IP地址与子网划分,以及与内网的区别
IP地址
两级IP
最开始的IP地址是由两个部分组成,即网络号和主机号,不同的网络号指定了该ip所属的网段,,它标志着主机或者路由器所连接到的网络,每个网络号在整个互联网中是唯一的。主机号则标志着该主机或路由器,每个主机号在所属的网络号中是唯一的。所以每个IP在互联网中都是唯一的。
这种IP地址叫做两级IP:
IP地址 = { <网络号>, <主机号> }
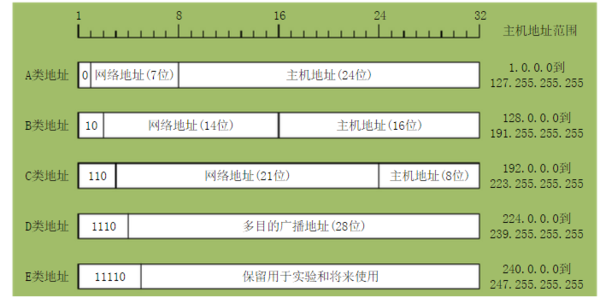
通过上图我们可以看出:
- A,B,C类地址的网络号分别为1,2,3个字节长,而网络号字段前面分别有1-3位的类别字段,其数值分别是0,10,110。
- A,B,C类地址的主机号字段分别是3个,2个,1个字节长。
- D类地址用于多播
- E类地址保留。
- A,B,C类的可以分配的地址是由网络号和主机号共同规定,大致上(全0和全1地址保留)依次是后者的两倍(差一位),但是一个A类地址中可以分配的地址数是B类地址的256倍,因为主机号的位数查了8位。
当一个单位申请到一个IP地址时,实际上时申请到了具有相同网络号的一块地址,其中各主机号由该单位自己分配,只要不重复就好。
两级IP的一些特点
- IP地址是一种分等级的地址结构,分为两级有两个好处,第一,IP地址管理机构在分配IP地址的时候只负责分配网络地址,剩下的主机号由由得到该网络号的单位自己分配。第二,路由器仅根据目的主机所连接的网络号来转发分组,这样就会大大减少路由器中需要保存的转发表的大小,以及查找路由所需要的时间。
- IP地址实际上标志的是一台主机或者路由器的一个接口(与平时我们所说的端口不同),当一台主机接到两个网络上时,他就必须同时拥有两个IP地址,而且因为是两个网络,这两个IP地址的网络号必须不同,这种主机成为多归属主机。
- 按照互联网的观点,一个网络指的是具有相同网络号的主机的集合,用转发器或者网桥(工作在链路层)连接起来的若干个局域网任然属于同一个网络,因为这些局域网拥有相同的网络号,具有不同网络号的局域网必须用路由器相连。
- 所有的IP地址都是平等的。
- 同一个局域网内部的主机或者路由器的网络号必须相同。
- 路由器总是具有两个或者以上的IP地址,且每个地址的网络号互不相同。
- 当两个路由器直接相连时,在连线两端的连个接口也可以不分配IP地址,这种叫做无编号网络。
IP地址与MAC地址
MAC地址是链路层和物理层使用的,是基于物理现实的地址,是在设备出场时就已经固定好并且永远不会改变的,而IP地址则是逻辑上的地址,是当一个设备接入某个网络时动态分配的,在不同的网络中同一个设备的IP地址是不同的。
IP地址是放在IP数据报的首部,包括源地址和目的地址,在将IP数据包交给链路层时,网络层会利用ARP协议去查找目的地址的下一跳路由的MAC地址, 然后将其封装到MAC帧中交给链路层,链路层在根据MAC地址去转发MAC帧,在整个路由转发过程中,IP地址是始终不变的,但是MAC地址会不断通过去查找当前路由中目的IP的下一跳MAC地址去替换。
三级IP地址与子网划分
刚才说了二级的IP地址,那么为什么还需要三级的IP地址呢?
- IP地址空间的利用率有时候非常低,一个A类的地址,主机号有24位,可以分配的主机数多达1000万台,但是实际上很少有哪个单位会很好的去利用。
- 两级IP地址不够灵活(注意,这里是不够灵活,而不是不够用,子网划分并不能解决IP地址不够)。有的时候,某个单位需要在一个新的地点开通一个新的网络,而在申请到一个新的网络号之前是不可能的。
为了解决上述问题,在1985年,IP地址中有增加了一个子网号字段。使得二级IP地址变为三级。
划分子网的基本思路如下:
- 一个拥有许多物理网络的单位,可以将所属的物理网络划分为多个子网,本单位以外的网络看不见整个网络是由多个子网构成的,因为这个单位的对外的网络号仍然是相同的,是同一个网络。
- 划分子网的方式是从主机号借用若干位作为子网号,同时主机号也减少了相应位数,于是二级IP地址在单位内部也从二级IP地址变成了三级IP地址。
- 从其他网络过来的数据报仍然是通过网络号来找到该单位所在的网络,进入该单位的网络后在根据子网号去找到目的子网。再由目的子网的路由器将数据包交给目的主机。
子网掩码
从IP数据包的首部是没有办法看出源主机或者目的主机是否进行了子网划分,因为IP数据包的首部没有任何字段表示是否进行了子网划分,所以我们必须另想办法,那就是子网掩码。
使用子网掩码的好处很明显,那就是就算是二级IP地址也可以使用子网掩码的方法去获取目的IP的网络号。使用了子网掩码,通过二级或三级IP地址获取网络号的方法是相同的,就是将子网掩码的每一位与目的IP做“与”运算。
那么子网掩码是怎么计算出来的呢?其实很简单,就是所有的网络号(包括网络号和子网号)所占据的位为1,剩下的为0。
加入了子网划分之后,就需要再路由转发表中多维护一列子网掩码,现在的路由表中有三列,目的网络地址,子网掩码,下一跳地址,当一个数据包过来时,逐行将子网掩码与目的IP相与,结果如果和目的网络地址相同,则匹配成功,将该列的下一跳地址封装进MAC帧中。
使用子网时的分组转发
- 从收到的数据报的首部中提取目的IP地址D。
- 首先判断是否为直接交付。对路由器直接相连的每个网络逐个进行检查:用各网络的子网掩码和D进行逐位相“与”,看结果是否和相应的网络地址匹配。如果匹配,则把分组直接交付(首先要利用匹配的这一条路由,将D转化为物理地址,再封装成MAC帧),完成任务,否则就是间接交付,执行3。
- 若路由表中有目的地址为D的特定主机路由,则把数据报直接交付给路由表中所指明的下一跳路由,否则执行4 。
- 对路由表中的每一行(目的网络地址,子网掩码,下一跳地址),用其中的子网掩码与D逐位相“与”,其结果为N,如果N和目的网络地址相匹配,则把数据包传给该行指明的下一跳地址。
- 如果路由表中有一个默认路由,则把数据报传送给默认路由,否则执行6 。
- 报告转发分组出现错误 。
子网与内网
刚才说到了,子网划分并不能解决IP地址不够的问题,那么什么技术才可以缓解IP地址不够的问题呢?这里就要说到NAT技术了。
NAT技术
NAT技术简单来说就是将内网的IP(内网的IP地址都是公网IP所不适用的,如192.168.0.1)地址与公网IP进行映射,NAT也分为很多种,如静态映射,也就是一对一映射,这种方式内部有多少私有地址就需要多少外部地址,并不节省IP资源,第二种是,动态NAT,该协议维护一个外部IP的池,,当内部IP需要发送数据到外部时,动态分配一个外部IP给他,有点类似DHCP租用IP地址。第三种则是最有效的,也叫PAT,将内网的IP+端口映射为外网的IP+端口。
有兴趣的可以去看一下NAT与内网穿透。
CIDR构造超网
上面所讲的NAT是让内网中的多个主机共享一个公网IP,有点类似于开源,而CIDR则更偏向于节流,通过打破网络地址的分类,让网络地址不局限于ABC类,可以更灵活地为不同需求地单位分配不同长度网络号的网络地址号,来减少IP地址不必要的消耗。
早在RFC1009中就指出可以再子网中使用不同长度的子网掩码,叫做变长子网掩码(Variable Length Subnet Mask, VLSM),在VLSM中基础上又研究出了无分类编址方法,正式的名字是无分类域间路由选择CIDR(Classless Inter-Domian Routing)。
CIDR最主要的两个特点:
- CIDR消除了传统的A类,B类和C类地址以及划分子网的概念,因而更加有效分配IPv4地址空间,因而能够更加有效地分配IPv4的地址空间,并且在新的IPv6使用之前容许互联网的规模持续增长。CIDR把32位的IP地址划分为前后两个部分,前面是网络前缀,用来指名网络,后面部分用来指明主机,因此CIDR使得IP地址又从三级变回了二级。
- CIDR将网络前缀都相同的连续的IP地址组成CIDR地址块。
CIDR也使用地址掩码,其作用和生成方式与子网掩码相同。
需要注意的是,所谓的CIDR不使用子网,指的是CIDR并没有在32为的地址中指明若干位为子网号。但是一旦分配到一个CIDR地址块,仍然可以在本单位内去划分子网。
由于一个CIDR地址块中有很多地址,所以在路由表中就利用CIDR地址块来查找目的网络,这种地址的聚合称为路由聚合,也可以叫做构成超网。
假设某个ISP有拥有地址块206.0.64.0/18,相当于有了64个C类网络,如果我们使用了CIDR就可以非常灵活地为不同需求的单位分配不同大小的地址块。同时如果不使用CIDR,那么与该ISP交换信息的每个路由器都需要保存该ISP的64个路由信息,但是有了CIDR的地址聚合,每个路由器只需要保存一个206.0.64.0/18就好。
当出现了地址聚合,那么就不可避免出现另一个问题,那就是有可能一个请求的目的地址可以在路由表中找到多个匹配项,这个时候我们就要使用最长前缀匹配的策略,顾名思义,就是选择匹配项目中前缀最长的路由。
使用二叉搜索查找路由
在使用了CIDR之后,由于要寻找最长前缀匹配,导致路由表的查找过程变得更加复杂,所以我们需要很好的数据结构和先进的快速查找方法。
其中最常用的就是二叉线索,在这个树结构中,IP地址中从左到右的比特值决定了从根节点逐层向下延伸的路径,而二叉线索中的各个路径就代表了路由表中存放的各个地址。
二叉线索树的构造过程也很简单,输入是当前路由表中的所有IP地址,我们找出每个IP地址的唯一前缀,所谓唯一前缀,指的是在表中所有的IP地址中,该前缀是唯一的,只要唯一前缀是匹配的,就只能找到唯一一条路由。
通过这种方式去构造二叉线索树,最大的深度是32层,也就是说必须使用32位才能在这个路由器的路由表中找到唯一一条路由。
当然,只是通过二叉线索树得到前缀匹配还不够,如果我们通过二叉线索树找到了唯一一条记录,还要去利用记录中的子网掩码和网络前缀来检验是否为目的地址的网络地址。