完全随机的随机数,如果随机数不随机,那么pre master secret就有可能被猜出来,那么仅适用pre master secret作为密钥就不合适了,因此必须引入新的随机因素,那么客户端和服务器加上pre master secret三个随机数一同生成的密钥就不容易被猜出了,一个伪随机可能完全不随机,可是是三个伪随机就十分接近随机了,每增加一个自由度,随机性增加的可不是一。"
此外,如果前一步,服务器要求客户端证书,客户端会在这一步发送证书及相关信息。
4.4 服务器的最后回应
服务器收到客户端的第三个随机数pre-master key之后,计算生成本次会话所用的"会话密钥"。然后,向客户端最后发送下面信息。
(1)编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
(2)服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时也是前面发送的所有内容的hash值,用来供客户端校验。
至此,整个握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的HTTP协议,只不过用"会话密钥"加密内容。
参考文章: