Javascript执行机制(九)阶段总结
Google V8是如何执行一段JavaScript代码的
本文主要是对一些老生常谈的JavaScript特性进行一个简单的统一的总结,并对于V8如何实现这些特性的进行一定的解释。
主要目的是通过介绍V8的执行流程将耳熟能详的特性串到一起,形成一个整体的认知,以及为什么JavaScript要这样设计。
中间会穿插一些思考,比如,我们在编码中应该避免的一些问题。
V8如何执行JavaScript
高级语言执行的两种方式
一段代码最终是要变成CPU能够识别的二进制代码才能够运行的。
所以高级语言的代码必须进行编译才能够被执行。
但是执行方式有两种,第一种是解释执行,一种是编译执行
注意,这里的解释执行和编译执行与平时所说的解释性语言和编译性语言不完全一样:解释性语言和编译性语言的区别 - 华为云
所谓解释执行,指的是解析器将高级语言解析为中间代码,然后由语言自带的虚拟机去模拟CPU的堆栈等特性去执行这个中间代码。

所谓编译执行,指的是编译器再将中间代码编译为二进制代码,然后直接交给CPU去执行。

我们看起来只能选一种,但是V8表示,小孩子才做选择,我全都要。
V8采取的是是一种混合使用编译器和解释器的JIT(Just In Time)的技术,这是一种权衡策略,因为这两种方法都各自有各自的优缺点,解释执行的启动速度快,但是执行时的速度慢,而编译执行的启动速度慢,但是执行时的速度快。你可以参考下面完整的 V8 执行 JavaScript 的流程图:

V8启动后,会从内存中申请堆和栈的内存空间。栈的存储是连续的,而堆中的数据存储可以是不连续的。
然后V8会初始化全局上下文,内部包含很多的信息,比如当前上下文的变量环境,这个变量环境中全局作用域中的变量。
初始化事件循环系统。其实就是一个消息队列,而这个消息队列中的每一个函数就是我们平时所说的宏任务。
V8为什么要用字节码
所谓字节码,是指编译过程中的中间代码,你可以把字节码看成是机器代码的抽象,在 V8 中,字节码有两个作用:
- 第一个是解释器可以直接解释执行字节码 ;
- 第二个是优化编译器可以将字节码编译为二进制代码,然后再执行二进制机器代码。
虽然目前的架构使用了字节码,不过早期的 V8 并不是这样设计的,那时候 V8 团队认为这种“先生成字节码再执行字节码”的方式,多了个中间环节,多出来的中间环节会牺牲代码的执行速度。
早期的 V8 为了提升代码的执行速度,直接将 JavaScript 源代码编译成了没有优化的二进制的机器代码,如果某一段二进制代码执行频率过高,那么 V8 会将其标记为热点代码,热点代码会被优化编译器优化,优化后的机器代码执行效率更高。
当 JavaScript 代码在浏览器中被执行的时候,需要先被 V8 编译,早期的 V8 会将 JavaScript 编译成未经优化的二进制机器代码,然后再执行这些未优化的二进制代码,通常情况下,编译占用了很大一部分时间,下面是一段代码的编译和执行时间图:
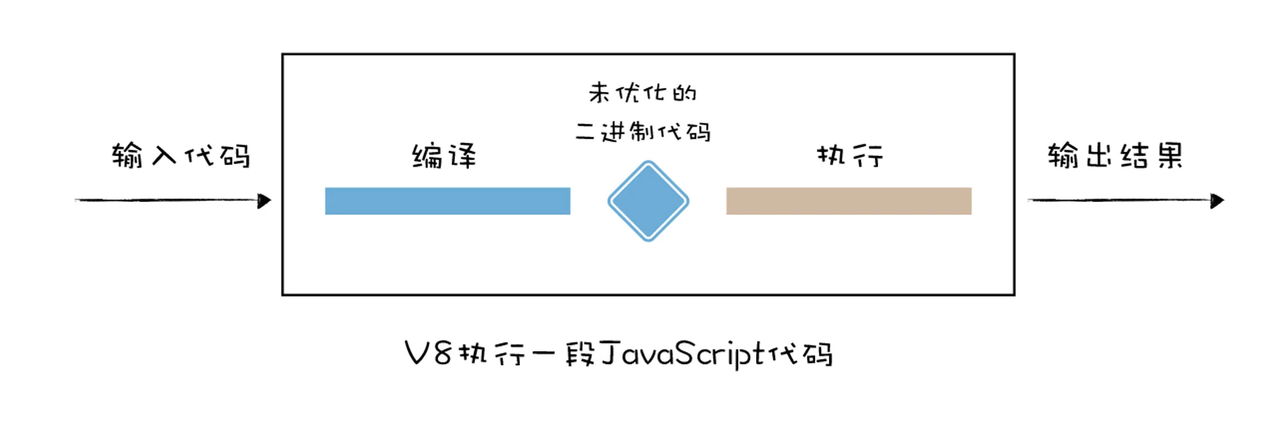
从图中可以看出,编译所消耗的时间和执行所消耗的时间是差不多的,试想一下,如果在浏览器中再次打开相同的页面,当页面中的 JavaScript 文件没有被修改,那么再次编译之后的二进制代码也会保持不变, 这意味着编译这一步白白浪费了 CPU 资源,因为之前已经编译过一次了。
这就是 Chrome 浏览器引入二进制代码缓存的原因,通过把二进制代码保存在内存中来消除冗余的编译,重用它们完成后续的调用,这样就省去了再次编译的时间。
不过随着移动设备的普及,V8 团队逐渐发现将 JavaScript 源码直接编译成二进制代码存在两个致命的问题:
- 时间问题:编译时间过久,影响代码启动速度;
- 空间问题:缓存编译后的二进制代码占用更多的内存。
这两个问题无疑会阻碍 V8 在移动设备上的普及,于是 V8 团队大规模重构代码,引入了中间的字节码。字节码的优势有如下三点:
- 解决启动问题:生成字节码的时间很短;
- 解决空间问题:字节码占用内存不多,缓存字节码会大大降低内存的使用;
- 代码架构清晰:采用字节码,可以简化程序的复杂度,使得 V8 移植到不同的 CPU 架构平台更加容易。
变量:如何存储以及如何快速查找
作用域提升:没有块级上下文,那就不设计块级作用域
存在作用域提升的原因在于,JavaScript在创造的时候用时很短,只有全局作用域和函数作用域对于编译来说比较简单。
为什么这么说呢?我们可以看一下栈就明白了,JavaScript的调用栈中只有全局上下文和函数上下文,天然就可以映射到全局作用域和函数作用域。
没有块级上下文,就不设计块级作用域。
那既然这个变量的作用域是函数级别的,那就要整个函数都能访问到,所以变量提升
“变量提升”意味着变量和函数的声明会在物理层面移动到代码的最前面,正如我们所模拟的那样。但,这并不准确。实际上变量和函数声明在代码里的位置是不会改变的,而且是在编译阶段被 JavaScript 引擎放入内存中。
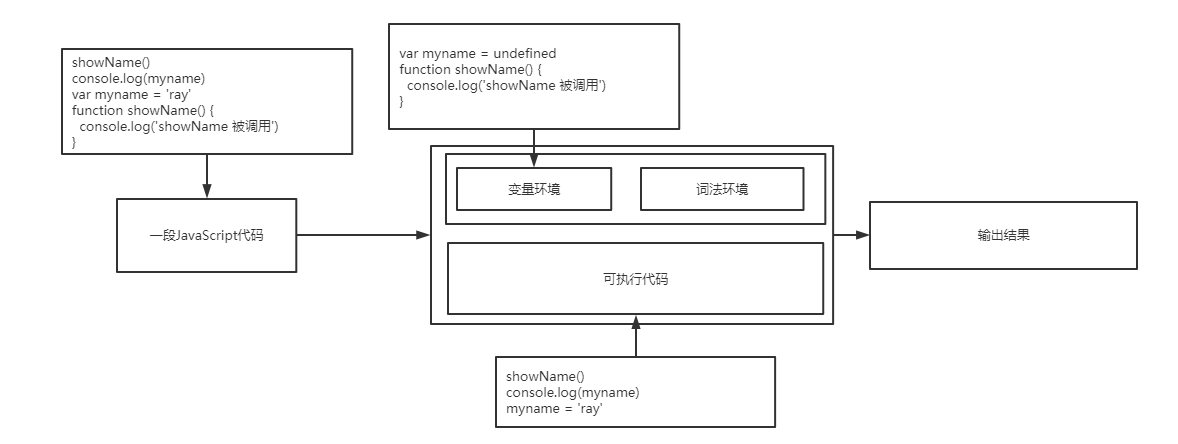
作用域:加入块级作用域,如何在当前上下文中找到变量
1 | function foo(){ |


作用域链:如果在当前上下文找不到,如何在调用栈中找到变量
1 | function bar() { |

找到变量后,如何在一个变量本身上找到一个属性
原型链:如果变量本身没有该属性,去哪里找
1 | function Parent() {} |
const a = new A(); 那么 a.__proto__ === A.prototype(Object.prototype.__proto__ === null特殊)

1 | const p1 = new Parent(); // 因为 |
思考:原型链会带来什么代码安全问题?
变量存在哪里?堆?栈?
普通类型存在调用栈中,对象,函数存在堆中??????
如果普通类型就是存在栈上,那闭包怎么实现?
This
this就是个指针,存的是变量的地址,就像一个普通对象变量中存的是对象在堆中的地址一样
垃圾回收机制
第一步,通过 GC Root 标记空间中活动对象和非活动对象‘目前 V8 采用的可访问性(reachability)算法来判断堆中的对象是否是活动对象。
第二步,回收非活动对象所占据的内存。其实就是在所有的标记完成之后,统一清理内存中所有被标记为可回收的对象。
第三步,做内存整理。一般来说,频繁回收对象后,内存中就会存在大量不连续空间,我们把这些不连续的内存空间称为内存碎片。当内存中出现了大量的内存碎片之后,如果需要分配较大的连续内存时,就有可能出现内存不足的情况,所以最后一步需要整理这些内存碎片。但这步其实是可选的,因为有的垃圾回收器不会产生内存碎片,比如接下来我们要介绍的副垃圾回收器。
目前 V8 采用了两个垃圾回收器,主垃圾回收器 -Major GC 和副垃圾回收器 -Minor GC (Scavenger)。V8 之所以使用了两个垃圾回收器,主要是受到了代际假说(The Generational Hypothesis)的影响。
- 第一个是大部分对象都是“朝生夕死”的,也就是说大部分对象在内存中存活的时间很短,比如函数内部声明的变量,或者块级作用域中的变量,当函数或者代码块执行结束时,作用域中定义的变量就会被销毁。因此这一类对象一经分配内存,很快就变得不可访问;
- 第二个是不死的对象,会活得更久,比如全局的 window、DOM、Web API 等对象。
所以,在 V8 中,会把堆分为新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放生存时间久的对象。
新生代通常只支持 1~8M 的容量,而老生代支持的容量就大很多了。对于这两块区域,V8 分别使用两个不同的垃圾回收器,以便更高效地实施垃圾回收。
副垃圾回收器 -Minor GC (Scavenger),主要负责新生代的垃圾回收。主垃圾回收器 -Major GC,主要负责老生代的垃圾回收。
思考:几种常见的内存问题
内存问题可以定义为下面这三类:
- 内存泄漏 (Memory leak),它会导致页面的性能越来越差;
- 内存膨胀 (Memory bloat),它会导致页面的性能会一直很差;
- 频繁垃圾回收,它会导致页面出现延迟或者经常暂停。
内存泄漏
本质上,内存泄漏可以定义为:当进程不再需要某些内存的时候,这些不再被需要的内存依然没有被进程回收。在 JavaScript 中,造成内存泄漏 (Memory leak) 的主要原因是不再需要 (没有作用) 的内存数据依然被其他对象引用着。
- 将数据挂载到window上
1 | function foo() { |
当执行这段代码时,由于函数体内的对象没有被 var、let、const 这些关键字声明,那么 V8 就会使用 this.temp_array 替换 temp_array。
在浏览器,默认情况下,this 是指向 window 对象的,而 window 对象是常驻内存的,所以即便 foo 函数退出了,但是 temp_array 依然被 window 对象引用了, 所以 temp_array 依然也会和 window 对象一样,会常驻内存。因为 temp_array 已经是不再被使用的对象了,但是依然被 window 对象引用了,这就造成了 temp_array 的泄漏。
- 闭包
1 | function foo(){ |
可以看到,foo 函数使用了一个局部临时变量 temp_object,temp_object 对象有三个属性,x、y,还有一个非常占用内存的 array 属性。最后 foo 函数返回了一个匿名函数,该匿名函数引用了 temp_object.x。那么当调用完 foo 函数之后,由于返回的匿名函数引用了 foo 函数中的 temp_object.x,这会造成 temp_object 无法被销毁,即便只是引用了 temp_object.x,也会造成整个 temp_object 对象依然保留在内存中。
要解决这个问题,我就需要根据实际情况,来判断闭包中返回的函数到底需要引用什么数据,不需要引用的数据就绝不引用,因为上面例子中,返回函数中只需要 temp_object.x 的值,因此我们可以这样改造下这段代码:
1 | function foo(){ |
- detached ”节点
由于 JavaScript 引用了 DOM 节点而造成的内存泄漏的问题,只有同时满足 DOM 树和 JavaScript 代码都不引用某个 DOM 节点,该节点才会被作为垃圾进行回收。 如果某个节点已从 DOM 树移除,但 JavaScript 仍然引用它,我们称此节点为“detached ”。
1 | let detachedTree; |
内存膨胀
内存膨胀和内存泄漏有一些差异,内存膨胀主要表现在程序员对内存管理的不科学,比如只需要 50M 内存就可以搞定的,有些程序员却花费了 500M 内存。
额外使用过多的内存有可能是没有充分地利用好缓存,也有可能加载了一些不必要的资源。通常表现为内存在某一段时间内快速增长,然后达到一个平稳的峰值继续运行。
频繁的垃圾回收
除了内存泄漏和内存膨胀,还有另外一类内存问题,那就是频繁使用大的临时变量,导致了新生代空间很快被装满,从而频繁触发垃圾回收。频繁的垃圾回收操作会让你感觉到页面卡顿。比如下面这段代码:
1 | function strToArray(str) { |
这段代码就会频繁创建临时变量,这种方式很快就会造成新生代内存内装满,从而频繁触发垃圾回收。为了解决频繁的垃圾回收的问题,你可以考虑将这些临时变量设置为上层作用域的变量。
函数
为什么函数在JavaScript是一等公民。
如果某个编程语言的函数,可以和这个语言的数据类型做一样的事情,我们就把这个语言中的函数称为一等公民。
- 函数作为一个对象,它有自己的属性和值,所以函数关联了基础的属性和值;
- 函数之所以成为特殊的对象,这个特殊的地方是函数可以“被调用”,所以一个函数被调用时,它还需要关联相关的执行上下文。
基于函数是一等公民的设计,使得 JavaScript 非常容易实现一些特性,比如闭包,还有函数式编程等,而其他语言要实现这些特性就显得比较困难。
延迟解析与闭包
延迟解析
在编译 JavaScript 代码的过程中,V8 并不会一次性将所有的 JavaScript 解析为中间代码,这主要是基于以下两点:
- 首先,如果一次解析和编译所有的 JavaScript 代码,过多的代码会增加编译时间,这会严重影响到首次执行 JavaScript 代码的速度,让用户感觉到卡顿。因为有时候一个页面的 JavaScript 代码都有 10 多兆,如果要将所有的代码一次性解析编译完成,那么会大大增加用户的等待时间;
- 其次,解析完成的字节码和编译之后的机器代码都会存放在内存中,如果一次性解析和编译所有 JavaScript 代码,那么这些中间代码和机器代码将会一直占用内存,特别是在手机普及的年代,内存是非常宝贵的资源。基于以上的原因,所有主流的 JavaScript 虚拟机都实现了惰性解析。所谓惰性解析是指解析器在解析的过程中,如果遇到函数声明,那么会跳过函数内部的代码,并不会为其生成 AST 和字节码,而仅仅生成顶层代码的 AST 和字节码
1 | function foo(a,b) { |
当把这段代码交给 V8 处理时,V8 会自上而下解析这段代码,在解析过程中首先会遇到 foo 函数,由于这只是一个函数声明语句,V8 在这个阶段只需要将该函数转换为函数对象,如下图所示:注意,这里只是将该函数声明转换为函数对象,但是并没有解析和编译函数内部的代码,所以也不会为 foo 函数的内部代码生成抽象语法树。

代码解析完成之后,V8 便会按照顺序自上而下执行代码,首先会先执行“a=1”和“c=4”这两个赋值表达式,接下来执行 foo 函数的调用,过程是从 foo 函数对象中取出函数代码,然后和编译顶层代码一样,V8 会先编译 foo 函数的代码,编译时同样需要先将其编译为抽象语法树和字节码,然后再解释执行。
闭包的基础:函数是一等公民
JavaScript 语言允许在函数内部定义新的函数
可以在内部函数中访问父函数中定义的变量
因为函数是一等公民,所以函数可以作为返回值
思考:延迟解析下,如何实现闭包
1 | function foo() { |
我们可以分析下上面这段代码的执行过程:
- 当调用 foo 函数时,foo 函数会将它的内部函数 inner 返回给全局变量 f;
- 然后 foo 函数执行结束,执行上下文被 V8 销毁;
- 虽然 foo 函数的执行上下文被销毁了,但是依然存活的 inner 函数引用了 foo 函数作用域中的变量 d。
所以说,如果闭包的变量如果存储在调用栈中,当函数调用结束,会被销毁
为了解决这个问题,就需要预解析器+将变量从栈复制到堆中
事件
前置知识:
进程,线程,协程
消息队列(宏任务)

微任务(解决了宏任务执行时机不可控的问题)
宏任务需要先被放到消息队列中,如果某些宏任务的执行时间过久,那么就会影响到消息队列后面的宏任务的执行,而且这个影响是不可控的,因为你无法知道前面的宏任务需要多久才能执行完成。于是 JavaScript 中又引入了微任务,微任务会在当前的任务快要执行结束时执行,利用微任务,你就能比较精准地控制你的回调函数的执行时机。
V8 会为每个宏任务维护一个微任务队列。当 V8 执行一段 JavaScript 时,会为这段代码创建一个环境对象,微任务队列就是存放在该环境对象中的。当你通过 Promise.resolve 生成一个微任务,该微任务会被 V8 自动添加进微任务队列,等整段代码快要执行结束时,该环境对象也随之被销毁,但是在销毁之前,V8 会先处理微任务队列中的微任务。
- 首先,如果当前的任务中产生了一个微任务,通过 Promise.resolve() 或者 Promise.reject() 都会触发微任务,触发的微任务不会在当前的函数中被执行,所以执行微任务时,不会导致栈的无限扩张;
- 其次,和异步调用不同,微任务依然会在当前任务执行结束之前被执行,这也就意味着在当前微任务执行结束之前,消息队列中的其他任务是不可能被执行的。
1 | function bar(){ |





1 | foo |
异步语法的前进
思考:Node中很多API都提供了同步和异步两种函数,有什么区别?
以readFile为例
1 | var fs = require('fs') |
异步读文件
比如当在 Node 的主线程上执行 readFile 的时候,主线程会将 readFile 的文件名称和回调函数,提交给文件读写线程来处理,具体过程如下所示:

文件读写线程完成了文件读取之后,会将结果和回调函数封装成新的事件,并将其添加进消息队列中。比如文件线程将读取的文件内容存放在内存中,并将 data 指针指向了该内存,然后文件读写线程会将 data 和回调函数封装成新的事件,并将其丢进消息队列中
同步读文件
不过,总有些人觉得异步读写文件操作过于复杂了,如果读取的文件体积不大或者项目瓶颈不在文件读写,那么依然使用异步调用和回调函数的模式就显得有点过度复杂了。因此 Node 还提供了一套同步读写的 API。第一段代码中的 readFileSync 就是同步实现的,同步代码非常简单,当 libuv 读取到 readFileSync 的任务后,就直接在主线程上执行读写操作,等待读写结束,直接返回读写的结果,这也是同步回调的一种应用。当然在读写过程中,消息队列中的其他任务是无法被执行的。
总结
执行过程
- V8在执行一段代码之前,会先初始化运行环境,如初始化堆栈空间,消息队列等。
- 先对整段代码进行编译,生成AST,生成AST之后:
- 对var声明的变量进行变量提升,放到全局上下文的变量环境中。
- 对let,const声明的变量,加入全局上下文的词法环境中
- 如果该变量是普通变量,直接存储在调用栈中,如果是对象或者函数,存储在堆上,并在堆的上下文中存指针,如果是函数,并不是直接生成上下文,而只是简单预解析,如果存在闭包情况,再把变量复制到堆上。
- 将整个函数当作一个宏任务丢进消息队列,开始执行代码,如果遇到函数,再解析该函数,在栈上生成上下文,并继续执行上面三步,只不过,全局上下文替换为函数上下文。
- 如果函数执行过程中遇到了宏任务的回调,放入消息队列的尾部,如果遇到了微任务的回调,放进全局上下文的微任务队列中。
- 全局上下为退出之前,会不断取出微任务中的函数执行。
- 执行完微任务之后,全局上下文销毁,从消息队列中取出下一个宏任务执行。
编码注意
- 不要轻易改动对象的结构
- 注意内存问题