Blob是什么
Blob(Binary Large Object)表示二进制类型的大对象。在数据库管理系统中,将二进制数据存储为一个单一个体的集合。Blob 通常是影像、声音或多媒体文件。在 JavaScript 中 Blob 类型的对象表示不可变的类似文件对象的原始数据。
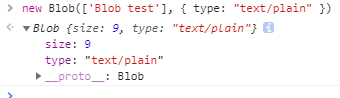
如你所见,myBlob 对象含有两个属性:size 和 type。其中 size 属性用于表示数据的大小(以字节为单位),type 是 MIME 类型的字符串。Blob 表示的不一定是 JavaScript 原生格式的数据。比如 File 接口基于 Blob,继承了 blob 的功能并将其扩展使其支持用户系统上的文件。
Blob API 简介
Blob 由一个可选的字符串 type(通常是 MIME 类型)和 blobParts 组成:
MIME(Multipurpose Internet Mail Extensions)多用途互联网邮件扩展类型,是设定某种扩展名的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动使用指定应用程序来打开。多用于指定一些客户端自定义的文件名,以及一些媒体文件打开方式。
常见的 MIME 类型有:超文本标记语言文本 .html text/html、PNG图像 .png image/png、普通文本 .txt text/plain 等。
相关的参数说明如下:
属性
前面我们已经知道 Blob 对象包含两个属性:
- size(只读):表示
Blob 对象中所包含数据的大小(以字节为单位)。 - type(只读):一个字符串,表明该
Blob 对象所包含数据的 MIME 类型。如果类型未知,则该值为空字符串。
方法
- slice([start[, end[, contentType]]]):返回一个新的 Blob 对象,包含了源 Blob 对象中指定范围内的数据。
- stream():返回一个能读取 blob 内容的
ReadableStream。 - text():返回一个 Promise 对象且包含 blob 所有内容的 UTF-8 格式的
USVString。 - arrayBuffer():返回一个 Promise 对象且包含 blob 所有内容的二进制格式的
ArrayBuffer。
这里我们需要注意的是,Blob 对象是不可改变的。我们不能直接在一个 Blob 中更改数据,但是我们可以对一个 Blob 进行分割,从其中创建新的 Blob 对象,将它们混合到一个新的 Blob 中。这种行为类似于 JavaScript 字符串:我们无法更改字符串中的字符,但可以创建新的更正后的字符串。
大文件分片上传(Vue)
客户端部分
上传切片
首先实现上传功能,上传需要做两件事
这里的File其实继承的就是Blob对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| <template>
<div>
<input type="file" @change="handleFileChange" />
<el-button @click="handleUpload">上传</el-button>
</div>
</template>
<script>
const SIZE = 10 * 1024 * 1024;
export default {
data: () => ({
container: {
file: null
},
data: []
}),
methods: {
request() {},
handleFileChange() {},
createFileChunk(file, size = SIZE) {
const fileChunkList = [];
let cur = 0;
while (cur < file.size) {
fileChunkList.push({ file: file.slice(cur, cur size) });
cur = size;
}
return fileChunkList;
},
async uploadChunks() {
const requestList = this.data
.map(({ chunk,hash }) => {
const formData = new FormData();
formData.append("chunk", chunk);
formData.append("hash", hash);
formData.append("filename", this.container.file.name);
return { formData };
})
.map(async ({ formData }) =>
this.request({
url: "http://localhost:3000",
data: formData
})
);
await Promise.all(requestList);
},
async handleUpload() {
if (!this.container.file) return;
const fileChunkList = this.createFileChunk(this.container.file);
this.data = fileChunkList.map(({ file },index) => ({
chunk: file,
hash: this.container.file.name "-" index
}));
await this.uploadChunks();
}
}
};
</script>
|
当点击上传按钮时,调用 createFileChunk 将文件切片,切片数量通过文件大小控制,这里设置 10MB,也就是说 100 MB 的文件会被分成 10 个切片
createFileChunk 内使用 while 循环和 slice 方法将切片放入 fileChunkList 数组中返回
在生成文件切片时,需要给每个切片一个标识作为 hash,这里暂时使用文件名 下标,这样后端可以知道当前切片是第几个切片,用于之后的合并切片
随后调用 uploadChunks 上传所有的文件切片,将文件切片,切片 hash,以及文件名放入 FormData 中,再调用上一步的 request 函数返回一个 proimise,最后调用 Promise.all 并发上传所有的切片
发送合并请求
这里使用整体思路中提到的第二种合并切片的方式,即前端主动通知服务端进行合并,所以前端还需要额外发请求,服务端接受到这个请求时主动合并切片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| <template>
<div>
<input type="file" @change="handleFileChange" />
<el-button @click="handleUpload">上传</el-button>
</div>
</template>
<script>
export default {
data: () => ({
container: {
file: null
},
data: []
}),
methods: {
request() {},
handleFileChange() {},
createFileChunk() {},
async uploadChunks() {
const requestList = this.data
.map(({ chunk,hash }) => {
const formData = new FormData();
formData.append("chunk", chunk);
formData.append("hash", hash);
formData.append("filename", this.container.file.name);
return { formData };
})
.map(async ({ formData }) =>
this.request({
url: "http://localhost:3000",
data: formData
})
);
await Promise.all(requestList);
await this.mergeRequest();
},
async mergeRequest() {
await this.request({
url: "http://localhost:3000/merge",
headers: {
"content-type": "application/json"
},
data: JSON.stringify({
filename: this.container.file.name
})
});
},
async handleUpload() {}
}
};
|
服务端部分
简单使用 http 模块搭建服务端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| const http = require("http");
const server = http.createServer();
server.on("request", async (req, res) => {
res.setHeader("Access-Control-Allow-Origin", "*");
res.setHeader("Access-Control-Allow-Headers", "*");
if (req.method === "OPTIONS") {
res.status = 200;
res.end();
return;
}
});
server.listen(3000, () => console.log("正在监听 3000 端口"));
|
接受切片
使用 multiparty 包处理前端传来的 FormData
在 multiparty.parse 的回调中,files 参数保存了 FormData 中文件,fields 参数保存了 FormData 中非文件的字段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| const http = require("http");
const path = require("path");
const fse = require("fs-extra");
const multiparty = require("multiparty");
const server = http.createServer();
const UPLOAD_DIR = path.resolve(__dirname, "..", "target");
server.on("request", async (req, res) => {
res.setHeader("Access-Control-Allow-Origin", "*");
res.setHeader("Access-Control-Allow-Headers", "*");
if (req.method === "OPTIONS") {
res.status = 200;
res.end();
return;
}
const multipart = new multiparty.Form();
multipart.parse(req, async (err, fields, files) => {
if (err) {
return;
}
const [chunk] = files.chunk;
const [hash] = fields.hash;
const [filename] = fields.filename;
const chunkDir = path.resolve(UPLOAD_DIR, filename);
if (!fse.existsSync(chunkDir)) {
await fse.mkdirs(chunkDir);
}
await fse.move(chunk.path, `${chunkDir}/${hash}`);
res.end("received file chunk");
});
});
server.listen(3000, () => console.log("正在监听 3000 端口"));
|
查看 multiparty 处理后的 chunk 对象,path 是存储临时文件的路径,size 是临时文件大小,在 multiparty 文档中提到可以使用 fs.rename(由于我用的是 fs-extra,它的 rename 方法 windows 平台权限问题,所以换成了 fse.move) 移动临时文件,即移动文件切片
在接受文件切片时,需要先创建存储切片的文件夹,由于前端在发送每个切片时额外携带了唯一值 hash,所以以 hash 作为文件名,将切片从临时路径移动切片文件夹中
合并切片
在接收到前端发送的合并请求后,服务端将文件夹下的所有切片进行合并
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| const http = require("http");
const path = require("path");
const fse = require("fs-extra");
const server = http.createServer();
const UPLOAD_DIR = path.resolve(__dirname, "..", "target");
const resolvePost = req =>
new Promise(resolve => {
let chunk = "";
req.on("data", data => {
chunk = data;
});
req.on("end", () => {
resolve(JSON.parse(chunk));
});
});
const pipeStream = (path, writeStream) =>
new Promise(resolve => {
const readStream = fse.createReadStream(path);
readStream.on("end", () => {
fse.unlinkSync(path);
resolve();
});
readStream.pipe(writeStream);
});
const mergeFileChunk = async (filePath, filename, size) => {
const chunkDir = path.resolve(UPLOAD_DIR, filename);
const chunkPaths = await fse.readdir(chunkDir);
chunkPaths.sort((a, b) => a.split("-")[1] - b.split("-")[1]);
await Promise.all(
chunkPaths.map((chunkPath, index) =>
pipeStream(
path.resolve(chunkDir, chunkPath),
fse.createWriteStream(filePath, {
start: index * size,
end: (index 1) * size
})
)
)
);
fse.rmdirSync(chunkDir);
};
server.on("request", async (req, res) => {
res.setHeader("Access-Control-Allow-Origin", "*");
res.setHeader("Access-Control-Allow-Headers", "*");
if (req.method === "OPTIONS") {
res.status = 200;
res.end();
return;
}
if (req.url === "/merge") {
const data = await resolvePost(req);
const { filename,size } = data;
const filePath = path.resolve(UPLOAD_DIR, `${filename}`);
await mergeFileChunk(filePath, filename);
res.end(
JSON.stringify({
code: 0,
message: "file merged success"
})
);
}
});
server.listen(3000, () => console.log("正在监听 3000 端口"));
|
由于前端在发送合并请求时会携带文件名,服务端根据文件名可以找到上一步创建的切片文件夹
接着使用 fs.createWriteStream 创建一个可写流,可写流文件名就是切片文件夹名 后缀名组合而成
随后遍历整个切片文件夹,将切片通过 fs.createReadStream 创建可读流,传输合并到目标文件中
值得注意的是每次可读流都会传输到可写流的指定位置,这是通过 createWriteStream 的第二个参数 start/end 控制的,目的是能够并发合并多个可读流到可写流中,这样即使流的顺序不同也能传输到正确的位置,所以这里还需要让前端在请求的时候多提供一个 size 参数
1
2
3
4
5
6
7
8
9
10
11
12
| async mergeRequest() {
await this.request({
url: "http://localhost:3000/merge",
headers: {
"content-type": "application/json"
},
data: JSON.stringify({
size: SIZE,
filename: this.container.file.name
})
});
},
|
其他使用场景
从互联网下载数据
我们可以使用以下方法从互联网上下载数据并将数据存储到 Blob 对象中,比如:
1
2
3
4
5
6
7
8
9
| const downloadBlob = (url, callback) => {
const xhr = new XMLHttpRequest()
xhr.open('GET', url)
xhr.responseType = 'blob'
xhr.onload = () => {
callback(xhr.response)
}
xhr.send(null)
}
|
当然除了使用 XMLHttpRequest API 之外,我们也可以使用 fetch API 来实现以流的方式获取二进制数据。这里我们来看一下如何使用 fetch API 获取线上图片并本地显示,具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
| const myImage = document.querySelector('img');
const myRequest = new Request('flowers.jpg');
fetch(myRequest)
.then(function(response) {
return response.blob();
})
.then(function(myBlob) {
let objectURL = URL.createObjectURL(myBlob);
myImage.src = objectURL;
});
|
当 fetch 请求成功的时候,我们调用 response 对象的 blob() 方法,从 response 对象中读取一个 Blob 对象,然后使用 createObjectURL() 方法创建一个 objectURL,然后把它赋值给 img 元素的 src 属性从而显示这张图片。
Blob 用作 URL
Blob 可以很容易的作为 <a>、<img> 或其他标签的 URL,多亏了 type 属性,我们也可以上传/下载 Blob 对象。下面我们将举一个 Blob 文件下载的示例,不过在看具体示例前我们得简单介绍一下 Blob URL。
1.Blob URL/Object URL
Blob URL/Object URL 是一种伪协议,允许 Blob 和 File 对象用作图像,下载二进制数据链接等的 URL 源。在浏览器中,我们使用 URL.createObjectURL 方法来创建 Blob URL,该方法接收一个 Blob 对象,并为其创建一个唯一的 URL,其形式为 blob:<origin>/<uuid>,对应的示例如下:
浏览器内部为每个通过 URL.createObjectURL 生成的 URL 存储了一个 URL → Blob 映射。因此,此类 URL 较短,但可以访问 Blob。生成的 URL 仅在当前文档打开的状态下才有效。它允许引用 <img>、<a> 中的 Blob,但如果你访问的 Blob URL 不再存在,则会从浏览器中收到 404 错误。
上述的 Blob URL 看似很不错,但实际上它也有副作用。虽然存储了 URL → Blob 的映射,但 Blob 本身仍驻留在内存中,浏览器无法释放它。映射在文档卸载时自动清除,因此 Blob 对象随后被释放。
但是,如果应用程序寿命很长,那不会很快发生。因此,如果我们创建一个 Blob URL,即使不再需要该 Blob,它也会存在内存中。
针对这个问题,我们可以调用 URL.revokeObjectURL(url) 方法,从内部映射中删除引用,从而允许删除 Blob(如果没有其他引用),并释放内存。接下来,我们来看一下 Blob 文件下载的具体示例。
2.Blob 文件下载示例
index.html
1
2
3
4
5
6
7
8
9
10
11
12
| <!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>Blob 文件下载示例</title>
</head>
<body>
<button id="downloadBtn">文件下载</button>
<script src="index.js"></script>js
</body>
</html>
|
index.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| const download = (fileName, blob) => {
const link = document.createElement("a");
link.href = URL.createObjectURL(blob);
link.download = fileName;
link.click();
link.remove();
URL.revokeObjectURL(link.href);
};
const downloadBtn = document.querySelector("#downloadBtn");
downloadBtn.addEventListener("click", (event) => {
const fileName = "blob.txt";
const myBlob = new Blob(["一文彻底掌握 Blob Web API"], { type: "text/plain" });
download(fileName, myBlob);
});
|
在示例中,我们通过调用 Blob 的构造函数来创建类型为 “text/plain” 的 Blob 对象,然后通过动态创建 a 标签来实现文件的下载。
更多用法
更多的用法可以参考 你不知道的Blob。
参考链接:
你不知道的Blob
大文件分片上传